MRS是否支持同时运行多个Flume任务?
Flume客户端可以包含多个独立的数据流,即在一个配置文件properties.properties中配置多个Source、Channel、Sink。这些组件可以链接以形成多个流。
例如在一个配置中配置两个数据流,示例如下:
server.sources = source1 source2
server.sinks = sink1 sink2
server.channels = channel1 channel2
#dataflow1
server.sources.source1.channels = channel1
server.sinks.sink1.channel = channel1
#dataflow2
server.sources.source2.channels = channel2
server.sinks.sink2.channel = channel2
如何修改FlumeClient的日志为标准输出日志?
1.登录Flume客户端安装节点。
2.进入Flume客户端安装目录,假设Flume客户端安装路径为“/opt/FlumeClient”,可以执行以下命令。
cd /opt/FlumeClient/fusioninsight-flume-1.9.0/bin
3.执行 ./flume-manage.sh stop force 命令,停止FlumeClient。
4.执行vi ../conf/log4j.properties命令,打开log4j.properties文件,修改“flume.root.logger”的取值为“${flume.log.level},console”。
5.执行 ./flume-manage.sh start force 命令,重启FlumeClient。
6.修改完成后,请检查docker配置信息是否正确。
Hadoop组件jar包位置和环境变量的位置在哪里?
- hadoopstreaming.jar位置在 /opt/share/hadoop-streaming- * 目录下。其中*由Hadoop版本决定。
- jdk环境变量:/opt/client/JDK/component_env
- Hadoop组件的环境变量位置:/opt/client/HDFS/component_env
- Hadoop客户端路径:/opt/client/HDFS/hadoop
HBase支持的压缩算法有哪些?
HBase目前支持的压缩算法有snappy、lz4和gz。
MRS是否支持通过Hive的HBase外表将数据写入到HBase?
不支持。
Hive on HBase只支持查询,不支持更改数据。
如何查看HBase日志?
1.使用root用户登录集群的Master节点。
2.执行su - omm命令,切换到omm用户。
3.执行 cd /var/log/Bigdata/hbase/ 命令,进入到“/var/log/Bigdata/hbase/”目录,即可查看HBase日志信息。
HBase表如何设置和修改数据保留期?
- 创建表时指定:
创建t_task_log表,列族f, TTL设置86400秒过期。
create 't_task_log',{NAME => 'f', TTL=>'86400'}
- 在已有表的基础上指定:
alter "t_task_log",NAME=>'data',TTL=>'86400' #设置TTL值,作用于列族data
如何修改HDFS的副本数?
搜索并修改“dfs.replication”的值,合理修改这个数值,该参数取值范围为1~16,重启HDFS实例。
如何修改HDFS主备倒换类?
当MRS 3.x版本集群使用HDFS连接NameNode报类org.apache.hadoop.hdfs.server.namenode.ha.AdaptiveFailoverProxyProvider无法找到时,是由于MRS 3.x版本集群HDFS的主备倒换类默认为该类,可通过如下方式解决。
- 方式一:添加hadoop-plugins-xxx.jar到程序的classpath或者lib目录中。
hadoop-plugins-xxx.jar包一般在HDFS客户端目录下:$HADOOP_HOME/share/hadoop/common/lib/hadoop-plugins-8.0.2-302023.jar
- 方式二:将HDFS的如下配置项修改为开源类:
dfs.client.failover.proxy.provider.hacluster=org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
DynamoDB的number在Hive表中用什么类型比较好?
Hive支持smallint。
推荐使用smallint类型。
HiveDriver是否支持对接dbcp2?
Hive driver不支持对接dbcp2数据库连接池。dbcp2数据库连接池调用isValid方法检查连接是否可用,而Hive对于这个方法的实现就是直接报错。
用户A如何查看用户B创建的Hive表?
