一、纳管节点时失败,报错“安装节点失败”
问题描述
节点纳管失败报错安装节点失败。
问题原因
登录节点,查看/var/paas/sys/log/baseagent/baseagent.log安装日志,发现如下报错:


查看节点LVM设置,发现/dev/vdb没有创建LVM逻辑卷。
解决方案
手工创建逻辑卷:
pvcreate /dev/vdbvgcreate vgpaas /dev/vdb
然后在界面重置节点后节点状态正常。
二、集群可用,但节点状态为“不可用”?
当集群状态为“可用”,而集群中部分节点状态为“不可用”时,请参照如下方式来排查解决。
节点不可用检测机制说明
Kubernetes 节点发送的心跳确定每个节点的可用性,并在检测到故障时采取行动。检测的机制和间隔时间详细说明请参见心跳。
使用NPD插件排查故障
CCE提供节点故障检测NPD插件,NPD插件从1.16.0版本开始增加了大量检查项,能对节点上各种资源和组件的状态检测,帮助发现节点故障。
强烈建议您安装该插件,如已安装请查看插件版本并升级到1.16.0及以上版本。
安装NPD插件后,当节点出现异常时,控制台上可以查看到指标异常。

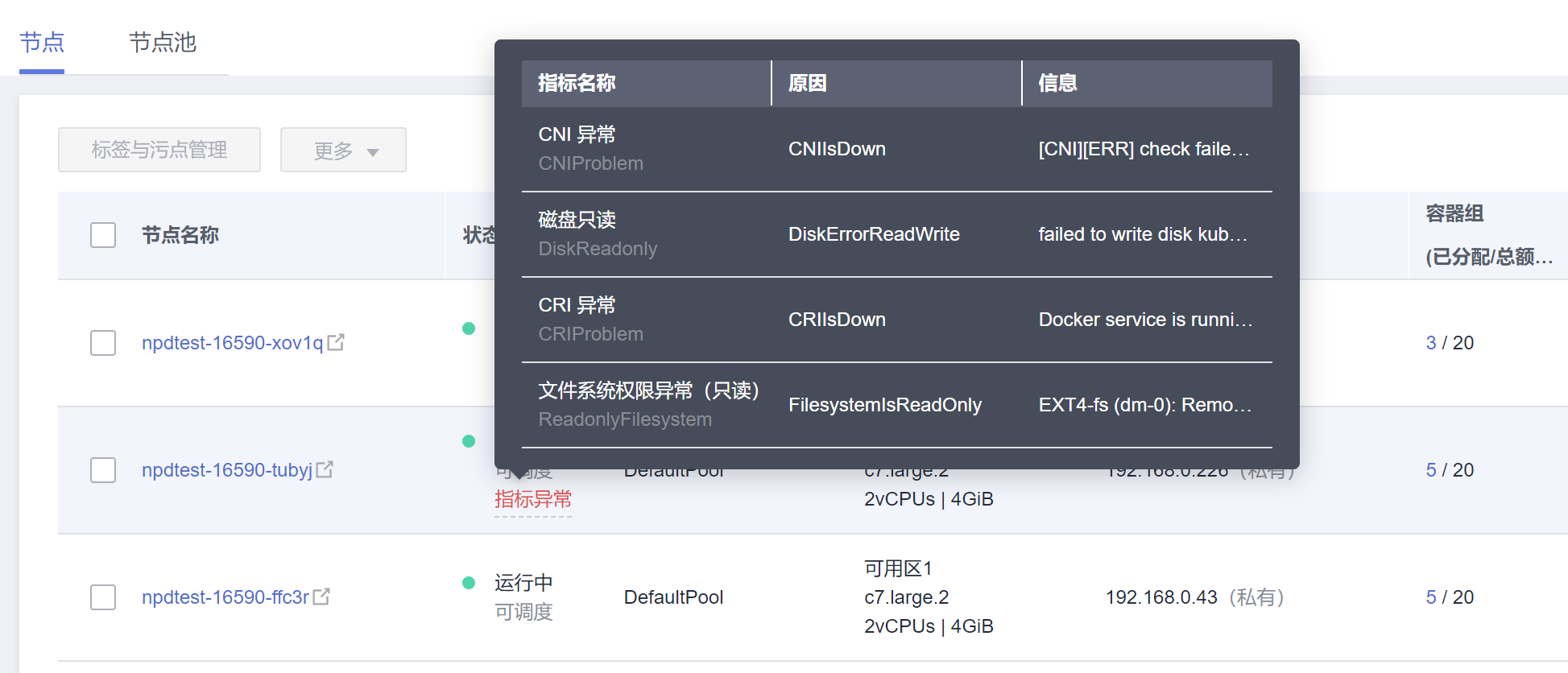
您还可以在节点事件中查看到NPD上报的事件,根据事件信息可以定位故障。

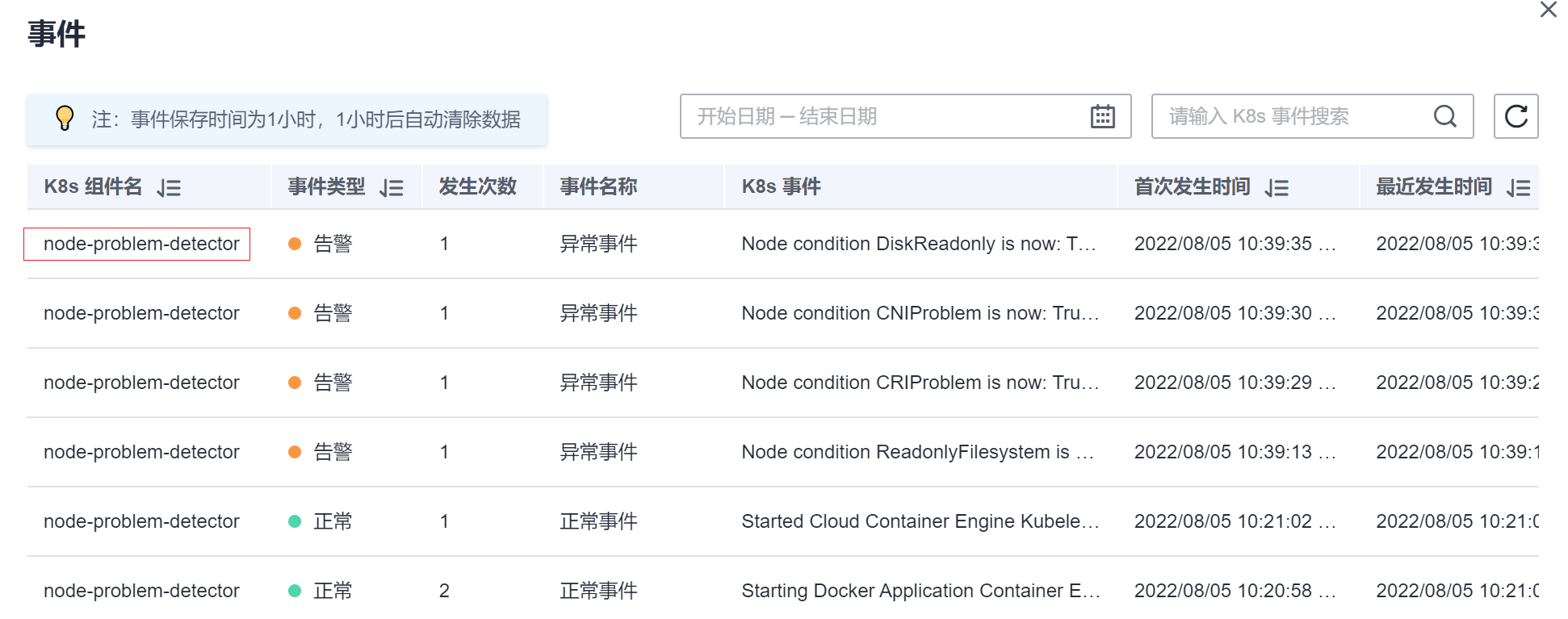
故障事件说明
| 故障事件 | 说明 |
|---|---|
| OOMKilling | 检查oom事件发生并上报。可能原因:用户在ECS侧误操作卸载数据盘。处理建议:排查项一:节点负载过高。 |
