如何准备MRS的数据源?
MRS既可以处理OBS中的数据,也可以处理HDFS中的数据。在使用MRS分析数据前,需要先准备数据。
1.将本地数据上传OBS。
a.登录OBS管理控制台。
b.在OBS上创建userdata并行文件系统,然后在userdata文件系统下创建program、input、output和log文件夹。
i.单击“并行文件系统 > 创建并行文件系统”,创建一个名称为userdata的文件系统。
ii.在OBS文件系统列表中单击文件系统名称userdata,选择“文件 > 新建文件夹”,分别创建program、input、output和log目录。
c.上传数据至userdata文件系统。
i.进入program文件夹,单击“上传文件”。
ii.单击“添加文件”并选择用户程序。
iii.单击“上传”。
iv.使用同样方式将用户数据文件上传至input目录。
2.将OBS数据导入至HDFS。
当“Kerberos认证”为“关闭”,且运行中的集群,可执行将OBS数据导入至HDFS的操作。
a.登录MRS管理控制台。
b.单击集群名称进入集群详情页面。
c.单击“文件管理”,选择“HDFS文件列表”。
d.进入数据存储目录,如“bd_app1”。
“bd_app1”目录仅为示例,可以是界面上的任何目录,也可以通过“新建”创建新的目录。
e.单击“导入数据”,通过单击“浏览”选择OBS和HDFS路径。
f.单击“确定”。
文件上传进度可在“文件操作记录”中查看。
MRS集群支持提交哪些形式的Spark作业?
当前在MRS页面,集群支持提交Spark、Spark Script和Spark SQL形式的Spark作业。
MRS集群的租户资源最小值改为0后,只能同时运行一个Spark任务吗?
租户资源最小值改为0后,只能同时运行一个Spark任务。
Spark作业的Client模式和Cluster模式有什么区别?
理解YARN-Client和YARN-Cluster深层次的区别之前先清楚一个概念:Application Master。
在YARN中,每个Application实例都有一个ApplicationMaster进程,它是Application启动的第一个容器。它负责和ResourceManager打交道并请求资源,获取资源之后告诉NodeManager为其启动Container。从深层次的含义讲YARN-Cluster和YARN-Client模式的区别其实就是ApplicationMaster进程的区别。
YARN-Cluster模式下,Driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行,因而YARN-Cluster模式不适合运行交互类型的作业。
YARN-Client模式下,Application Master仅仅向YARN请求Executor,Client会和请求的Container通信来调度工作,也就是说Client不能离开。
如何查看MRS作业的日志?
MRS Console页面作业管理,每一条作业支持查看日志,包含launcherJob日志和realJob日志。
- launcherJob作业的日志,一般会在stderr和stdout中打印错误日志,如下图所示:

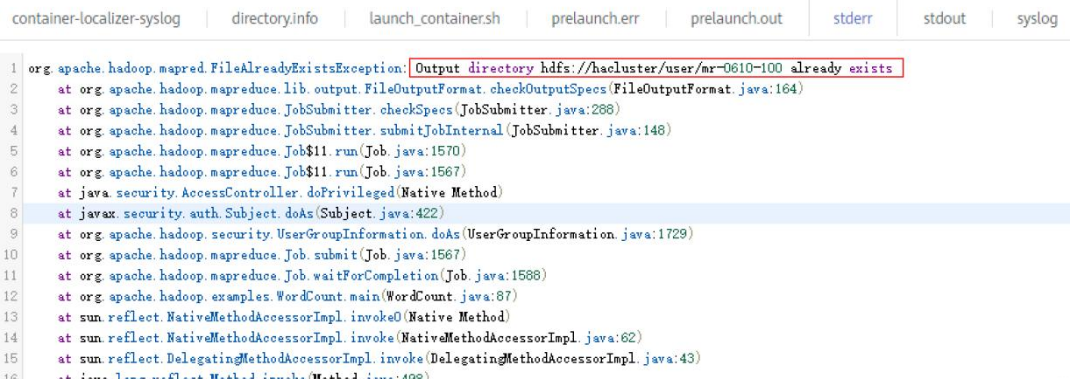
