一、工作负载状态异常定位方法
工作负载状态异常时,建议先查看Pod的事件以便于确定导致异常的初步原因,再参照下表中的内容针对性解决问题。
排查思路列表
| 事件信息 | 实例状态 | 处理措施 |
|---|---|---|
| 实例调度失败 | Pending | 请参考工作负载异常:实例调度失败 |
| 拉取镜像失败 | ImagePullBackOff | 请参考工作负载异常:实例拉取镜像失败 |
| 启动容器失败 | CreateContainerErrorCrashLoopBackOff | 请参考工作负载异常:启动容器失败 |
| 实例状态为“Evicted”,pod不断被驱逐 | Evicted | 请参考工作负载异常:实例驱逐异常(Evicted) |
| 实例挂卷失败 | Pending | 请参考工作负载异常:存储卷无法挂载或挂载超时 |
| 实例状态一直为“创建中” | Creating | 请参考工作负载异常:一直处于创建中 |
| 实例状态一直为“结束中” | Terminating | 请参考工作负载异常:结束中,解决Terminating状态的Pod删不掉的问题 |
| 实例状态为“已停止” | Stopped | 请参考工作负载异常:已停止 |
Pod事件查看方法
Pod的事件可以使用kubectl describe pod podname命令查看,或在CCE控制台,工作负载详情页面中查看。
$ kubectl describe pod prepare-58bd7bdf9-fthrp...Events:Type Reason Age From MessageWarning FailedScheduling 49s default-scheduler 0/2 nodes are available: 2 Insufficient cpu.Warning FailedScheduling 49s default-scheduler 0/2 nodes are available: 2 Insufficient cpu.
查看Pod事件