| TaskHung | 检查taskHung事件发生并上报 |
| KernelOops | 检查内核0指针panic错误 |
| ConntrackFull | 检查连接跟踪表是否满 |
| FrequentKubeletRestart | 检测kubelet频繁重启 |
| FrequentDockerRestart | 检测docker频繁重启 |
| FrequentContainerdRestart | 检测containerd频繁重启 |
| CRIProblem | 检查容器CRI组件状态 |
| KUBELETProblem | 检查Kubelet状态 |
| NTPProblem | 检查ntp服务状态 |
| PIDProblem | 检查Pid是否充足 |
| FDProblem | 检查文件句柄数是否充足 |
| MemoryProblem | 检查节点整体内存是否充足 |
| CNIProblem | 检查容器CNI组件状态 |
| KUBEPROXYProblem | 检查Kube-proxy状态 |
| ReadonlyFilesystem | 检查系统内核是否有Remount root filesystem read-only错误。可能原因:用户在ECS侧误操作卸载数据盘、节点vdb盘被删除。处理建议: 排查项六:检查磁盘是否异常 排查项九:检查节点中的vdb盘是否被删除 |
| DiskReadonly | 检查系统盘、docker盘、kubelet盘是否只读可能原因:用户在ECS侧误操作卸载数据盘、节点vdb盘被删除。处理建议: 排查项六:检查磁盘是否异常 排查项九:检查节点中的vdb盘是否被删除 |