- realJob的日志,可以通过MRS Manager中Yarn服务提供的ResourceManager Web UI查看。

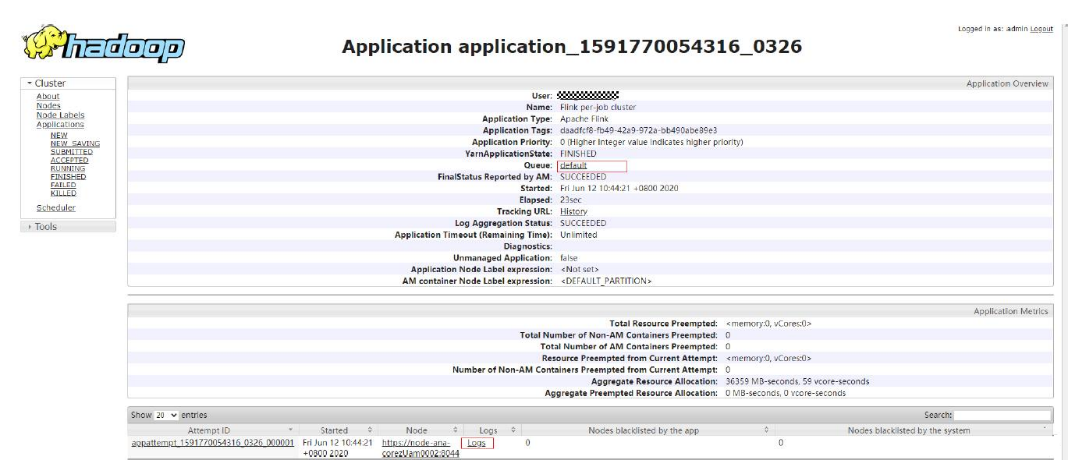
1.登录集群Master节点,可获取上述作业的日志文件 ,具体hdfs路径为“/tmp/logs/ {submit_user} /logs/ {application_id} ”。
2.提交作业后,在Yarn的WEB UI未找到对应作业的application_id,说明该作业没有提交成功,可登录集群主Master节点,查看提交作业进程日志“/var/log/executor/logs/exe.log”。
提交作业时系统提示当前用户在Manager不存在如何处理?
问题详情
安全集群使提交作业时,未进行IAM用户同步,会出现“当前用户在MRS Manager不存在,请先在IAM给予该用户足够的权限,再在概览页签进行IAM用户同步”的错误提示。
处理方式
在提交作业之前,用户需要先在集群详情页的“概览”页签,单击“IAM用户同步”右侧的“同步”进行IAM用户同步,然后再提交作业。
LauncherJob作业执行失败,报错信息为“jobPropertiesMap is null”如何处理?
问题描述
Launcher作业失败的,提示原因为:提交作业用户无“hdfs /mrs/job-properties”目录的写权限如何处理?
处理方式
该问题已在MRS 2.1.0.6的补丁中修复,也可通过在MRS Manager页面给同步的提交作业用户赋予该目录“/mrs/job-properties”的写入权限进行处理。
为什么MRS Console页面Flink作业状态与Yarn上的作业状态不一致?
为了节约存储空间,用户修改了Yarn的配置项yarn.resourcemanager.max-completed-applications,减小yarn上历史作业的记录保存个数。由于Flink是长时作业,在yarn上realJob还在运行,但launcherJob已经被删除,导致因从Yarn上查不到launcherJob,从而更新作业状态失败。该问题在2.1.0.6补丁中解决。
解决方法:终止找不到launcherJob的作业,后续提交的作业状态就会更新。
SparkStreaming]()作业运行几十个小时后失败,报OBS访问403如何处理?
当用户提交作业需要读写OBS时,提交作业程序会默认为用户添加访问OBS的临时accesskey和secretkey,但是临时accesskey和secretkey有过期时间。
如果需要运行像Flink和SparkStreaming这样的长时作业时,用户可通过“服务配置参数”选项框传入永久的accesskey和secretkey,以保证作业不会在运行过程中因密钥过期而执行失败。
ClickHouse客户端执行SQL查询时报内存不足如何处理?
问题现象
ClickHouse会限制group by使用的内存量,在使用ClickHouse客户端执行SQL查询时报如下错误:
Progress: 1.83 billion rows, 85.31 GB (68.80 million rows/s., 3.21 GB/s.) 6%Received exception from server:
Code: 241. DB::Exception: Received from localhost:9000, 127.0.0.1.
