简介
本文介绍了如何在天翼云上使用弹性云主机的Linux实例手工搭建Hadoop环境。Hadoop是一款由Apache基金会用Java语言开发的分布式开源软件框架,用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的能力进行高速运算和存储。Hadoop的核心部件是HDFS(Hadoop Distributed File System)和MapReduce:
- HDFS:是一个分布式文件系统,可对应用程序数据进行分布式储存和读取。
- MapReduce:是一个分布式计算框架,MapReduce的核心思想是把计算任务分配给集群内的服务器执行。通过对计算任务的拆分(Map计算和Reduce计算),再根据任务调度器(JobTracker)对任务进行分布式计算。
前提条件
- 已购买一台弹性云主机,且已为其绑定弹性公网IP。
- 弹性云主机所在安全组添加了如下表所示的安全组规则。
| 方向 | 类型 | 协议 | 端口/范围 | 源地址 |
|---|---|---|---|---|
| 入方向 | IPv4 | TCP | 8088 | 0.0.0.0/0 |
| 入方向 | IPv4 | TCP | 50070 | 0.0.0.0/0 |
实施步骤
1、安装JDK
a.登录弹性云主机。
b.执行以下命令,下载jdk软件包。
以jdk17为例,在列表中查看可用的JDK软件包版本,以jdk-17_linux-x64_bin.tar.gz安装包为例,执行以下命令。
wget https://download.oracle.com/java/17/latest/jdk-17_linux-x64_bin.tar.gz
c.解压jdk安装包到opt目录下。
tar -xvf jdk-17_linux-x64_bin.tar.gz -C /opt/
d.配置环境变量。
vim /etc/profile
e.在底部添加以下内容。
#set java environment
export JAVA_HOME=/opt/jdk-17.0.x
export PATH=$PATH:$JAVA_HOME/bin
说明“jdk-17.0.x”表示jdk安装包的具体版本,实际值需要从步骤3的返回值中获取。
例如:jdk-17.0.8
f.按“Esc”退出编辑模式。
g.执行以下命令保存并退出。
:wq
h.执行以下命令使/etc/profile里的配置生效。
source /etc/profile
i.验证安装。
java -version
回显信息如下表示jdk安装成功。
java version "17.0.8" 2023-07-18 LTS
Java(TM) SE Runtime Environment (build 17.0.8+9-LTS-211)
Java HotSpot(TM) 64-Bit Server VM (build 17.0.8+9-LTS-211, mixed mode, sharing)
2、安装Hadoop
a.执行以下命令,下载Hadoop软件包。此处以2.10.1版本为例。
wget https://mirrors.bfsu.edu.cn/apache/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz
b.解压Hadoop安装包到opt目录下。
tar -xvf hadoop-2.10.1.tar.gz -C /opt/
c.配置环境变量。
vim /etc/profile
d.在底部添加以下内容。
#set hadoop environment
export HADOOP_HOME=/opt/hadoop-2.10.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
e,按“Esc”退出编辑模式。
f.执行以下命令保存并退出。
:wq
g.执行以下命令使/etc/profile里的配置生效。
source /etc/profile
h.执行以下命令,修改配置文件yarn-env.sh和hadoop-env.sh中JAVA_HOME的路径。