| DiskProblem | 检查磁盘使用量与关键逻辑磁盘挂载检查系统盘、docker盘、kubelet盘磁盘使用率,检查docker盘、kubelet盘是否正常挂载在虚拟机上。 |
| PIDPressure | 检查PID是否充足。处理建议:PID不足时可调整PID上限。 |
| MemoryPressure | 检查容器可分配空间(allocable)内存是否充足 |
| DiskPressure | 检查kubelet盘和docker盘的磁盘使用量及inodes使用量。处理建议:扩容数据盘。 |
排查思路
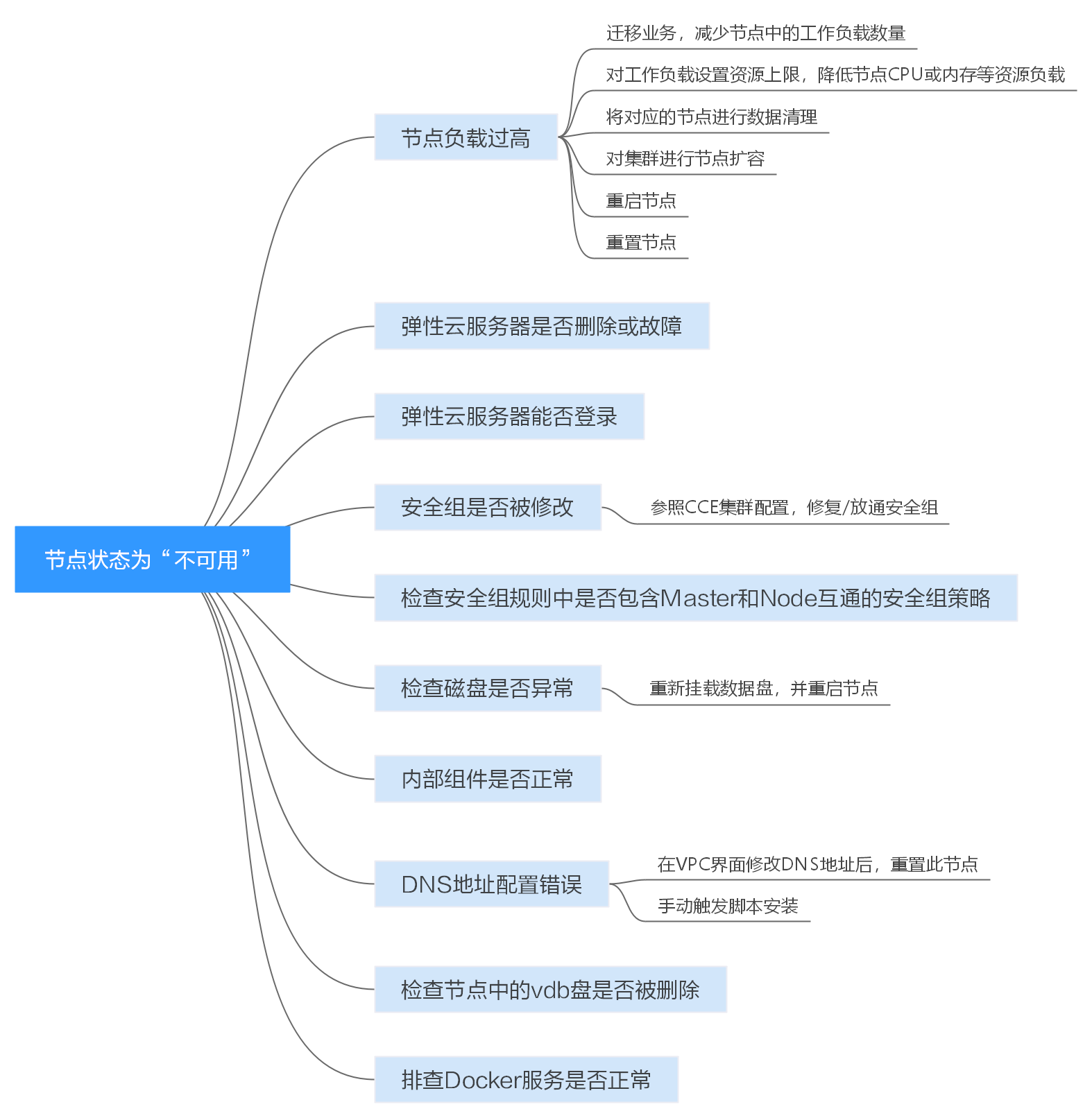
以下排查思路根据原因的出现概率进行排序,建议您从高频率原因往低频率原因排查,从而帮助您快速找到问题的原因。
如果解决完某个可能原因仍未解决问题,请继续排查其他可能原因。
- 排查项一:节点负载过高
- 排查项二:弹性云服务器是否删除或故障
- 排查项三:弹性云服务器能否登录
- 排查项四:安全组是否被修改
- 排查项五:检查安全组规则中是否包含Master和Node互通的安全组策略
- 排查项六:检查磁盘是否异常
- 排查项七:内部组件是否正常
- 排查项八:DNS地址配置错误
- 排查项九:检查节点中的vdb盘是否被删除
- 排查项十:排查Docker服务是否正常
排查思路

排查项一:节点负载过高
问题描述:
集群中节点连接异常,多个节点报写入错误,业务未受影响。
问题定位:
步骤 1 登录CCE控制台,进入集群,在不可用节点所在行单击“监控”。