MRS 3.x之前版本
1.登录MRS Manager,选择“系统设置 > 权限配置 > 角色管理”。
2.单击“添加角色”,输入“角色名称”和“描述”。
3.在“权限”的表格中选择“Hive > Hive Read Write Privileges”。
4.在数据库列表中单击用户B创建的表所在的数据库名称,显示用户B创建的表。
5.在用户B创建的表的“权限”列,勾选“Select”。
6.单击“确定”,返回“角色”。
7.选择“系统设置 > 用户管理”,在用户A所在的行,单击“修改”,为用户A绑定新创建的角色,单击“确定”,等待5分钟左右即可访问到用户B创建的表。
MRS 3.x及之后版本
1.登录FusionInsight Manager,选择“集群 > 服务 > Hive > 更多”,查看“启用Ranger鉴权”是否置灰。
−是,执行9。
−否,执行2-8。
2.登录FusionInsight Manager,选择“系统 > 权限 > 角色”。
3.单击“添加角色”,输入“角色名称”和“描述”。
4.在“配置资源权限”的表格中选择“待操作集群的名称 > Hive > Hive读写权限”。
5.在数据库列表中单击用户B创建的表所在的数据库名称,显示用户B创建的表。
6.在用户B创建的表的“权限”列,勾选“查询”。
7.单击“确定”,返回“角色”。
8.单击“用户”,在用户A所在行,单击“修改”,为用户A绑定新创建的角色,单击“确定”,等待5分钟左右即可访问到用户B创建的表。
9.添加Hive的Ranger访问权限策略:
a.使用Hive管理员用户登录FusionInsight Manager,选择“集群 > 服务 > Ranger”,单击“Ranger WebUI”右侧的链接进入Ranger管理界面。
b.在首页中单击“HADOOP SQL”区域的组件插件名称,例如“Hive”。
c.在“Access”页签单击“Add New Policy”,添加Hive权限控制策略。
d.在“Create Policy”页面填写如下内容:
-Policy Name:策略名称,例如:table_test_hive。
-database:填写或选择用户B创建的表所在的数据库,例如:default。
-table:填写或选择用户B创建的表,例如:test。
-column:填写并选择对应的列,例如:*。
-在“Allow Conditions”区域,单击“Select User”下选择框选择用户A,单击“Add Permissions”,勾选“select”。
-单击“Add”。
10.添加HDFS的Ranger访问权限策略:
a.使用rangeradmin用户登录FusionInsight Manager,选择“集群 > 服务 > Ranger”,单击“Ranger WebUI”右侧的链接进入Ranger管理界面。
b.在首页中单击“HDFS”区域的组件插件名称,例如“hacluster”。
c.单击“Add New Policy”,添加HDFS权限控制策略。
d.在“Create Policy”页面填写如下内容:
-Policy Name:策略名称,例如:tablehdfs_test。
-Resource Path:配置用户B创建的表所在的HDFS路径,例如:/user/hive/warehouse/ 数据库名称 /表名
-在“Allow Conditions”区域,单击“Select User”下选择框选择用户A,单击“Add Permissions”,勾选“Read”和“Execute”。
-单击“Add”。
11.在策略列表可查看策略的基本信息。等待策略生效后,用户A即可查看用户B创建的表。
Hive查询数据是否支持导出?
Hive查询数据支持导出,请参考如下语句进行导出:
insert overwrite local directory "/tmp/out/" row format delimited fields terminated by "\t" select * from table;
Hive使用beeline-e执行多条语句报错如何处理?
MRS 3.x版本Hive使用beeline执行 beeline -e "use default;show tables;" 命令报错:
Error while compiling statement: FAILED: ParseException line 1:11 missing EOF at ';' near 'default' (state=42000,code=40000)
处理方法:
- 方法一:使用beeline --entirelineascommand=false -e "use default;show tables; "命令。
- 方法二:
a. 在Hive客户端如“/opt/Bigdata/client/Hive”目录下修改component_env文件,修改
export CLIENT_HIVE_ENTIRELINEASCOMMAND=true为export CLIENT_HIVE_ENTIRELINEASCOMMAND=false。
修改component_env文件


b. 执行如下命令验证配置。
source /opt/Bigdata/client/bigdata_env
beeline -e "use default;show tables;"
添加Hive服务后,提交hivesql/hivescript作业失败如何处理?