二、工作负载异常:实例调度失败
问题定位
当Pod状态为“Pending”,事件中出现“实例调度失败”的信息时,可根据具体事件信息确定具体问题原因。事件查看方法请参见工作负载状态异常定位方法。
排查思路
根据具体事件信息确定具体问题原因,如下表所示。
实例调度失败
| 事件信息 | 问题原因与解决方案 |
|---|---|
| no nodes available to schedule pods. | 集群中没有可用的节点。排查项一:集群内是否无可用节点 |
| 0/2 nodes are available: 2 Insufficient cpu.0/2 nodes are available: 2 Insufficient memory. | 节点资源(CPU、内存)不足。排查项二:节点资源(CPU、内存等)是否充足 |
| 0/2 nodes are available: 1 node(s) didn't match node selector, 1 node(s) didn't match pod affinity rules, 1 node(s) didn't match pod affinity/anti-affinity. | 节点与Pod亲和性配置互斥,没有满足Pod要求的节点。排查项三:检查工作负载的亲和性配置 |
| 0/2 nodes are available: 2 node(s) had volume node affinity conflict. | Pod挂载云硬盘存储卷与节点不在同一个可用区。排查项四:挂载的存储卷与节点是否处于同一可用区 |
| 0/1 nodes are available: 1 node(s) had taints that the pod didn't tolerate. | 节点存在污点Tanits,而Pod不能容忍这些污点,所以不可调度。排查项五:检查Pod污点容忍情况 |
| 0/7 nodes are available: 7 Insufficient ephemeral-storage. | 节点临时存储不足。排查项六:检查临时卷使用量 |
| 0/1 nodes are available: 1 everest driver not found at node | 节点上everest-csi-driver不在running状态。排查项七:检查everest插件是否工作正常。 |
| Failed to create pod sandbox: ...Create more free space in thin pool or use dm.min_free_space option to change behavior | 节点thinpool空间不足。排查项八:检查节点thinpool空间是否充足。 |
排查项一:集群内是否无可用节点
登录CCE控制台,检查节点状态是否为可用。或使用如下命令查看节点状态是否为Ready。
$ kubectl get nodeNAME STATUS ROLES AGE VERSION192.168.0.37 Ready 21d v1.19.10-r1.0.0-source-121-gb9675686c54267192.168.0.71 Ready 21d v1.19.10-r1.0.0-source-121-gb9675686c54267
如果状态都为不可用(Not Ready),则说明集群中无可用节点。
解决方案:
- 新增节点,若工作负载未设置亲和策略,pod将自动迁移至新增的可用节点,确保业务正常。
- 排查不可用节点问题并修复,排查修复方法请参见集群可用,但节点状态为“不可用”?。
- 重置不可用的节点。
排查项二:节点资源(CPU、内存等)是否充足
0/2 nodes are available: 2 Insufficient cpu. CPU不足。
0/2 nodes are available: 2 Insufficient memory. 内存不足。
当“实例资源的申请量”超过了“实例所在节点的可分配资源总量”时,节点无法满足实例所需资源要求导致调度失败。
如果节点可分配资源小于Pod的申请量,则节点无法满足实例所需资源要求导致调度失败。
解决方案:
资源不足的情况主要解决办法是扩容,建议在集群中增加节点数量。
排查项三:检查工作负载的亲和性配置
当亲和性配置出现如下互斥情况时,也会导致实例调度失败:
例如:
workload1、workload2设置了工作负载间的反亲和,如workload1部署在Node1,workload2部署在Node2。
workload3部署上线时,既希望与workload2亲和,又希望可以部署在不同节点如Node1上,这就造成了工作负载亲和与节点亲和间的互斥,导致最终工作负载部署失败。
0/2 nodes are available: 1 node(s) didn't match node selector , 1 node(s) didn't match pod affinity rules , 1 node(s) didn't match pod affinity/anti-affinity .
- node selector 表示节点亲和不满足。
- pod affinity rules 表示Pod亲和没不满足。
- pod affinity/anti-affinity 表示Pod亲和/反亲和没不满足。
解决方案:
- 在设置“工作负载间的亲和性”和“工作负载和节点的亲和性”时,需确保不要出现互斥情况,否则工作负载会部署失败。
- 若工作负载配置了节点亲和性,需确保亲和的节点标签中supportContainer设置为true,否则会导致pod无法调动到节点上,查看事件提示如下错误信息:
- No nodes are available that match all of the following predicates: MatchNode Selector, NodeNotSupportsContainer
节点标签为false时将会调度失败
排查项四:挂载的存储卷与节点是否处于同一可用区
0/2 nodes are available: 2 node(s) had volume node affinity conflict. 存储卷与节点之间存在亲和性冲突,导致无法调度。
这是因为云硬盘不能跨可用区挂载到节点。例如云硬盘存储卷在可用区1,节点在可用区2,则会导致无法调度。
CCE中创建云硬盘存储卷,默认带有亲和性设置,如下所示。
kind: PersistentVolumeapiVersion: v1metadata:name: pvc-c29bfac7-efa3-40e6-b8d6-229d8a5372ac
spec:...
nodeAffinity:required:nodeSelectorTerms:matchExpressions:key: failure-domain.beta.kubernetes.io/zoneoperator: Invalues:cn-gz1a
解决方案:
重新创建存储卷,可用区选择与节点同一分区,或重新创建工作负载,存储卷选择自动分配。
排查项五:检查Pod污点容忍情况
0/1 nodes are available: 1 node(s) had taints that the pod didn't tolerate. 是因为节点打上了污点,不允许Pod调度到节点上。
查看节点的上污点的情况。如下则说明节点上存在污点。
$ kubectl describe node 192.168.0.37Name: 192.168.0.37...Taints: key1=value1:NoSchedule...
在某些情况下,系统会自动给节点添加一个污点。当前内置的污点包括:
- node.kubernetes.io/not-ready:节点未准备好。
- node.kubernetes.io/unreachable:节点控制器访问不到节点。
- node.kubernetes.io/memory-pressure:节点存在内存压力。
- node.kubernetes.io/disk-pressure:节点存在磁盘压力,此情况表明节点上用于存储镜像的磁盘空间已满,需要清理镜像,或扩容磁盘。
- node.kubernetes.io/pid-pressure:节点的 PID 压力,此情况下您可通过修改节点进程 ID数量上限kernel.pid_max进行解决。
- node.kubernetes.io/network-unavailable:节点网络不可用。
- node.kubernetes.io/unschedulable:节点不可调度。
- node.cloudprovider.kubernetes.io/uninitialized:如果kubelet启动时指定了一个“外部”云平台驱动, 它将给当前节点添加一个污点将其标志为不可用。在cloud-controller-manager初始化这个节点后,kubelet将删除这个污点。
解决方案:
要想把Pod调度到这个节点上,有两种方法:
- 若该污点为用户自行添加,可考虑删除节点上的污点。若该污点为系统自动添加,解决相应问题后污点会自动删除。
- Pod的定义中容忍这个污点,如下所示。
apiVersion: v1kind: Podmetadata:name: nginxspec:containers:name: nginximage: nginx:alpinetolerations:key: "key1"operator: "Equal"value: "value1"effect: "NoSchedule
排查项六:检查临时卷使用量
0/7 nodes are available: 7 Insufficient ephemeral-storage. 节点临时存储不足。
检查Pod是否限制了临时卷的大小,如下所示,当应用程序需要使用的量超过节点已有容量时会导致无法调度,修改临时卷限制或扩容节点磁盘可解决此问题。
apiVersion: v1kind: Podmetadata:name: frontendspec:containers:name: app
image: images.my-company.example/app:v4
resources:
requests:
ephemeral-storage: "2Gi"
limits:
ephemeral-storage: "4Gi"
volumeMounts:name: ephemeral
mountPath: "/tmp"
volumes:name: ephemeral
emptyDir: {}
排查项七:检查everest插件是否工作正常。
0/1 nodes are available: 1 everest driver not found at node 。集群everest插件的everest-csi-driver 在节点上未正常启动。
检查kube-system命名空间下名为everest-csi-driver的守护进程,查看对应Pod是否正常启动,若未正常启动,删除该Pod,守护进程会重新拉起该Pod。
排查项八:检查节点thinpool空间是否充足。
节点在创建时会绑定一个100G的docker专用数据盘。若数据盘空间不足,将导致实例无法正常创建。
方案一
您可以执行以下命令清理未使用的Docker镜像:
docker system prune -a
说明
该命令会把暂时没有用到的Docker镜像都删除,执行命令前请确认。
方案二
或者您也可以选择扩容磁盘,具体步骤如下:
步骤 1 在EVS界面扩容数据盘。
步骤 2 登录CCE控制台,进入集群,在左侧选择“节点管理”,单击节点后的“同步云服务器”。
步骤 3 登录目标节点。
步骤 4 使用lsblk命令查看节点块设备信息。
这里存在两种情况,根据容器存储Rootfs而不同。
Overlayfs,没有单独划分thinpool,在dockersys空间下统一存储镜像相关数据。
lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTsda 8:0 0 50G 0 disk└─sda1 8:1 0 50G 0 part /sdb 8:16 0 200G 0 disk├─vgpaas-dockersys 253:0 0 90G 0 lvm /var/lib/docker # docker使用的空间└─vgpaas-kubernetes 253:1 0 10G 0 lvm /mnt/paas/kubernetes/kubelet # kubernetes使用的空间
在节点上执行如下命令,将新增的磁盘容量加到dockersys盘上。
pvresize /dev/sdblvextend -l+100%FREE -n vgpaas/dockersysresize2fs /dev/vgpaas/dockersys
Devicemapper,单独划分了thinpool存储镜像相关数据。
#lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTsda 8:0 0 50G 0 disk└─sda1 8:1 0 50G 0 part /sdb 8:16 0 200G 0 disk├─vgpaas-dockersys 253:0 0 18G 0 lvm /var/lib/docker├─vgpaas-thinpool_tmeta 253:1 0 3G 0 lvm│ └─vgpaas-thinpool 253:3 0 67G 0 lvm # thinpool空间│ ...├─vgpaas-thinpool_tdata 253:2 0 67G 0 lvm│ └─vgpaas-thinpool 253:3 0 67G 0 lvm│ ...└─vgpaas-kubernetes 253:4 0 10G 0 lvm /mnt/paas/kubernetes/kubelet
在节点上执行如下命令,将新增的磁盘容量加到thinpool盘上。
pvresize /dev/sdblvextend -l+100%FREE -n vgpaas/thinpool
在节点上执行如下命令,将新增的磁盘容量加到dockersys盘上。
pvresize /dev/sdblvextend -l+100%FREE -n vgpaas/dockersysresize2fs /dev/vgpaas/dockersys
三、工作负载异常:实例拉取镜像失败
问题定位
当Pod状态为“ImagePullBackOff”,说明实例拉取镜像失败。
排查思路
根据具体事件信息确定具体问题原因,如下表所示。
实例拉取镜像失败
| 事件信息 | 问题原因与解决方案 |
|---|---|
| Failed to pull image "xxx": rpc error: code = Unknown desc = Error response from daemon: Get xxx: denied: You may not login yet | 没有登录镜像仓库,无法拉取镜像。排查项一:kubectl创建工作负载时未指定imagePullSecret |
| Failed to pull image "nginx:v1.1": rpc error: code = Unknown desc = Error response from daemon: Get https://registry-1.docker.io/v2/: dial tcp: lookup registry-1.docker.io: no such host | 镜像地址配置有误找不到镜像导致失败。排查项二:填写的镜像地址错误(使用第三方镜像时)排查项三:使用错误的密钥(使用第三方镜像时) |
| Failed to pull image "docker.io/bitnami/nginx:1.22.0-debian-11-r3": rpc error: code = Unknown desc = Error response from daemon: Get https://registry-1.docker.io/v2/: net/ http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) |
无法连接镜像仓库,网络不通。排查项七:无法连接镜像仓库 |
| Failed create pod sandbox: rpc error: code = Unknown desc = failed to create a sandbox for pod "nginx-6dc48bf8b6-l8xrw": Error response from daemon: mkdir xxxxx: no space left on device | 磁盘空间不足。排查项四:节点磁盘空间不足 |
| Failed to pull image "xxx": rpc error: code = Unknown desc = error pulling image configuration: xxx x509: certificate signed by unknown authority | 从第三方仓库下载镜像时,第三方仓库使用了非知名或者不安全的证书.排查项五:远程镜像仓库使用非知名或不安全的证书 |
| Failed to pull image "XXX": rpc error: code = Unknown desc = context canceled | 镜像体积过大。排查项六:镜像过大导致失败 |
| Failed to pull image "docker.io/bitnami/nginx:1.22.0-debian-11-r3": rpc error: code = Unknown desc = Error response from daemon: Get https://registry-1.docker.io/v2/: net/ http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) |
排查项七:无法连接镜像仓库 |
| ERROR: toomanyrequests: Too Many Requests.或you have reached your pull rate limit, you may increase the limit by authenticating an upgrading | 由于拉取镜像次数达到上限而被限速。排查项八:拉取公共镜像达上限 |
排查思路