步骤 2 单击“监控”页签顶部的“查看更多”,前往运维管理页面查看历史监控记录。
当节点cpu和内存负载过高时,会导致节点网络时延过高,或系统OOM,最终展示为不可用。
解决方案:
- 建议迁移业务,减少节点中的工作负载数量,并对工作负载设置资源上限,降低节点CPU或内存等资源负载。
- 将集群中对应的cce节点进行数据清理。
- 限制每个容器的CPU和内存限制配额值。
- 对集群进行节点扩容。
- 您也可以重启节点,请至ECS控制台对节点进行重启。
- 增加节点,将高内存使用的业务容器分开部署。
- 对负载过高的节点进行重置操作。
节点恢复为可用后,工作负载即可恢复正常。
排查项二:弹性云服务器是否删除或故障
步骤 1 确认集群是否可用。
登录CCE控制台,确定集群是否可用。
- 若集群非可用状态,如错误等,请参见当集群状态为“不可用”时,如何排查解决?。
- 若集群状态为“运行中”,而集群中部分节点状态为“不可用”,请执行步骤2。
步骤 2 登录ECS控制台,查看对应的弹性云服务器状态。
- 若弹性云服务器状态为“已删除”:请在CCE中删除对应节点,再重新创建节点。
- 若弹性云服务器状态为“关机”或“冻结”:请先恢复弹性云服务器,约3分钟后集群节点可自行恢复。
- 若弹性云服务器出现故障:请先重启弹性云服务器,恢复故障。
- 若弹性云服务器状态为“可用”:请参考排查项七:内部组件是否正常登录弹性云服务器进行本地故障排查。
排查项三:弹性云服务器能否登录
步骤 1 登录ECS控制台。
步骤 2 确认界面显示的节点名称与虚机内的节点名称是否一致,并且密码或者密钥能否登录。