该问题是由于提交作业的用户所在用户组绑定的MRS CommonOperations策略权限在同步到Manager中后没有Hive相关权限,处理方法如下:
1.添加Hive服务完成。
2.登录IAM服务控制台,创建一个用户组,该用户组所绑定策略和提交作业用户所在用户组权限相同。
3.将提交作业的用户添加到新用户组中。
4.刷新MRS控制台集群详情页面,“IAM用户同步”会显示“未同步”。
5.单击“IAM用户同步”右侧的“同步”。同步状态在MRS控制台页面选择“操作日志”查看当前用户是否被修改。
- 是,则可以重新提交Hive作业。
- 否,则检视上述步骤是否全部已执行完成。
-是,请联系运维人员处理
-否,请等待执行完成后再提交Hive作业。
Hue下载的Excel无法打开如何处理?
说明本案例适用于MRS 3.x之前版本。
1.以root用户登录任意一个Master节点,切换到omm用户。
su - omm
2.使用如下命令查看当前节点是否为OMS主节点。
sh ${BIGDATA_HOME}/om-0.0.1/sbin/status-oms.sh
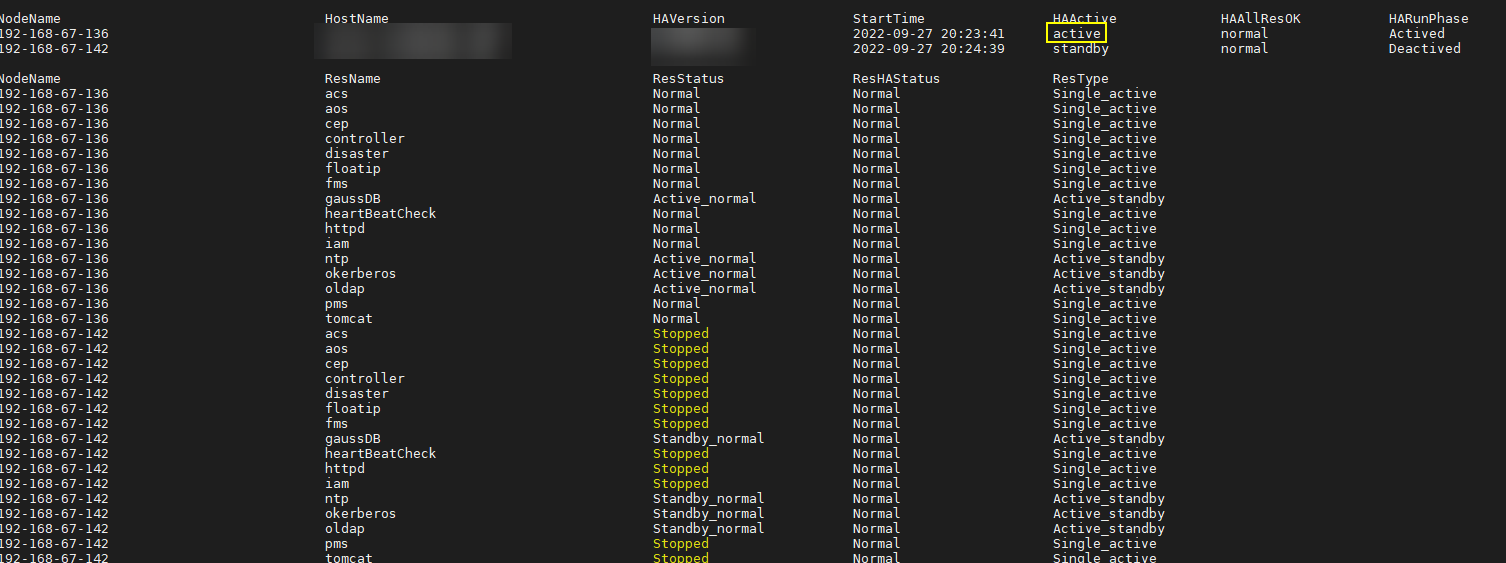
回显active即为主节点,否则请登录另一个Master节点。
oms主节点

3.进入“{BIGDATA_HOME}/Apache-httpd-*/conf”目录。
cd ${BIGDATA_HOME}/Apache-httpd-*/conf
4.打开httpd.conf文件。
vim httpd.conf
5.在文件中搜索21201,并删除文件中的如下内容。proxy_ip和proxy_port对应实际环境中的值。
ProxyHTMLEnable On
SetEnv PROXY_PREFIX=https://[proxy_ip]:[proxy_port]
ProxyHTMLURLMap (https?:\/\/[^:]*:[0-9]*.*) ${PROXY_PREFIX}/proxyRedirect=$1 RV
待删除内容

6.退出并保存修改。
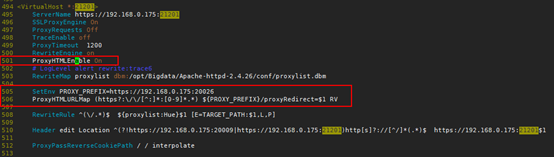
7.再次打开httpd.conf文件,搜索 proxy_hue_port ,并删除如下内容。
ProxyHTMLEnable On
SetEnv PROXY_PREFIX=https://[proxy_ip]:[proxy_port]
