翼MapReduce(MRS)可以做什么?
MapReduce服务(MRS)为客户提供ClickHouse、Spark、Flink、Kafka、HBase等Hadoop生态的高性能大数据引擎,支持数据湖、数据仓库、BI、AI融合等能力,完全兼容开源,快速帮助客户上云构建低成本、灵活开放、安全可靠、全栈式的云原生大数据平台,满足客户业务快速增长和敏捷创新诉求。
天翼云都有哪些资源池可订购翼MapReduce(MRS)?
目前翼MapReduce(MRS)已在苏州、贵州、广州4、杭州、福州、西安2、兰州、上海4、北京2、长沙2、芜湖、石家庄、南昌、郑州、成都3、武汉2等资源池上线,您可根据实际需求选择资源较丰富的资源池或就近选择。
如您的目标资源池暂未部署翼MapReduce(MRS),请您就近选择已部署该服务的资源池,或联系客户经理反馈需求,我们会尽快进行产品部署可行性评估。
翼MapReduce(MRS)支持什么类型的分布式存储?
翼MapReduce提供目前主流的Hadoop,目前支持Hadoop 3.1.x版本,并且随社区更新版本。
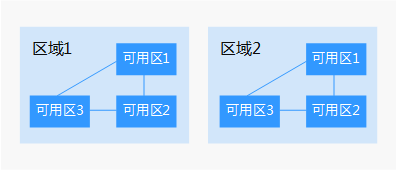
什么是区域和可用区?
通常用区域和可用区来描述数据中心的位置,用户可以在特定的区域、可用区创建云服务资源。
- 区域(Region)指物理的数据中心。每个区域完全独立,这样可以实现容错能力和稳定性。资源创建成功后不能更换区域。
- 可用区(AZ,Availability Zone)是同一区域内,电力和网络互相隔离的物理区域,一个可用区不受其他可用区故障的影响。一个区域内可以有多个可用区,不同可用区之间物理隔离,但内网互通,既保障了可用区的独立性,又提供了低价、低时延的网络连接。
下图表示区域和可用区之间的关系。
如何选择区域?
选择区域时,您需要考虑以下几个因素:
- 地理位置
一般情况下,建议就近选择靠近您或者您的目标用户的区域,可以减少网络时延,提高访问速度。但在基础设施、BGP网络品质、资源的操作与配置等方面,同一个国家各个区域间区别不大,如果您或者您的目标用户在同一个国家,可以不用考虑不同区域造成的网络时延问题。
- 资源的价格
不同区域的资源价格可能有差异。
如何选择可用区?
是否将资源放在同一可用区内,主要取决于您对容灾能力和网络时延的要求。
- 如果您的应用需要较高的容灾能力,建议您将资源部署在同一区域的不同可用区内。
- 如果您的应用要求实例之间的网络延时较低,则建议您将资源创建在同一可用区内。
如何获取区域终端节点?
当您通过API使用资源时,您必须指定其区域终端节点。请向企业管理员获取区域和终端节点信息。
翼MapReduce(MRS)集群内节点是否支持更换网段?
MRS集群内节点支持更换网段。
1.在集群详情页“默认生效子网”右侧单击“切换子网”。
2.选择当前集群所在VPC下的其他子网,即可实现可用子网IP的扩充。
新增子网不会影响当前已有节点的IP地址和子网。
翼MapReduce(MRS)集群内节点是否支持降配操作?
MRS集群内节点暂不支持降级配置规格。
如何使用自定义安全组创建MRS集群?
用户购买集群时,如果选择使用自己创建的安全组,则需要放开9022端口,或者在界面上购买集群时,安全组选择"自动创建"。
翼MapReduce(MRS)集群是否支持Hive on Spark?
- MRS 1.9.x版本集群支持Hive on Spark。
- MRS 3.x及之后版本的集群支持Hive on Spark。
- 其他版本可使用Hive on Tez替代。
不同版本的Hive之间是否可以兼容?
Hive 3.1版本与Hive 1.2版本相比不兼容内容主要如下:
- 字段类型约束:Hive 3.1不支持String转成int
- UDF不兼容:Hive 3.1版本UDF内的Date类型改为Hive内置
- 索引功能废弃
- 时间函数问题:Hive 3.1版本为UTC时间,Hive 1.2版本为当地时区时间
- 驱动不兼容:Hive 3.1和Hive 1.2版本的JDBC驱动不兼容
- Hive 3.1对ORC文件列名大小写,下划线敏感
- Hive 3.1版本列中不能有名为time的列
数据存储在OBS和HDFS有什么区别?