DB::Exception: Memory limit (for query) exceeded: would use 9.31 GiB (attempt to allocate chunk of 1048576 bytes), maximum: 9.31 GiB:
(while reading column hits):
解决方法
- 在执行SQL语句前,执行如下命令。注意执行前保证集群有足够内存可以设置。
SET max_memory_usage = 128000000000; #128G
- 如果没有上述大小内存可用,ClickHouse可以通过如下设置将“溢出”数据到磁盘。建议将max_memory_usage设置为max_bytes_before_external_group_by大小的两倍。
set max_bytes_before_external_group_by=20000000000; #20G
set max_memory_usage=40000000000; #40G
- 如果客户数据量大,而且是全表查询,建议按照分区进行查询或者进行升级集群core节点的规格。
Spark运行作业报错“java.io.IOException: Connection reset by peer”如何处理?
问题现象
Spark作业运行一直不结束,查看日志报错:java.io.IOException: Connection reset by peer。
解决方法
修改提交参数,加上参数“executor.memoryOverhead”。
Spark作业访问OBS报错“requestId=XXX”如何处理?
问题现象
Spark作业访问OBS报错:requestId=4971883851071737250
解决方法
登录Spark客户端节点,进入conf目录,修改配置文件“core-site.xml”中的“fs.obs.metrics.switch”参数值为“false”。
Spark作业报错“UnknownScannerExeception”如何处理?
问题现象
Spark作业运行查看日志有些WARN日志,作业运行很慢,Caused by显示:UnknownScannerExeception。
解决方法
运行Spark作业前,调整hbase.client.scanner.timeout.period参数,(例如从60秒调高到120秒)。
登录Manage界面,选择“集群 > 服务 > HBase > 配置 > 全部配置”,搜索参数“hbase.client.scanner.timeout.period”,并修改参数值为“120000”(参数单位为毫秒)。
DataArts Studio调度Spark作业偶现失败如何处理?
问题现象
DataArts Studio调度spark作业,偶现失败,重跑失败,作业报错:
Caused by: org.apache.spark.SparkException: Application application_1619511926396_2586346 finished with failed status
解决方法
使用root用户登录Spark客户端节点,调高“spark-defaults.conf”文件中“spark.driver.memory”参数值。
Flink任务运行失败,报错“java.lang.NoSuchFieldError: SECURITY_SSL_ENCRYPT_ENABLED”如何处理?
问题现象
Flink任务运行失败,报错:
Caused by: java.lang.NoSuchFieldError: SECURITY_SSL_ENCRYPT_ENABLED
解决方法
客户代码里面打包的第三方依赖包和集群包冲突,提交到MRS集群运行失败,需修改相关的依赖包,并将pom文件中的开源版本的Hadoop包和Flink包的作用域设置为provide,添加完成后重新打包运行任务。
提交的Yarn作业在界面上查看不到如何处理?
问题现象
创建完Yarn作业后,以admin用户登录Manager界面查看不到运行的作业。
解决方法
- admin用户为集群管理页面用户,检查是否有supergroup权限,通常需要使用具有supergroup权限的用户才可以查看作业。
- 使用提交作业的用户登录查看Yarn上的作业,不使用admin管理帐号查看。
如何修改现有集群的HDFS fs.defaultFS?
当前不建议在服务端修改或者新增集群内HDFS NameSpace(fs.defaultFS)。
如果只是为了客户端更好的识别,则一般可以通过修改客户端内“core-site.xml”,“hdfs-site.xml”两个文件的相关参数进行实现。
提交Flink任务时launcher-job被Yarn终止如何处理?
问题现象
管控面提交Flink任务时launcher-job因heap size不足被Yarn终止如何处理?
解决方法
调大launcher-job的heap size值。
1.使用omm用户登录主OMS节点。
2.修改“/opt/executor/webapps/executor/WEB-INF/classes/servicebroker.xml”中参数“job.launcher.resource.memory.mb”的值为“2048”。
3.使用sh /opt/executor/bin/restart-executor.sh重启executor进程。
提交Flink作业时报错slot request timeout如何处理?