ProxyHTMLURLMap (https?:\/\/[^:]*:[0-9]*.*) ${PROXY_PREFIX}/proxyRedirect=$1 RV
待删除内容

8.退出并保存修改。
9.执行如下命令重启httpd。
sh ${BIGDATA_HOME}/Apache-httpd-*/setup/restarthttpd.sh
10.检查备Master节点上的httpd.conf文件是否已修改,若已修改则处理完成,若未修改,参考上述步骤进行修改备Master节点的httpd.conf文件,无需重启httpd。
11.重新下载Excel即可打开。
Hue连接hiveserver,不释放session,报错over max user connections如何处理?
适用版本:MRS 3.1.0及之前的MRS 3.x版本。
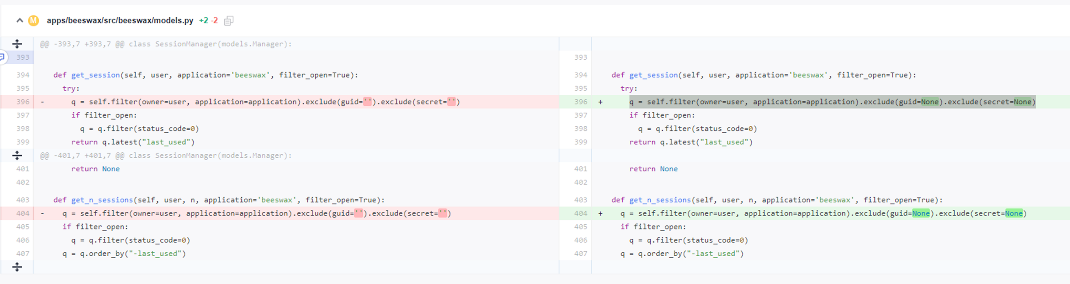
1.修改两个Hue节点的以下文件:
/opt/Bigdata/FusionInsight_Porter_8. /install/FusionInsight-Hue- /hue/apps/beeswax/src/beeswax/models.py
2.修改文件中的396和404行的值
q = self.filter(owner=user, application=application).exclude(guid='').exclude(secret='')
改为
q = self.filter(owner=user, application=application).exclude(guid=None).exclude(secret=None)
如何重置Kafka数据?
删除Kafka topic信息即重置Kafka数据,具体命令请参考:
- 删除topic:
kafka-topics.sh --delete --zookeeper ZooKeeper集群业务IP:2181/kafka --topic topicname - 查询所有topic:
kafka-topics.sh --zookeeper ZooKeeper集群业务IP:2181/kafka --list
执行删除命令后topic数据为空则此topic会立刻被删除,如果有数据则会标记删除,后续Kafka会自行进行实际删除。
Kafka目前支持的访问协议类型有哪些?