MRS集群处理的数据源来源于OBS或HDFS,HDFS是Hadoop分布式文件系统(Hadoop Distributed File System),OBS(Object Storage Service)即对象存储服务,是一个基于对象的海量存储服务,为客户提供海量、安全、高可靠、低成本的数据存储能力。MRS可以直接处理OBS中的数据,客户可以基于OBS服务Web界面和OBS客户端对数据进行浏览、管理和使用,同时可以通过REST API接口方式单独或集成到业务程序进行管理和访问数据。
- 数据存储在OBS:数据存储和计算分离,集群存储成本低,存储量不受限制,并且集群可以随时删除,但计算性能取决于OBS访问性能,相对HDFS有所下降,建议在数据计算不频繁场景下使用。
- 数据存储在HDFS:数据存储和计算不分离,集群成本较高,计算性能高,但存储量受磁盘空间限制,删除集群前需将数据导出保存,建议在数据计算频繁场景下使用。
Hadoop压力测试工具如何获取?
Hadoop压力测试工具社区获取地址:https://github.com/Intel-bigdata/HiBench。
翼MapReduce(MRS)服务集成的开源第三方SDK中包含的公网IP地址声明是什么?
MRS服务集成的开源组件所依赖的开源三方包中包含SDK使用示例,其中涉及“12.1.2.3”、“54.123.4.56”、“203.0.113.0”、“203.0.113.12”等公网IP均为示例IP,MRS服务进程不会主动发起与该公网IP的连接,也不会与该公网IP进行任何数据交换。
翼MapReduce(MRS)是否支持Hive on Kudu?
MRS不支持Hive on Kudu。
目前MRS只支持两种方式访问Kudu:
- 通过Impala表访问Kudu。
- 通过客户端应用程序访问操作Kudu表。
10亿级数据量场景的解决方案有哪些?
- 有数据更新、联机事务处理OLTP、复杂分析的场景,建议使用云数据库 GaussDB(for MySQL)。
- MRS的Impala + Kudu也能满足该场景,Impala + Kudu可以在join操作时,把当前所有的join表都加载到内存中来实现。
如何修改DBService的IP地址?
MRS集群内不支持修改DBService的IP地址。
翼MapReduce(MRS)集群内节点上的sudo log能否清理?
MRS集群内节点上的sudo log文件是omm用户的操作记录,以方便问题的定位,用户可以清理。
因为日志占用了一部分存储空间,建议管理员清除比较久远的操作日志释放资源空间。
1.日志文件较大,可以将此文件目录添加到“/etc/logrotate.d/syslog”中,让系统做日志老化 ,定时清理久远的日志 。
更改文件日志目录:sed -i '3 a/var/log/sudo/sudo.log' /etc/logrotate.d/syslog
2.可以根据日志个数和大小进行设置“/etc/logrotate.d/syslog”,超过设置的日志会自动删除掉。一般默认按照存档大小和个数进行老化的,可以通过size和rotate分别是日志大小限制和个数限制,默认没有时间周期的限制,如需进行周期设置可以增加daily/weekly/monthly指定清理日志的周期为每天/每周/每月。
MRS 2.1.0版本的集群对Storm日志的大小有什么限制?
MRS 2.1.0版本的集群对Storm日志有不超过20G的限制,超出后会循环删除。
因为日志是保存在系统盘上,有空间限制。若如需长期保存,则需要将日志挂载出来。
Kafka支持的访问协议类型有哪些?
Kafka支持四种协议类型的访问,分别为:PLAINTEXT、SSL、SASL_PLAINTEXT、SASL_SSL。
zstd的压缩比有什么优势?
zstd的压缩比orc好一倍,是开源的。
具体请参见https://github.com/L-Angel/compress-demo。
CarbonData不支持lzo,MRS里面有集成zstd。
MRS 3.1.0版本的集群,Spark任务支持哪些python版本?
MRS 3.1.0版本的集群,Spark任务建议使用python2.7或3.x版本。
如何让不同的业务程序分别用不同的Yarn队列?