排查项一:kubectl创建工作负载时未指定imagePullSecret
当工作负载状态异常并显示“实例拉取镜像失败”的K8s事件时,请排查yaml文件中是否存在imagePullSecrets字段。
排查事项:
- 当Pull SWR容器镜像仓库的镜像时,name参数值需固定为default-secret。
apiVersion: extensions/v1beta1kind: Deploymentmetadata:name: nginxspec:replicas: 1selector:matchLabels:app: nginxstrategy:type: RollingUpdatetemplate:metadata:labels:app: nginxspec:containers:image: nginx
imagePullPolicy: Always
name: nginx
imagePullSecrets:name: default-secret
- Pull第三方镜像仓库的镜像时,需设置为创建的secret名称。
kubectl创建工作负载拉取第三方镜像时,需指定的imagePullSecret字段,name表示pull镜像时的secret名称。
排查项二:填写的镜像地址错误(使用第三方镜像时)
CCE支持拉取第三方镜像仓库中的镜像来创建工作负载。
在填写第三方镜像的地址时,请参照要求的格式来填写。镜像地址格式为:ip:port/path/name:version或name:version,若没标注版本号则默认版本号为latest。
- 若是私有仓库,请填写ip:port/path/name:version。
- 若是docker开源仓库,请填写name:version,例如nginx:latest。
第三方镜像

镜像地址配置有误找不到镜像导致失败,Kubernetes Event中提示如下信息:
Failed to pull image "nginx:v1.1": rpc error: code = Unknown desc = Error response from daemon: Get https://registry-1.docker.io/v2/: dial tcp: lookup registry-1.docker.io: no such host
解决方案:
可编辑yaml修改镜像地址,也可在工作负载详情页面更新升级页签单击更换镜像。
排查项三:使用错误的密钥(使用第三方镜像时)
通常第三方镜像仓库都必须经过认证(帐号密码)才可以访问,而CCE中容器拉取镜像是使用密钥认证方式,这就要求在拉取镜像前必须先创建镜像仓库的密钥。
解决方案:
若您的密钥错误将会导致镜像拉取失败,请重新获取密钥。
排查项四:节点磁盘空间不足
新建节点会给节点绑定一个100G的docker专用数据盘。若数据盘空间不足,会导致重新拉取镜像失败。
数据盘

当k8s事件中包含以下信息,表明节点上用于存储镜像的磁盘空间已满,需要清理镜像,或扩容磁盘。
Failed create pod sandbox: rpc error: code = Unknown desc = failed to create a sandbox for pod "nginx-6dc48bf8b6-l8xrw": Error response from daemon: mkdir xxxxx: no space left on device
确认节点上存储镜像的磁盘空间的命令为:lvs


清理镜像的命令为:
docker rmi –f {镜像ID}
扩容磁盘的操作步骤如下:
步骤 1 在EVS界面扩容数据盘。
步骤 2 登录CCE控制台,进入集群,在左侧选择“节点管理”,单击节点后的“同步云服务器”。
步骤 3 登录目标节点。
步骤 4 使用lsblk命令查看节点块设备信息。
这里存在两种情况,根据容器存储Rootfs而不同。
- Overlayfs,没有单独划分thinpool,在dockersys空间下统一存储镜像相关数据。
#lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTsda 8:0 0 50G 0 disk└─sda1 8:1 0 50G 0 part /sdb 8:16 0 200G 0 disk├─vgpaas-dockersys 253:0 0 90G 0 lvm /var/lib/docker # docker使用的空间└─vgpaas-kubernetes 253:1 0 10G 0 lvm /mnt/paas/kubernetes/kubelet # kubernetes使用的空间
在节点上执行如下命令,将新增的磁盘容量加到dockersys盘上。
pvresize /dev/sdblvextend -l+100%FREE -n vgpaas/dockersysresize2fs /dev/vgpaas/dockersy
- Devicemapper,单独划分了thinpool存储镜像相关数据。
#lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTsda 8:0 0 50G 0 disk└─sda1 8:1 0 50G 0 part /sdb 8:16 0 200G 0 disk├─vgpaas-dockersys 253:0 0 18G 0 lvm /var/lib/docker├─vgpaas-thinpool_tmeta 253:1 0 3G 0 lvm│ └─vgpaas-thinpool 253:3 0 67G 0 lvm # thinpool空间│ ...├─vgpaas-thinpool_tdata 253:2 0 67G 0 lvm│ └─vgpaas-thinpool 253:3 0 67G 0 lvm│ ...└─vgpaas-kubernetes 253:4 0 10G 0 lvm /mnt/paas/kubernetes/kubelet
在节点上执行如下命令,将新增的磁盘容量加到thinpool盘上。
pvresize /dev/sdblvextend -l+100%FREE -n vgpaas/thinpool
在节点上执行如下命令,将新增的磁盘容量加到dockersys盘上。
pvresize /dev/sdblvextend -l+100%FREE -n vgpaas/dockersysresize2fs /dev/vgpaas/dockersys
排查项五:远程镜像仓库使用非知名或不安全的证书
从第三方仓库下载镜像时,若第三方仓库使用了非知名或者不安全的证书,节点上会拉取镜像失败,Pod事件列表中有“实例拉取镜像失败”事件,报错原因为"x509: certificate signed by unknown authority"。
操作步骤:
步骤 1 确认报错unknown authority的第三方镜像服务器地址和端口。
从"实例拉取镜像失败"事件信息中能够直接看到报错的第三方镜像服务器地址和端口,如上图中错误信息为:
Failed to pull image "bitnami/redis-cluster:latest": rpc error: code = Unknown desc = error pulling image configuration: Get https://production.cloudflare.docker.com/registry-v2/docker/registry/v2/blobs/sha256/e8/e83853f03a2e792614e7c1e6de75d63e2d6d633b4e7c39b9d700792ee50f7b56/data?verify=1636972064-AQbl5RActnudDZV%2F3EShZwnqOe8%3D: x509: certificate signed by unknown authority
对应的第三方镜像服务器地址为 production.cloudflare.docker.com ,端口为https默认端口 443 。
步骤 2 在需要下载第三方镜像的节点上加载第三方镜像服务器的根证书。
CentOS节点执行如下命令,{server_url}:{server_port}需替换成步骤1中地址和端口,如 production.cloudflare.docker.com:443。
若节点的容器引擎为containerd,最后一步“systemctl restart docker”命令替换为"systemctl restart containerd"。
openssl s_client -showcerts -connect {server_url}:{server_port} < /dev/null | sed -ne '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/p' > /etc/pki/ca-trust/source/anchors/tmp_ca.crtupdate-ca-trustsystemctl restart docker
ubuntu节点执行如下命令。
openssl s_client -showcerts -connect {server_url}:{server_port } < /dev/null | sed -ne '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/p' > /usr/local/share/ca-certificates/tmp_ca.crtupdate-ca-trustsystemctl restart docker
排查项六:镜像过大导致失败
Pod事件列表中有“实例拉取镜像失败”事件,报错原因如下。这可能是镜像较大导致的情况。
Failed to pull image "XXX": rpc error: code = Unknown desc = context canceled
登录节点使用docker pull命令手动下拉镜像,镜像下拉成功。
问题根因:
kubernetes默认的image-pull-progress-deadline是1分钟, 如果1分钟内镜像下载没有任何进度更新, 下载动作就会取消。在节点性能较差或镜像较大时,可能出现镜像无法成功下载,负载启动失败的现象。
解决方案:
- (推荐)方法一:登录节点使用docker pull命令手动下拉镜像,确认负载的镜像拉取策略imagePullPolicy为IfNotPresent(默认策略配置)。此时创建负载会使用已拉取到本地的镜像。
- 方法二:修改kubelet配置参数。
1.15及以上集群使用如下命令:
vi /opt/cloud/cce/kubernetes/kubelet/kubelet
1.15以下集群使用如下命令:
vi /var/paas/kubernetes/kubelet/kubelet
在DAEMON_ARGS参数末尾追加配置 --image-pull-progress-deadline=30m ,30m为30分钟,可根据需求修改为合适时间。追加配置和前项配置之间由空格分开。