echo "export JAVA_HOME=/opt/jdk-17.0.8" >> /opt/hadoop-2.10.1/etc/hadoop/yarn-env.sh
echo "export JAVA_HOME=/opt/jdk-17.0.8" >> /opt/hadoop-2.10.1/etc/hadoop/hadoop-env.sh
i.验证安装。
hadoop version
回显信息如下所示表示Hadoop安装成功。
Hadoop 2.10.1
Subversion https://github.com/apache/hadoop -r 1827467c9a56f133025f28557bfc2c562d78e816
Compiled by centos on 2020-09-14T13:17Z
Compiled with protoc 2.5.0
From source with checksum 3114edef868f1f3824e7d0f68be03650
This command was run using /opt/hadoop-2.10.1/share/hadoop/common/hadoop-common-2.10.1.jar
3、配置Hadoop
a.修改Hadoop配置文件core-site.xml。
1.执行以下命令,进入编辑页面。
vim /opt/hadoop-2.10.1/etc/hadoop/core-site.xml
2.输入i,进入编辑模式。
3.在节点内,插入如下内容。
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop-2.10.1/tmp</value>
<description>location to store temporary files</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
4.按“Esc”退出编辑模式。
5.执行以下命令保存并退出。
:wq
b.修改Hadoop配置文件hdfs-site.xml。
1.执行以下命令,进入编辑页面。
vim /opt/hadoop-2.10.1/etc/hadoop/hdfs-site.xml
2.输入i,进入编辑模式。
3.在节点内,插入如下内容。
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop-2.10.1/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop-2.10.1/tmp/dfs/data</value>
</property>
4.按“Esc”退出编辑模式。
5.执行以下命令保存并退出。
:wq
4、配置SSH免密登录
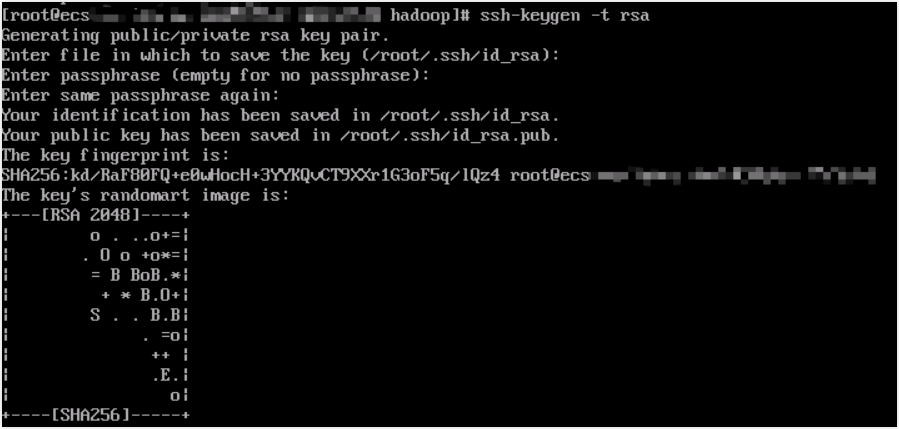
a.执行以下命令,创建公钥和私钥。
ssh-keygen -t rsa
按三次回车后回显信息如下图所示,表示创建公钥和私钥成功。
b.执行以下命令,将公钥添加到authorized_keys文件中。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
5、启动Hadoop
a.执行以下命令,初始化namenode。
hadoop namenode -format
b.依次执行以下命令,启动Hadoop。
1.start-dfs.sh
在回显信息中,依次输入yes。

2.start-yarn.sh
回显信息如下图所示。

c.执行以下命令,可查看成功启动的进程。
jps
成功启动的进程如下所示。
9138 NameNode
9876 Jps
9275 DataNode
9455 SecondaryNameNode
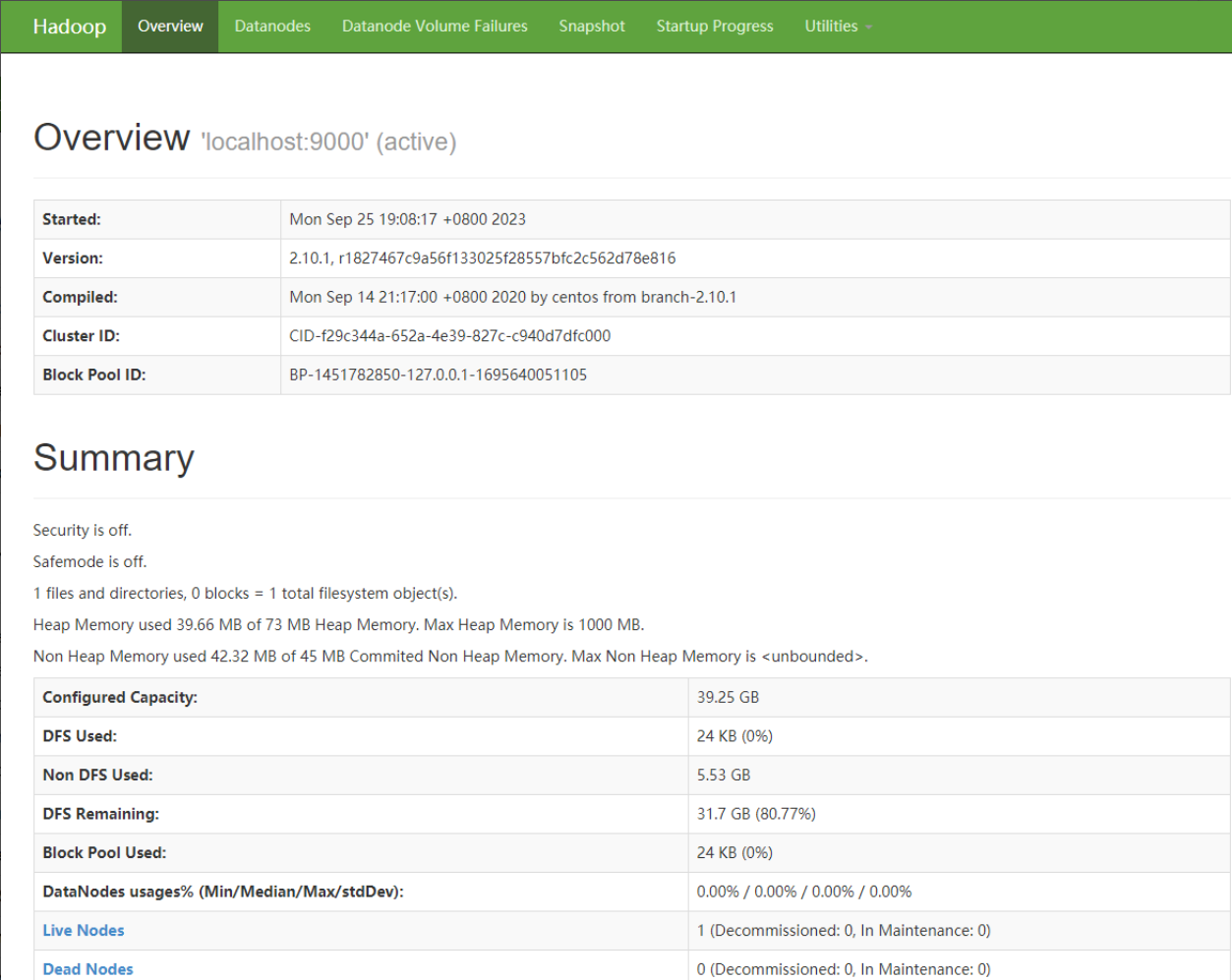
d.打开浏览器访问http://服务器IP地址:8088和http://服务器IP地址:50070。
若显示如下界面,表示Hadoop环境搭建完成。