在Manager页面上创建一个新的租户,然后将不同的集群业务用户绑定至不同的租户。
操作步骤
1.登录FusionInsight Manager,单击“租户资源”。
2.在左侧租户列表,选择父租户节点然后单击
 ,打开添加子租户的配置页面,参见下表为子租户配置属性。
,打开添加子租户的配置页面,参见下表为子租户配置属性。
子租户参数一览
| 参数名 | 描述 |
|---|---|
| 集群 | 显示上级父租户所在集群。 |
| 父租户资源 | 显示上级父租户的名称。 |
| 名称 | 指定当前租户的名称,长度为3~50个字符,可包含数字、字母或下划线(_)。 根据业务需求规划子租户的名称,不得与当前集群中已有的角色、HDFS目录或者Yarn队列重名。 |
| 租户类型 | 指定租户是否是一个叶子租户: 选择“叶子租户”:当前租户为叶子租户,不支持添加子租户。 选择“非叶子租户”:当前租户为非叶子租户,支持添加子租户,但租户层级不能超过5层。 |
| 计算资源 | 为当前租户选择动态计算资源。 选择“Yarn”时,系统自动在Yarn中以子租户名称创建任务队列。 − 如果是叶子租户,叶子租户可直接提交到任务队列中。 − 如果是非叶子租户,非叶子租户不能直接将任务提交到队列中。但是,Yarn会额外为非叶子租户增加一个任务队列(隐含),队列默认命名为“default”,用于统计当前租户剩余的资源容量,实际任务不会分配在此队列中运行。 不选择“Yarn”时,系统不会自动创建任务队列。 |
| 默认资源池容量 (%) | 配置当前租户使用的计算资源百分比,基数为父租户的资源总量。 |
| 默认资源池最大容量(%) | 配置当前租户使用的最大计算资源百分比,基数为父租户的资源总量。 |
| 存储资源 | 为当前租户选择存储资源。 选择“HDFS”时,系统将自动在HDFS父租户目录中,以子租户名称创建文件夹。 不选择“HDFS”时,系统不会分配存储资源。 |
| 文件\目录数上限 | 配置文件和目录数量配额。 |
| 存储空间配额 | 配置当前租户使用的HDFS存储空间配额。 当存储空间配额单位设置为MB时,范围为1~8796093022208,当“存储空间配额单位”设置为GB时,范围为1~8589934592。 此参数值表示租户可使用的HDFS存储空间上限,不代表一定使用了这么多空间。 如果参数值大于HDFS物理磁盘大小,实际最多使用全部的HDFS物理磁盘空间。 如果此配额大于父租户的配额,实际存储量不超过父租户配额。 |
| 存储路径 | 配置租户在HDFS中的存储目录。 系统默认将自动在父租户目录中以子租户名称创建文件夹。例如子租户“ta1s”,父目录为“/tenant/ta1”,系统默认自动配置此参数值为“/tenant/ta1/ta1s”,最终子租户的存储目录为“/tenant/ta1/ta1s”。 支持在父目录中自定义存储路径。 |
| 描述 | 配置当前租户的描述信息。 |

说明创建租户时将自动创建租户对应的角色、计算资源和存储资源。
l 新角色包含计算资源和存储资源的权限。此角色及其权限由系统自动控制,不支持通过“系统 > 权限> 角色”进行手动管理,角色名称为“租户名称_集群ID”。首个集群的集群ID默认不显示。
l 使用此租户时,请创建一个系统用户,并绑定租户对应的角色。具体操作请参见添加用户并绑定租户的角色。
l 子租户可以将当前租户的资源进一步分配。每一级别父租户下,直接子租户的资源百分比之和不能超过100%。所有一级租户的计算资源百分比之和也不能超过100%。
3.当前租户是否需要关联使用其他服务的资源?
- 是,执行步骤4。
- 否,执行步骤5。
4.单击“关联服务”,配置当前租户关联使用的其他服务资源。
a.在“服务”选择“HBase”。
b.在“关联类型”选择:
−“独占”表示该租户独占服务资源,其他租户不能再关联此服务。
−“共享”表示共享服务资源,可与其他租户共享使用此服务资源。
说明l 创建租户时,租户可以关联的服务资源只有HBase。为已有的租户关联服务时,可以关联的服务资源包含:HDFS、HBase和Yarn。
l 若为已有的租户关联服务资源:在租户列表单击目标租户,切换到“服务关联”页签,单击“关联服务”单独配置当前租户关联资源。
l 若为已有的租户取消关联服务资源:在租户列表单击目标的租户,切换到“服务关联”页签,单击“删除”,并勾选“我已阅读此信息并了解其影响。”,再单击“确定”删除与服务资源的关联。
c.单击“确定”。
d.单击“确定”,等待界面提示租户创建成功。