重启kubelet:
systemctl restart kubelet
等待片刻,确定kubelet状态为running
systemctl status kubelet


负载正常启动,镜像下拉成功。
排查项七:无法连接镜像仓库
问题现象
创建工作负载时报如下错误。
Failed to pull image "docker.io/bitnami/nginx:1.22.0-debian-11-r3": rpc error: code = Unknown desc = Error response from daemon: Get https://registry-1.docker.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
问题原因
无法连接镜像仓库,网络不通。SWR仅支持直接拉Docker官方的镜像,其他仓库的镜像需要连接。
解决方案:
- 给需要下载镜像的节点绑定公网IP。
- 先将镜像上传到SWR,然后从SWR拉取镜像。
排查项八:拉取公共镜像达上限
问题现象
创建工作负载时报如下错误。
ERROR: toomanyrequests: Too Many Requests.
或
you have reached your pull rate limit, you may increase the limit by authenticating an upgrading: https://www.docker.com/increase-rate-limits.
问题原因
DockerHub对用户拉取容器镜像请求设定了上限,详情请参见Understanding Docker Hub Rate Limiting。
解决方案:
将常用的镜像上传到SWR,然后从SWR拉取镜像。
四、工作负载异常:启动容器失败
问题定位
工作负载详情中,若事件中提示“启动容器失败”,请按照如下方式来初步排查原因:
步骤 1 登录异常工作负载所在的节点。
步骤 2 查看工作负载实例非正常退出的容器ID。
docker ps -a | grep $podName
步骤 3 查看退出容器的错误日志。
docker logs $containerID
根据日志提示修复工作负载本身的问题。
步骤 4 查看操作系统的错误日志。
cat /var/log/messages | grep
根据日志判断是否触发了系统OOM。
排查思路
根据具体事件信息确定具体问题原因,如下表所示。
容器启动失败
| 日志或事件信息 | 问题原因与解决方案 |
|---|---|
| 日志中存在exit(0) | 容器中无进程。请调试容器是否能正常运行。排查项一:(退出码:0)容器中无持续运行的进程 |
| 事件信息:Liveness probe failed: Get http…日志中存在exit(137) | 健康检查执行失败。排查项二:(退出码:137)健康检查执行失败 |
| 事件信息:Thin Pool has 15991 free data blocks which is less than minimum required 16383 free data blocks. Create more free space in thin pool or use dm.min_free_space option to change behavior |
磁盘空间不足,需要清理磁盘空间。排查项三:容器所在磁盘空间不足 |
| 日志中存在OOM字眼 | 内存不足。排查项四:达到容器资源上限排查项五:工作负载的容器规格设置较小导致 |
| Address already in use | Pod中容器端口冲突排查项六:同一pod中container端口冲突导致 |
出上述可能原因外,还可能存在如下原因,请根据顺序排查。
- 排查项七:容器启动命令配置有误导致
- 排查项九:用户自身业务BUG
- 在ARM架构的节点上创建工作负载时未使用正确的镜像版本,使用正确的镜像版本即可解决该问题。
排查思路

排查项一:(退出码:0)容器中无持续运行的进程
步骤 1 登录异常工作负载所在的节点。
步骤 2 查看容器状态。
docker ps -a | grep $podName
如下图所示:


当容器中无持续运行的进程时,会出现exit(0)的状态码,此时说明容器中无进程。
排查项二:(退出码:137)健康检查执行失败
工作负载配置的健康检查会定时检查业务,异常情况下pod会报实例不健康的事件且pod一直重启失败。
工作负载若配置liveness型(工作负载存活探针)健康检查,当健康检查失败次数超过阈值时,会重启实例中的容器。在工作负载详情页面查看事件,若K8s事件中出现“Liveness probe failed: Get http…”时,表示健康检查失败。
解决方案:
请核查“工作负载详情>更新升级>高级配置>健康检查”中的信息,排查健康检查策略是否合理或业务是否已异常。
排查项三:容器所在磁盘空间不足
如下磁盘为创建节点时选择的docker专用盘分出来的thinpool盘,以root用户执行lvs命令可以查看当前磁盘的使用量。
Thin Pool has 15991 free data blocks which is less than minimum required 16383 free data blocks. Create more free space in thin pool or use dm.min_free_space option to change behavior
解决方案:
方案一
您可以执行以下命令清理未使用的垃圾镜像:
docker system prune -a