当前支持4种协议类型的访问:PLAINTEXT、SSL、SASL_PLAINTEXT、SASL_SSL。
消费Kafka Topic时报错“Not Authorized to access group XXX”如何处理?
该问题是由于集群的Ranger鉴权和集群自带的ACL鉴权冲突导致。Kafka集群使用自带的ACL进行权限访问控制,且集群的Kafka服务也开启Ranger鉴权控制时,该组件所有鉴权将由Ranger统一管理,原鉴权插件设置的权限将会失效,导致ACL权限授权未生效。可通过关闭Kafka的Ranger鉴权并重启Kafka服务来处理该问题。操作步骤如下:
1.登录FusionInsight Manager页面,选择“集群 > Kafka”。
2.在服务“概览”页面右上角单击“更多”,选择“停用Ranger鉴权”。在弹出的对话框中输入密码,单击“确定”,操作成功后单击“完成”。
3.在服务“概览”页面右上角单击“更多”,选择“重启服务”,重启Kafka服务。
Kudu支持的压缩算法有哪些?
Kudu目前支持的压缩算法有 snappy 、lz4和 zlib ,默认是 lz4 。
如何查看Kudu日志?
1.登录集群的Master节点。
2.执行su - omm命令,切换到omm用户。
3.执行 cd /var/log/Bigdata/kudu/ 命令,进入到“/var/log/Bigdata/kudu/”目录,即可查看Kudu日志信息。
新建集群Kudu服务异常如何处理?
查看Kudu服务异常日志
1.登录MRS管理控制台。
2.单击集群名称进入集群详情页面。
3.选择“组件管理 > Kudu > 实例”,找到异常实例所属的IP。
若集群详情页面没有“组件管理”页签,请先完成IAM用户同步(在集群详情页的“概览”页签,单击“IAM用户同步”右侧的“同步”进行IAM用户同步)。
4.登录异常实例IP所在节点,查看Kudu日志。
cd /var/log/Bigdata/Kudu
[root@node-master1AERu kudu]# ls
healthchecklog runninglog startlog
其中healthchecklog目录保存Kudu健康检查日志,startlog保存启动日志,runninglog保存Kudu进程运行日志。
[root@node-master1AERu logs]# pwd
/var/log/Bigdata/kudu/runninglog/master/logs
[root@node-master1AERu logs]# ls -al
kudu-master.ERROR kudu-master.INFO kudu-master.WARNING
运行日志分ERROR、INFO、WARNING三类, 每类会单独打印到相应的文件中,通过cat命令即可查看。
已知Kudu服务异常处理
日志/var/log/Bigdata/kudu/runninglog/master/logs/kudu-master.INFO出现异常打印:
"Unable to init master catalog manager: not found: Unable to initialize catalog manager: Failed to initialize sys tables async: Unable to load consensus metadata for tablet 0000000000000000000000: xxx"
如果该异常是Kudu服务初次安装时出现,可能是KuduMaster没能同时启动,造成数据不一样导致启动失败。可以通过如下步骤清空数据目录,重启Kudu服务解决。若非初次安装,清空数据目录会造成数据丢失,请先进行数据迁移再进行数据目录清空操作慎重操作。
1.查找数据目录fs_data_dir, fs_wal_dir, fs_meta_dir。
find /opt -name master.gflagfile
cat /opt/Bigdata/FusionInsight_Kudu_*/*_KuduMaster/etc/master.gflagfile | grep fs_
2.在集群详情页面选择“组件管理 > Kudu”,单击“停止服务”。
3.在所有KuduMaster、KuduTserver的节点清空Kudu 数据目录,如下命令以两个数据盘为例,具体命令请以实际情况为准。
rm -Rvf /srv/Bigdata/data1/kudu, rm -Rvf /srv/Bigdata/data2/kudu
4.在集群详情页面选择“组件管理 > Kudu”,选择“更多 > 重启服务”。
5.查看Kudu服务状态和日志。
OpenTSDB是否支持Python的接口?