问题现象
Flink作业提交时,jobmanager启动成功,但taskmanager一直是启动中直到超时,报错如下:
org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Could not allocate the required slot within slot request timeout. Please make sure that the cluster has enough resources
可能原因
1.Yarn队列中资源不足,导致创建taskmanager启动不成功。
2.用户的Jar包与环境中的Jar包冲突导致,可以通过执行wordcount程序是否成功来判断。
3.若集群为安全集群,可能是Flink的SSL证书配置错误,或者证书过期。
解决方法
1.增加队列的资源。
2.排除用户Jar包中的Flink和Hadoop依赖,依靠环境中的Jar包。
3.重新配置Flink的SSL证书。
DistCP作业导入导出数据常见问题
DistCP类型作业导入导出数据时,是否会对比数据的一致性?
不会。
DistCP类型作业导入导出数据时不会对比数据的一致性,只是对数据进行拷贝,不会修改数据。
DistCP类型作业在导出时,遇到OBS里已经存在的文件是如何处理的?
覆盖原始文件。
DistCP类型作业在导出时,遇到OBS里已经存在的文件时会覆盖原始文件。
如何通过Yarn WebUI查看Hive作业对应的SQL语句?
以业务用户登录FusionInsight Manager。
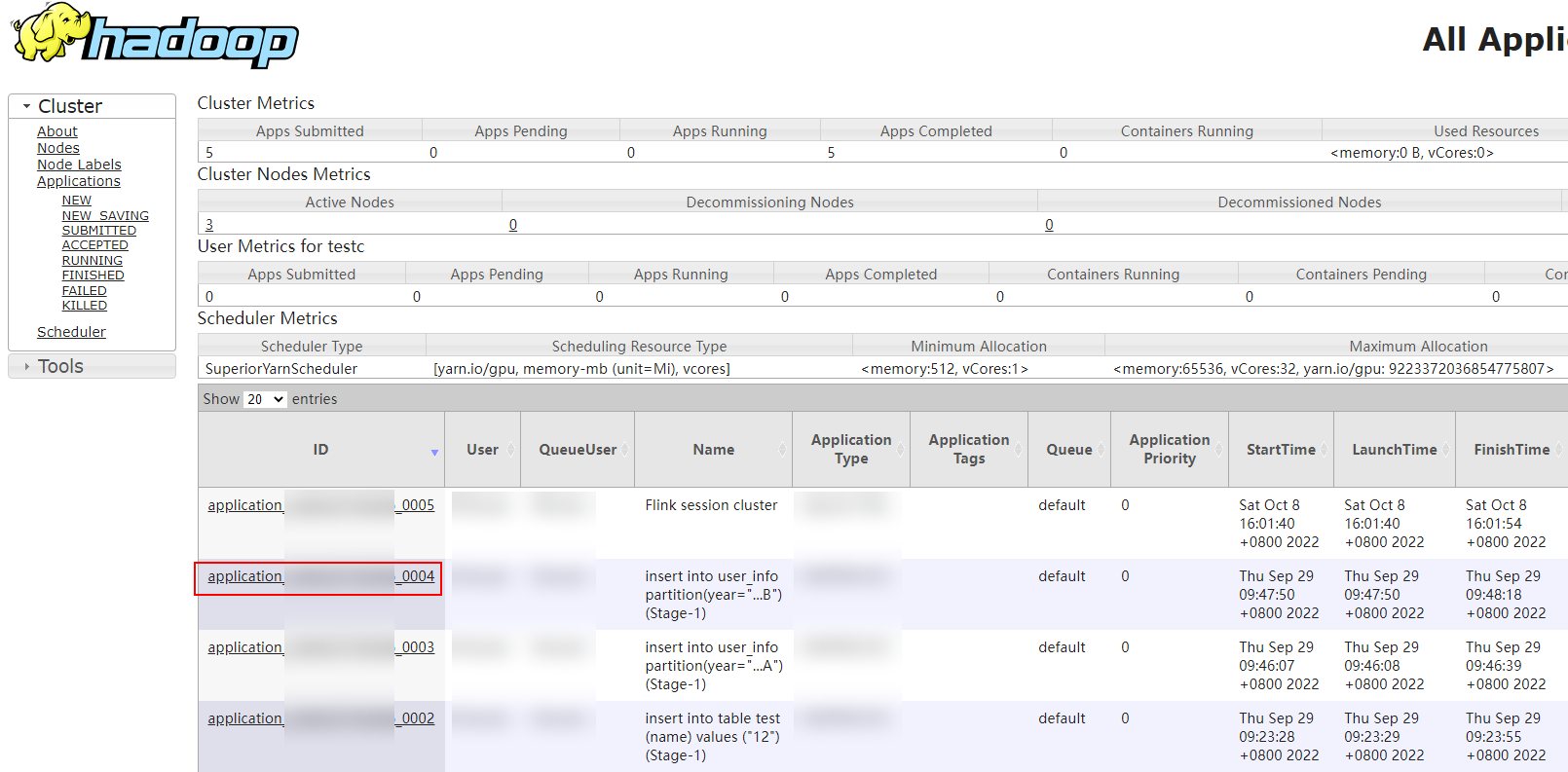
1.选择“集群 > 服务 > Yarn”,单击“ResourceManager WebUI”后的“ResourceManager(xxx,主) ”超链接,进入Yarn WebUI界面。
2.单击待查看的作业ID。

3.单击“Tracking URL”后的“ApplicationMaster”或“History”。

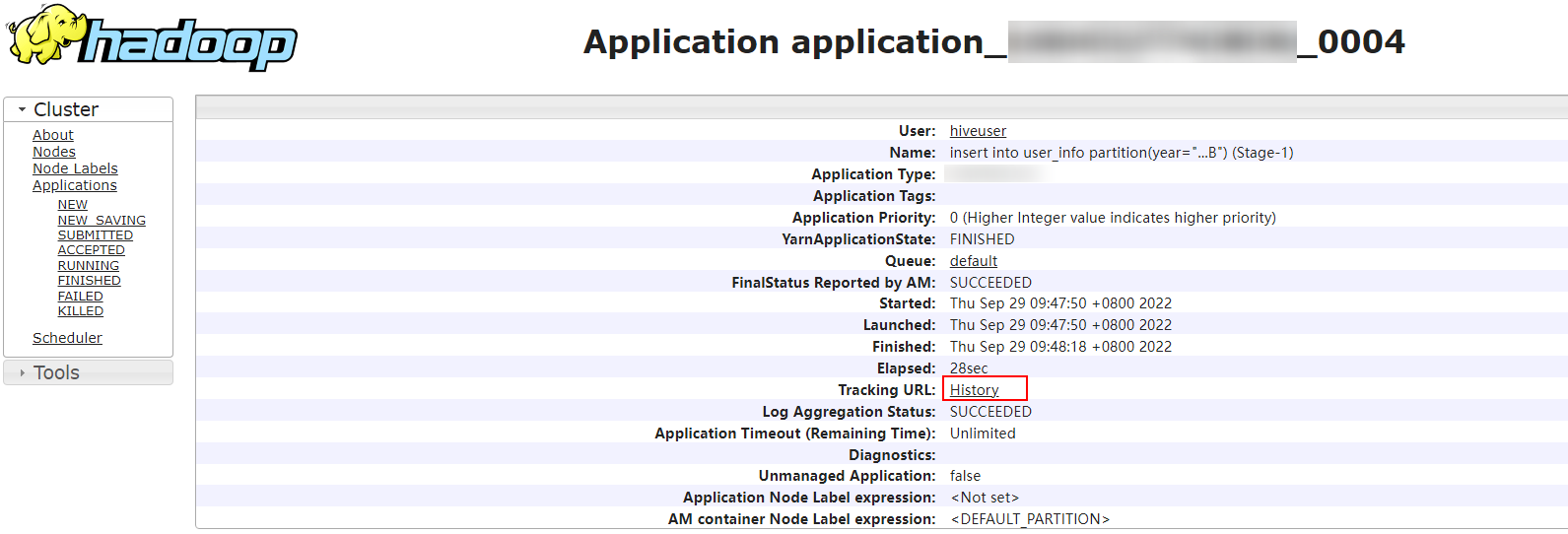
4.单击左侧导航栏的“Configuration”,在右上角搜索“hive.query.string”参数,即可查询出对应的HiveSQL。


如何查看指定Yarn任务的日志?
以root用户登录主Master节点。
1.执行如下命令初始化环境变量。
source 客户端安装目录/bigdata_env
2.如果当前集群已启用Kerberos认证,执行以下命令认证当前用户。如果当前集群未启用Kerberos认证,则无需执行此命令。
kinit MRS集群用户
3.执行以下命令获取指定任务的日志信息。
yarn logs -applicationId 待查看作业的application_ID