说明
该命令会把暂时没有用到的Docker镜像都删除,执行命令前请确认。
方案二
或者您也可以选择扩容磁盘,具体步骤如下:
步骤 1 在EVS界面扩容数据盘。
步骤 2 登录CCE控制台,进入集群,在左侧选择“节点管理”,单击节点后的“同步云服务器”。
步骤 3 登录目标节点。
步骤 4 使用lsblk命令查看节点块设备信息。
这里存在两种情况,根据容器存储Rootfs而不同。
- Overlayfs,没有单独划分thinpool,在dockersys空间下统一存储镜像相关数据。
#lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTsda 8:0 0 50G 0 disk└─sda1 8:1 0 50G 0 part /sdb 8:16 0 200G 0 disk├─vgpaas-dockersys 253:0 0 90G 0 lvm /var/lib/docker # docker使用的空间└─vgpaas-kubernetes 253:1 0 10G 0 lvm /mnt/paas/kubernetes/kubelet # kubernetes使用的空间
在节点上执行如下命令,将新增的磁盘容量加到dockersys盘上。
pvresize /dev/sdblvextend -l+100%FREE -n vgpaas/dockersysresize2fs /dev/vgpaas/dockersys
- Devicemapper,单独划分了thinpool存储镜像相关数据。
#lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTsda 8:0 0 50G 0 disk└─sda1 8:1 0 50G 0 part /sdb 8:16 0 200G 0 disk├─vgpaas-dockersys 253:0 0 18G 0 lvm /var/lib/docker├─vgpaas-thinpool_tmeta 253:1 0 3G 0 lvm│ └─vgpaas-thinpool 253:3 0 67G 0 lvm # thinpool空间│ ...├─vgpaas-thinpool_tdata 253:2 0 67G 0 lvm│ └─vgpaas-thinpool 253:3 0 67G 0 lvm│ ...└─vgpaas-kubernetes 253:4 0 10G 0 lvm /mnt/paas/kubernetes/kubelet
在节点上执行如下命令,将新增的磁盘容量加到thinpool盘上。
pvresize /dev/sdblvextend -l+100%FREE -n vgpaas/thinpool
在节点上执行如下命令,将新增的磁盘容量加到dockersys盘上。
pvresize /dev/sdblvextend -l+100%FREE -n vgpaas/dockersysresize2fs /dev/vgpaas/dockersys
排查项四:达到容器资源上限
事件详情中有OOM字样。并且,在日志中也会有记录:
cat /var/log/messages | grep 96feb0a425d6 | grep oom


创建工作负载时,设置的限制资源若小于实际所需资源,会触发系统OOM,并导致容器异常退出。
排查项五:工作负载的容器规格设置较小导致
工作负载的容器规格设置较小导致,若创建工作负载时,设置的限制资源少于实际所需资源,会导致启动容器失败。
排查项六:同一pod中container端口冲突导致
步骤 1 登录异常工作负载所在的节点。
步骤 2 查看工作负载实例非正常退出的容器ID。
docker ps -a | grep $podName
步骤 3 查看退出容器的错误日志。
docker logs $containerID
根据日志提示修复工作负载本身的问题。如下图所示,即同一Pod中的container端口冲突导致容器启动失败。
container冲突导致容器启动失败
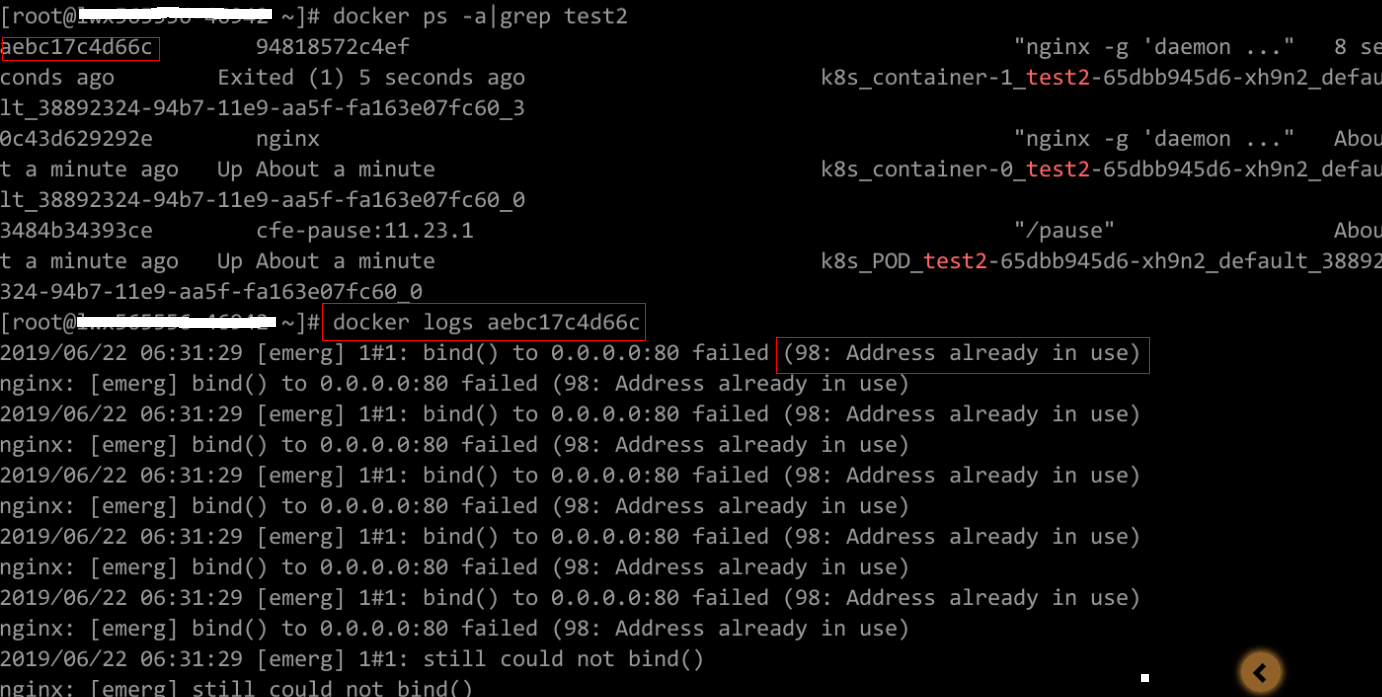
解决方案:
重新创建工作负载,并配置正确的端口,确保端口不冲突。
排查项七:容器启动命令配置有误导致
错误信息如下图所示:

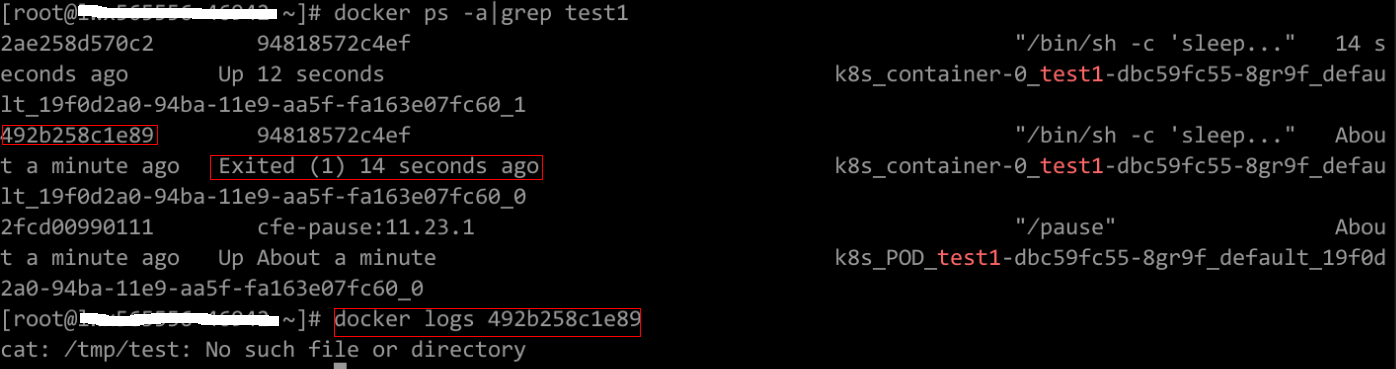
解决方案:
核查“工作负载详情>更新升级页签>高级配置>启动命令”中的信息,确保启动命令配置正确。
排查项九:用户自身业务BUG
请检查工作负载启动命令是否正确执行,或工作负载本身bug导致容器不断重启。
步骤 1 登录异常工作负载所在的节点。
步骤 2 查看工作负载实例非正常退出的容器ID。
docker ps -a | grep $podName
步骤 3 查看退出容器的错误日志。
docker logs $containerID
注意
这里的containerID为已退出的容器的ID
容器启动命令配置不正确

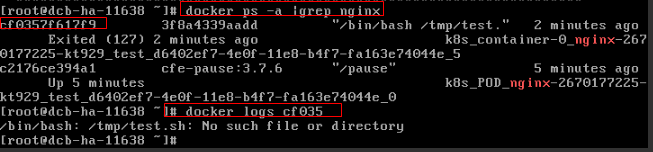
如上图所示,容器配置的启动命令不正确导致容器启动失败。其他错误请根据日志提示修复工作负载本身的BUG问题。
解决方案:
重新创建工作负载,并配置正确的启动命令。
五、工作负载异常:实例驱逐异常(Evicted)
Eviction介绍
Eviction,即驱逐的意思,意思是当节点出现异常时,为了保证工作负载的可用性,kubernetes将有相应的机制驱逐该节点上的Pod。
目前kubernetes中存在两种eviction机制,分别由kube-controller-manager和kubelet实现。
- kube-controller-manager实现的eviction
kube-controller-manager主要由多个控制器构成,而eviction的功能主要由node controller这个控制器实现。该Eviction会周期性检查所有节点状态,当节点处于NotReady状态超过一段时间后,驱逐该节点上所有pod。
kube-controller-manager提供了以下启动参数控制eviction:
pod-eviction-timeout: 即当节点宕机该时间间隔后,开始eviction机制,驱赶宕机节点上的Pod,默认为5min。
node-eviction-rate: 驱赶速率,即驱赶Node的速率,由令牌桶流控算法实现,默认为0.1,即每秒驱赶0.1个节点,注意这里不是驱赶Pod的速率,而是驱赶节点的速率。相当于每隔10s,清空一个节点。
secondary-node-eviction-rate: 二级驱赶速率,当集群中宕机节点过多时,相应的驱赶速率也降低,默认为0.01。
unhealthy-zone-threshold: 不健康zone阈值,会影响什么时候开启二级驱赶速率,默认为0.55,即当该zone中节点宕机数目超过55%,而认为该zone不健康。
large-cluster-size-threshold: 大集群阈值,当该zone的节点多于该阈值时,则认为该zone是一个大集群。大集群节点宕机数目超过55%时,则将驱赶速率降为0.01,假如是小集群,则将速率直接降为0。
- kubelet的eviction机制
如果节点处于资源压力,那么kubelet就会执行驱逐策略。驱逐会考虑Pod的优先级,资源使用和资源申请。当优先级相同时,资源使用/资源申请最大的Pod会被首先驱逐。
kube-controller-manager的eviction机制是粗粒度的,即驱赶一个节点上的所有pod,而kubelet则是细粒度的,它驱赶的是节点上的某些Pod,驱赶哪些Pod与Pod的Qos机制有关。该Eviction会周期性检查本节点内存、磁盘等资源,当资源不足时,按照优先级驱逐部分pod。
驱逐阈值分为软驱逐阈值(Soft Eviction Thresholds)和强制驱逐(Hard Eviction Thresholds)两种机制,如下:
软驱逐阈值: 当node的内存/磁盘空间达到一定的阈值后,kubelet不会马上回收资源,如果改善到低于阈值就不进行驱逐,若这段时间一直高于阈值就进行驱逐。
强制驱逐: 强制驱逐机制则简单的多,一旦达到阈值,直接把pod从本地驱逐。
kubelet提供了以下参数控制eviction:
eviction-soft: 软驱逐阈值设置,具有一系列阈值,比如memory.available<1.5Gi时,它不会立即执行pod eviction,而会等待eviction-soft-grace-period时间,假如该时间过后,依然还是达到了eviction-soft,则触发一次pod eviction。
eviction-soft-grace-period: 默认为90秒,当eviction-soft时,终止Pod的grace的时间,即软驱逐宽限期,软驱逐信号与驱逐处理之间的时间差。
eviction-max-pod-grace-period: 最大驱逐pod宽限期,停止信号与kill之间的时间差。
eviction-pressure-transition-period: 默认为5分钟,驱逐压力过渡时间,超过阈值时,节点会被设置为memory pressure或者disk pressure,然后开启pod eviction。
eviction-minimum-reclaim: 表示每一次eviction必须至少回收多少资源。
eviction-hard : 强制驱逐设置,也具有一系列的阈值,比如memory.available<1Gi,即当节点可用内存低于1Gi时,会立即触发一次pod eviction。
问题定位
若节点故障时,实例未被驱逐,请先按照如下方法进行问题定位。
使用如下命令发现很多pod的状态为Evicted:
kubectl get pods
在节点的kubelet日志中会记录Evicted相关内容,搜索方法可参考如下命令:
cat /var/paas/sys/log/kubernetes/kubelet.log | grep -i Evicted -C3
排查思路
以下排查思路根据原因的出现概率进行排序,建议您从高频率原因往低频率原因排查,从而帮助您快速找到问题的原因。
如果解决完某个可能原因仍未解决问题,请继续排查其他可能原因。
- 排查项一:是否在实例上设置了tolerations
- 排查项二:是否满足停止驱逐实例的条件
- 排查项三:容器与节点上的“资源分配量”是否一致
- 排查项四:工作负载实例不断失败并重新部署
排查思路