OpenTSDB基于HTTP提供了访问其的RESTful接口,而RESTful接口本身具有语言无关性的特点,凡是支持HTTP请求的语言都可以对接OpenTSDB,所以OpenTSDB支持Python的接口。
Presto如何配置其他数据源?
本指导以mysql为例。
- MRS 1.x及MRS 3.x版本。
1.登录MRS管理控制台。
2.单击集群名称进入集群详情页面。
3.选择“组件管理 > Presto”。设置“参数类别”为“全部配置”,进入Presto配置界面修改参数配置。
4.搜索“connector-customize”配置。
5.按照配置项说明填写对应参数。
名称:mysql.connector.name
值:mysql
6.填写connector-customize参数名称和参数值。
| 名称 | 值 | 参数说明 |
|---|---|---|
| mysql.connection-url | jdbc:mysql://xxx.xxx.xxx.xxx:3306 | 数据库连接池 |
| mysql.connection-user | xxxx | 数据库登录用户名 |
| mysql.connection-password | xxxx | 数据库密码 |
7.重启Presto服务。
8.启用Kerberos认证的集群,执行以下命令连接本集群的Presto Server。
presto_cli.sh --krb5-config-path {krb5.conf文件路径} --krb5-principal {用户principal} --krb5-keytab-path {user.keytab文件路径} --user {presto用户名}
i.登录Presto后执行show catalogs命令,确认可以查询Presto的数据源列表mysql。

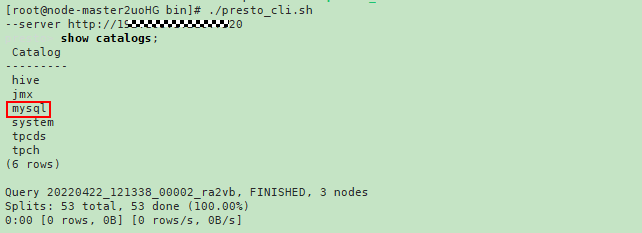
执行show schemas from mysql命令即可查询mysql数据库。
- MRS 2.x版本。
1.创建mysql.properties配置文件,内容如下:
connector.name=mysql
connection-url=jdbc:mysql://mysqlIp:3306
connection-user=用户名
connection-password=密码

说明l mysqlIp为mysql实例ip,需要和mrs网络互通 。
l 用户名和密码为登录mysql的用户名和密码。
2.分别上传配置文件到master节点(Coordinator实例所在节点)的/opt/Bigdata/MRS_Current/1_14_Coordinator/etc/catalog/和core节点的/opt/Bigdata/MRS_Current/1_14_Worker/etc/catalog/目录下(路径以集群实际路径为准),文件属组改为omm:wheel。
3.重启Presto服务。
MRS如何连接spark-shell?
1.用root用户登录集群Master节点。
2.配置环境变量。
source 客户端安装目录/bigdata_env
3.如果当前集群已启用Kerberos认证,执行以下命令认证当前用户。如果当前集群未启用Kerberos认证,则无需执行此命令。
kinit MRS集群业务用户
例如:
−“机机”用户请执行:kinit -kt user.keytab sparkuser
−“人机”用户请执行:kinit sparkuser
4.执行如下命令连接Spark组件的客户端。
spark-shell
MRS如何连接spark-beeline?