排查项一:是否在实例上设置了tolerations
通过kubectl工具或单击对应工作负载后的“更多 > 编辑YAML”,检查工作负载上是不是打上了tolerations,具体请参见https://kubernetes.io/docs/concepts/configuration/taint-and-toleration/。
排查项二:是否满足停止驱逐实例的条件
若属于小规格的集群(集群节点数小于50个节点),如果故障的节点大于总节点数的55%,实例的驱逐将会被暂停。此情况下k8s将部署尝试驱逐故障节点的工作负载,具体请参见https://kubernetes.io/docs/concepts/architecture/nodes/。
排查项三:容器与节点上的“资源分配量”是否一致
容器被驱逐后还会频繁调度到原节点。
问题原因:
节点驱逐容器是根据节点的“资源使用率”进行判断;容器的调度规则是根据节点上的“资源分配量”进行判断。由于判断标准不同,所以可能会出现被驱逐后又再次被调度到原节点的情况。
解决方案:
遇到此类问题时,请合理分配各容器的资源分配量即可解决。
排查项四:工作负载实例不断失败并重新部署
工作负载实例出现不断失败,不断重新部署的情况。
问题分析:
pod驱逐后,如果新调度到的节点也有驱逐情况,就会再次被驱逐;甚至出现pod不断被驱逐的情况。
如果是由kube-controller-manager触发的驱逐,会留下一个状态为Terminating的pod;直到容器所在节点状态恢复后,pod才会自动删除。如果节点已经删除或者其他原因导致的无法恢复,可以使用“强制删除”删除pod。
如果是由kubelet触发的驱逐,会留下一个状态为Evicted的pod,此pod只是方便后期定位的记录,可以直接删除。
解决方案:
使用如下命令删除旧驱赶的遗留:
kubectl get pods | grep Evicted | awk '{print $1}' | xargs kubectl delete pod
为命名空间名称,请根据需要指定。
参考
Kubelet does not delete evicted pods
六、工作负载异常:存储卷无法挂载或挂载超时
排查思路
以下排查思路根据原因的出现概率进行排序,建议您从高频率原因往低频率原因排查,从而帮助您快速找到问题的原因。
如果解决完某个可能原因仍未解决问题,请继续排查其他可能原因。
- 排查项一:EVS存储卷是否跨AZ挂载
- 排查项二:存储中是否同时存在多条权限相关的配置
- 排查项三:带云硬盘卷的Deployment的副本数大于1
- 排查项四:EVS磁盘文件系统损坏
排查思路


排查项一:EVS存储卷是否跨AZ挂载
问题描述:
客户在有状态工作负载上挂载EVS存储卷,但无法挂载卷并超时。
问题定位:
经查询确认,该节点在 可用区1 ,而要挂载的磁盘在 可用区2 ,导致无法挂载而超时。
解决方案:
在同一可用区内创建磁盘再挂载后即可正常。
排查项二:存储中是否同时存在多条权限相关的配置
如果您挂载的存储中内容太多,同时又配置了以下几条配置,最终会由于逐个修改文件权限,而导致挂载时间过长。
问题定位:
- Securitycontext字段中是否包含runAsuser/fsGroup。securityContext是kubernetes中的字段,即安全上下文,它用于定义Pod或Container的权限和访问控制设置。
- 启动命令中是否包含ls、chmod、chown等查询或修改文件权限的操作。
解决建议 :
请根据您的业务需求,判断是否需要修改。
排查项三:带云硬盘卷的Deployment的副本数大于1
问题描述:
创建Pod失败,并报“添加存储失败”的事件,事件信息如下。
Multi-Attach error for volume "pvc-62a7a7d9-9dc8-42a2-8366-0f5ef9db5b60" Volume is already used by pod(s) testttt-7b774658cb-lc98h
问题定位:
查看Deployment的副本数是否大于1。
Deployment中使用EVS存储卷时,副本数只能为1。若用户在后台指定Deployment的实例数为2以上,此时CCE并不会限制Deployment的创建。但若这些实例Pod被调度到不同的节点,则会有部分Pod因为其要使用的EVS无法被挂载到节点,导致Pod无法启动成功。
解决方案:
使用EVS的Deployment的副本数指定为1,或使用其他类型存储卷。
排查项四:EVS磁盘文件系统损坏
问题描述:
创建Pod失败,出现类似信息,磁盘文件系统损坏。
MountVolume.MountDevice failed for volume "pvc-08178474-c58c-4820-a828-14437d46ba6f" : rpc error: code = Internal desc = [09060def-afd0-11ec-9664-fa163eef47d0] /dev/sda has file system, but it is detected to be damaged
解决方案:
在EVS中对磁盘进行备份,然后执行如下命令修复文件系统。
fsck -y {盘符}
七、工作负载异常:一直处于创建中
问题描述
节点变更之后,节点上的工作负载一直处于创建中。
解决方法
步骤 1 登录CCE节点(弹性云服务器)并删除cpu_manager_state文件。
删除命令示例如下:
rm -rf /mnt/paas/kubernetes/kubelet/cpu_manager_state
步骤 2 重启节点或重启kubelet,重启kubelet的方法如下:
systemctl restart kubelet
此时重新拉起或创建工作负载,已可成功执行。
解决方式链接:CCE节点变更规格后,为什么无法重新拉起或创建工作负载?
八、工作负载异常:结束中,解决Terminating状态的Pod删不掉的问题
问题描述
在节点处于“不可用”状态时,CCE会迁移节点上的容器实例,并将节点上运行的pod置为“Terminating”状态。
待节点恢复后,处于“Terminating”状态的pod会自动删除。
偶现部分pod(实例)一直处于“Terminating ”状态:
#kubectl get pod -n aosNAME READY STATUS RESTARTS AGEaos-apiserver-5f8f5b5585-s9l92 1/1 Terminating 0 3d1haos-cmdbserver-789bf5b497-6rwrg 1/1 Running 0 3d1haos-controller-545d78bs8d-vm6j9 1/1 Running 3 3d1h
通过kubectl delete pods -n 命令始终无法将其删除:
kubectl delete pods aos-apiserver-5f8f5b5585-s9l92 -n aos
解决方法
无论各种方式生成的pod,均可以使用如下命令强制删除:
kubectl delete pods --grace-period=0 --force
因此对于上面的pod,我们只要执行如下命令即可删除:
kubectl delete pods aos-apiserver-5f8f5b5585-s9l92 --grace-period=0 --force
九、工作负载异常:已停止
问题现象
工作负载的状态为“已停止”。
问题原因:
工作负载的yaml的中metadata.enable字段为false,导致工作负载被停止,Pod被删除导致工作负载处于已停止状态,如下图所示:

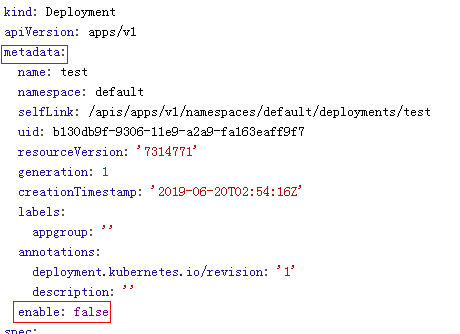
解决方案
将enable字段删除或者将false修改为true。
十、在什么场景下设置工作负载生命周期中的“停止前处理”?
服务的业务处理时间较长,在升级时,需要先等Pod中的业务处理完,才能kill该Pod,以保证业务不中断的场景。
十一、在同一个命名空间内访问指定容器的FQDN是什么?
问题背景
客户询问在创建负载时指定部署的容器名称、pod名称、namespace名称,在同一个命名空间内访问该容器的FQDN是什么?
全限定域名:FQDN,即Fully Qualified Domain Name,同时带有主机名和域名的名称。(通过符号“.”)
例如:主机名是bigserver,域名是mycompany.com,那么FQDN就是:bigserver.mycompany.com。
问题建议
方案一: 发布服务使用域名发现,需要提前预制好主机名和命名空间,服务发现使用域名的方式,注册的服务的域名为:服务名.命名空间.svc.cluster.local 。这种使用有限制,注册中心部署必须容器化部署。
方案二: 容器部署使用主机网络部署,然后亲和到集群的某一个节点,这样可以明确知道容器的服务地址(就是节点的地址),注册的地址为:服务所在节点IP,这种方案可以满足注册中心利用VM部署,缺陷是使用主机网络效率没有容器网络高。
十二、健康检查探针(Liveness、Readiness)偶现检查失败?
健康检查探针偶现检测失败,是由于容器内的业务故障所导致,您需要优先定位自身业务问题。
常见情况有:
- 业务处理时间长,导致返回超时。
- tomcat建链和等到耗费时间太长(连接数、线程数等),导致返回超时。
- 容器所在节点,磁盘IO等性能达到瓶颈,导致业务处理超时。
十三、 如何设置容器umask值?
问题描述
tailf /dev/null的方式启动容器,然后手动执行启动脚本的方式得到的目录的权限是700,而不加tailf由Kubernetes自行启动的方式得到的目录权限却是751。
操作步骤
这个问题是因为两种方式设置的umask值不一样,所以创建出来的目录权限不相同。
umask值用于为用户新创建的文件和目录设置缺省权限。如果umask的值设置过小,会使群组用户或其他用户的权限过大,给系统带来安全威胁。因此设置所有用户默认的umask值为0077,即用户创建的目录默认权限为700,文件的默认权限为600。
可以在启动脚本里面增加如下内容实现创建出来的目录权限为700:
- 分别在**/etc/bashrc**文件和 /etc/profile.d/ 目录下的所有文件中加入“umask 0077”。
- 执行如下命令:
echo "umask 0077" >> $FILE
说明
FILE为具体的文件名,例如:echo “umask 0077” >> /etc/bashrc
- 设置**/etc/bashrc**文件和 /etc/profile.d/ 目录下所有文件的属主为:root,群组为:root。
- 执行如下命令:
chown root.root $FILE
十四、 Dockerfile中ENTRYPOINT指定JVM启动堆内存参数后部署容器启动报错?
问题描述
Dockerfile中ENTRYPOINT指定JVM启动堆内存参数后部署容器启动报错,报错信息为:invalid initial heap size,如下图:


操作步骤
请检查ENTRYPOINT设置,下方的设置是错误的:
ENTRYPOINT ["java","-Xms2g -Xmx2g","-jar","xxx.jar"]
如下两种办法可以解决该问题:
- (推荐) 将容器启动命令写在“工作负载 > 更新升级 > 容器设置 > 生命周期 > 启动命令”这里,容器能正常启动。
- 将ENTRYPOINT启动命令修改为如下格式:
ENTRYPOINT exec java -Xmx2g -Xms2g -jar xxxx.jar
十五、 CCE启动实例失败时的重试机制是怎样的?
CCE是基于原生Kubernetes的云容器引擎服务,完全兼容Kubernetes社区原生版本,与社区最新版本保持紧密同步,完全兼容Kubernetes API和Kubectl。
在Kubernetes中,Pod的spec中包含一个restartPolicy字段,其取值包括:Always、OnFailure和Never,默认值为:Always。
- Always:当容器失效时,由kubelet自动重启该容器。
- OnFailure:当容器终止运行且退出不为0时(正常退出),由kubelet自动重启该容器。
- Never:不论容器运行状态如何,kubelet都不会重启该容器。
restartPolicy适用于Pod中的所有容器。
restartPolicy仅针对同一节点上kubelet的容器重启动作。当Pod中的容器退出时,kubelet 会按指数回退方式计算重启的延迟(10s、20s、40s...),其最长延迟为5分钟。 一旦某容器执行了10分钟并且没有出现问题,kubelet对该容器的重启回退计时器执行重置操作。
每种控制器对Pod的重启策略要求如下:
- Replication Controller(RC)和DaemonSet:必须设置为Always,需要保证该容器的持续运行。
- Job:OnFailure或Never,确保容器执行完成后不再重启。
十六、 CCE集群中工作负载镜像的拉取策略?
容器在启动运行前,需要镜像。镜像的存储位置可能会在本地,也可能会在远程镜像仓库中。
Kubernetes配置文件中的imagePullPolicy属性是用于描述镜像的拉取策略的,如下:
- Always:总是拉取镜像。
imagePullPolicy: Always
- IfNotPresent:本地有则使用本地镜像,不拉取。
imagePullPolicy: IfNotPresent
- Never:只使用本地镜像,从不拉取,即使本地没有。
imagePullPolicy: Never
说明
1. 如果设置为Always ,则每次容器启动或者重启时,都会从远程仓库拉取镜像。
如果省略imagePullPolicy,策略默认为Always。
2. 如果设置为IfNotPreset,有下面两种情况:
当本地不存在所需的镜像时,会从远程仓库中拉取。
如果我们需要的镜像和本地镜像内容相同,只不过重新打了tag。此tag镜像本地不存在,而远程仓库存在此tag镜像。这种情况下,Kubernetes并不会拉取新的镜像。