1.用root用户登录集群Master节点。
2.配置环境变量。
source 客户端安装目录/bigdata_env
3.如果当前集群已启用Kerberos认证,执行以下命令认证当前用户。如果当前集群未启用Kerberos认证,则无需执行此命令。
kinit MRS集群业务用户
例如:
−“机机”用户请执行:kinit -kt user.keytab sparkuser
−“人机”用户请执行:kinit sparkuser
4.执行如下命令连接Spark组件的客户端。
spark-beeline
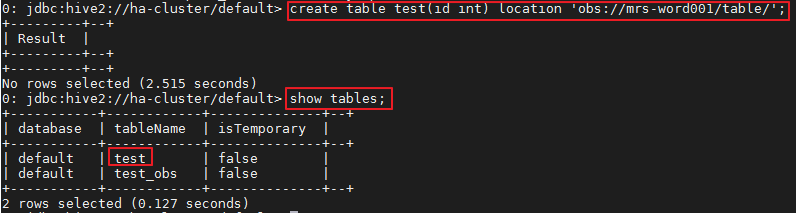
5.在spark-beeline中执行命令,例如在obs://mrs-word001/table/目录中创建表test。
create table test(id int) location 'obs://mrs-word001/table/';
6.执行如下命令查询所有表,返回结果中存在表test,即表示访问OBS成功。
show tables;
Spark验证返回已创建的表名

7.使用“Ctrl + C”退出spark beeline。
SparkJob对应的运行日志保存在哪里?
- spark job没有完成的任务日志保存在Core节点的/srv/BigData/hadoop/data1/nm/containerlogs/。
- spark job完成的任务日志保存在HDFS的/tmp/logs/ 用户名 /logs。
MRS的Storm集群提交任务时如何指定日志路径?
客户可以根据自己的需求,修改MRS的流式Core节点上的/opt/Bigdata/MRS_XXX /1_XX _Supervisor/etc/worker.xml文件,将标签filename的值设定为客户需要的路径,然后在Manager页面重启对应实例。
建议客户尽量不要修改MRS默认的日志配置,可能会造成日志系统异常。
如何检查Yarn的ResourceManager配置是否正常?
本案例适用于MRS 3.x之前版本。
登录MRS Manager页面,选择“服务管理 > Yarn > 实例”。
1.分别单击两个ResourceManager名称,选择“更多 > 同步配置”,并选择不勾选“重启配置过期的服务或实例。”。
2.单击“是”进行配置同步。
3.以root用户分别登录Master节点。
4.执行 cd /opt/Bigdata/MRS_Current/ _ _ResourceManager/etc_UPDATED/ 命令进入etc_UPDATED目录。
5.执行grep '.queues' capacity-scheduler.xml -A2找到配置的所有队列,并检查队列和Manager页面上看到的队列是否一一对应。
root-default在Manager页面隐藏,在页面看不到属于正常现象。


6.执行grep '.capacity' capacity-scheduler.xml -A2找出各队列配置的值,检查每个队列配置的值是否和Manager上看到的一致。并检查所有队列配置的值的总和是否是100。
- 是,则说明配置正常。
- 否,则说明配置异常,请执行后续步骤修复。
7.登录MRS Manager页面,选择“主机管理”。
8.查找主Master节点,主机名称前带实心五角星的Master节点即为主Master节点。
9.以root用户登录主Master节点。
10.执行su - omm切换到omm用户。
11.执行sh /opt/Bigdata/om-0.0.1/sbin/restart-controller.sh重启Controller。
请在Manager页面没有其他操作后重启Controller,重启Controller对大数据组件业务无影响。
12.重新执行步骤1~步骤7同步ResourceManager的配置并检查配置是否正常。
配置同步完成后Manager页面可能显示配置过期,该显示不影响业务,是由于组件没有加载最新的配置,待后续组件重启的时会自动加载。
如何修改Clickhouse服务的allow_drop_detached配置项?
用root用户登录Clickhouse客户端所在节点。
1.进入客户端目录,配置环境变量。
cd /opt/客户端安装目录
source bigdata_env
2.如果当前集群已启用Kerberos认证,执行以下命令认证当前用户。如果当前集群未启用Kerberos认证,则无需执行此命令。
kinit MRS集群用户
说明该用户必须具有Clickhouse管理员权限。
3.执行命令clickhouse client --host 192.168.42.90 --secure -m ,其中192.168.42.90为ClickHouseServer实例节点IP,执行结果如下:
[root@server-2110082001-0017 hadoopclient]# clickhouse client --host 192.168.42.90 --secure -m
ClickHouse client version 21.3.4.25.
Connecting to 192.168.42.90:21427.
Connected to ClickHouse server version 21.3.4 revision 54447.
4.执行命令修改allow_drop_detached的值。
例如:设置allow_drop_detached=1
set allow_drop_detached=1;
5.执行如下命令查看allow_drop_detached的值:
SELECT * FROM system.settings WHERE name = 'allow_drop_detached';


6.执行命令 q; 退出clickhouse client。
执行Spark任务报内存不足告警如何处理?
问题现象
执行Spark任务就会报内存不足告警,告警id:18022,可用内存会陡降到0。
处理步骤
在SQL脚本前设置executor参数,限制executor的核数和内存。
例如设置如下:
set hive.execution.engine=spark;
set spark.executor.cores=2;
set spark.executor.memory=4G;
set spark.executor.instances=10;
参数值大小请根据实际业务情况调整。
ClickHouse系统表日志过大,如何添加定期删除策略?
问题现象
客户使用ClickHouse,系统表产生的日志过大,一次性删除会耗费较长时间,客户可以添加定期删除策略,即添加TTL。
处理步骤
在ClickHouse客户端给TTL的系统表执行如下语句:
alter table system.表名 modify TTL event_date + INTERVAL 保留天数 day;
注意该语句只是配置运行SQL节点的系统表的TTL,若所有节点都需要配置,则需要到每个节点上都执行该语句,但不建议使用on cluster语句,避免ClickHouse一直运行下去。
上述语句建议在低峰期运行,由于数据量较大,这个操作可能会比较慢。
SparkSQL访问Hive分区表启动Job前耗时较长如何处理?
问题背景
使用SparkSql访问Hive的一个数据存放于OBS的一个分区表,但是运行速度却很慢,并且会大量调用OBS的查询接口。
SQL样例:
select a,b,c from test where b=xxx
原因分析
按照设定,任务应该只扫描b=xxx的分区,但是查看任务日志可以发现,实际上任务却扫描了所有的分区再来计算b=xxx的数据,因此任务计算的很慢。并且因为需要扫描所有文件,会有大量的OBS请求发送。
MRS默认开启基于分区统计信息的执行计划优化,相当于自动执行Analyze Table(默认开启的设置方法为spark.sql.statistics.fallBackToHdfs=true,可通过配置为false关闭)。开启后,SQL执行过程中会扫描表的分区统计信息,并作为执行计划中的代价估算,例如对于代价评估中识别的小表,会广播小表放在内存中广播到各个节点上,进行join操作,大大节省shuffle时间。 此开关对于Join场景有较大的性能优化,但是会带来OBS调用量的增加。
处理步骤
在SparkSQL中设置以下参数后再运行:
set spark.sql.statistics.fallBackToHdfs=false;
或者在启动之前使用--conf设置这个值为false:
--conf spark.sql.statistics.fallBackToHdfs=false
spark.yarn.executor.memoryOverhead设置不生效如何处理?
问题现象
Spark任务需要调整executor的overhead内存,设置了参数spark.yarn.executor.memoryOverhead=4096,但实际计算的时候依旧按照默认值1024申请资源。
原因分析
从Spark 2.3版本开始,推荐使用新参数spark.executor.memoryOverhead设置executor的overhead内存大小,如果任务两个参数都设置,则spark.yarn.executor.memoryOverhead的值不生效,以spark.executor.memoryOverhead的值为最终值。
同样的参数还有driver的overhead内存设置:spark.driver.memoryOverhead
解决步骤
使用新版本参数设置executor的overhead内存:
spark.executor.memoryOverhead=4096
连接ClickHouse服务端异常报错“code: 516”如何处理?
问题现象
使用clickhouse client命令连接ClickHouse服务端,报错:
ClickHouse exception, code: 516, host: 192.168.0.198, port: 8443; Code: 516, e.displayText() = DB::Exception: clickDevelopuser: Authentication failed: password is incorrect or there is no user with such name
原因分析
执行连接ClickHouse服务端命令时,用户名或者密码错误。
解决步骤
在执行连接ClickHouse服务端命令时,请输入正确的用户名或者密码。