确认界面显示的名称

确认虚机内的节点名称和能否登录

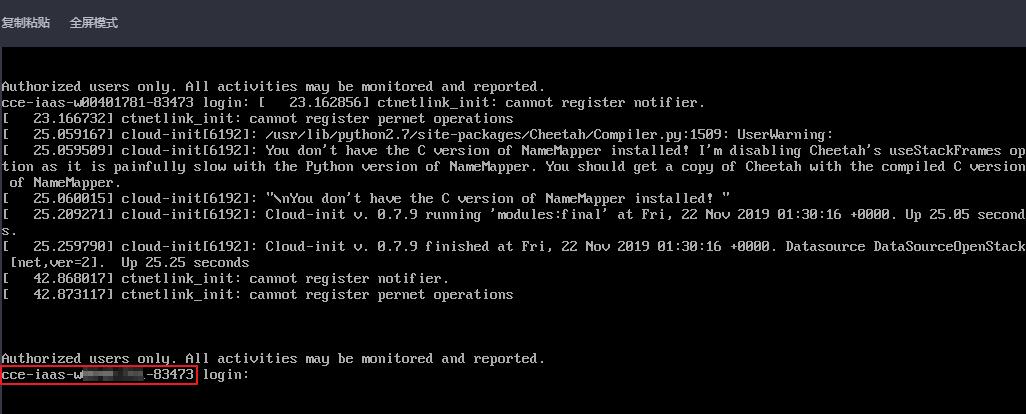
如果节点名称不一致,并且密码和密钥均不能登录,说明是ECS创建虚机时的cloudinit初始化问题,临时规避可以尝试重启节点,之后再提交工单确认问题根因。
排查项四:安全组是否被修改
登录VPC控制台,在左侧栏目树中单击“访问控制 > 安全组”,找到集群控制节点的安全组。
控制节点安全组名称为:集群名称-cce- control -编号。您可以通过集群名称查找安全组,再进一步在名称中区分“-cce-control-”字样,即为本集群安全组。
排查安全组中规则是否被修改,安全的详细说明请参见集群安全组规则配置
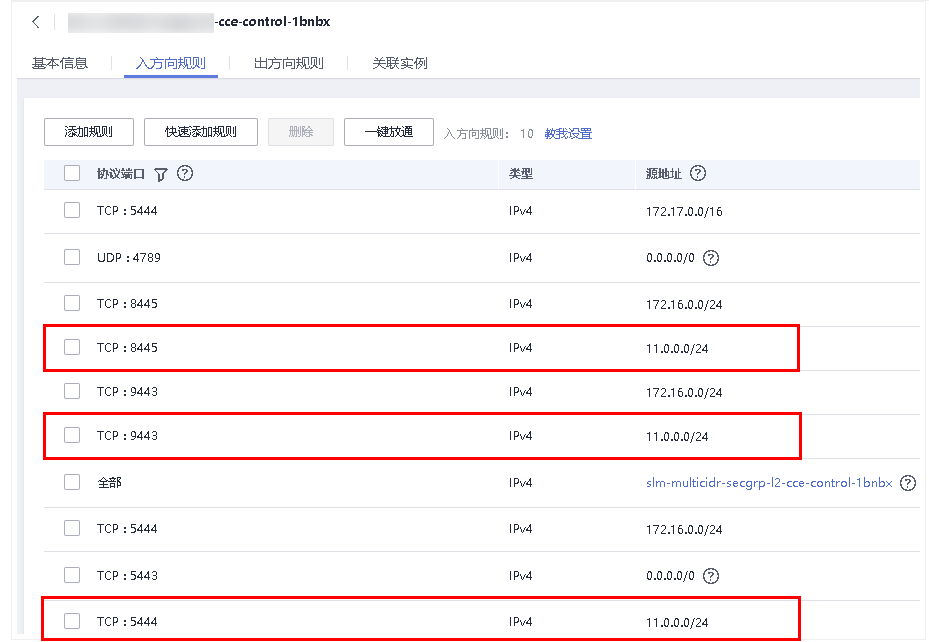
排查项五:检查安全组规则中是否包含Master和Node互通的安全组策略
请检查安全组规则中是否包含Master和Node互通的安全组策略。
已有集群添加节点时,如果子网对应的VPC新增了扩展网段且子网是扩展网段,要在控制节点安全组(即集群名称-cce-control-随机数)中添加如下三条安全组规则,以保证集群添加的节点功能可用(新建集群时如果VPC已经新增了扩展网段则不涉及此场景)。
安全的详细说明请参见集群安全组规则配置

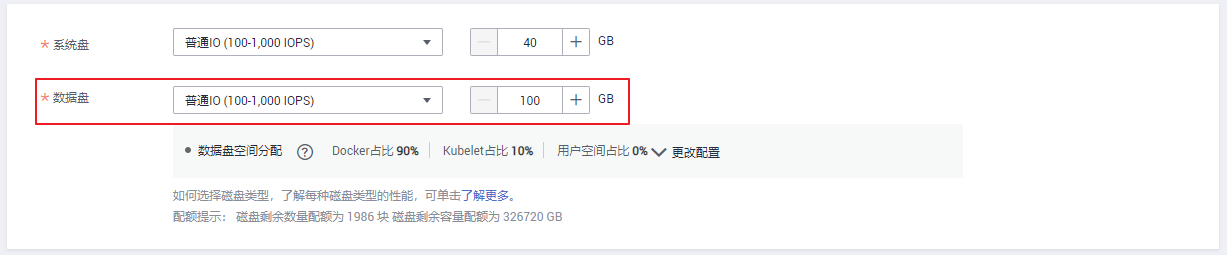
排查项六:检查磁盘是否异常
新建节点会给节点绑定一个100G的docker专用数据盘。若数据盘卸载或损坏,会导致docker服务异常,最终导致节点不可用。
集群新建节点时的数据盘

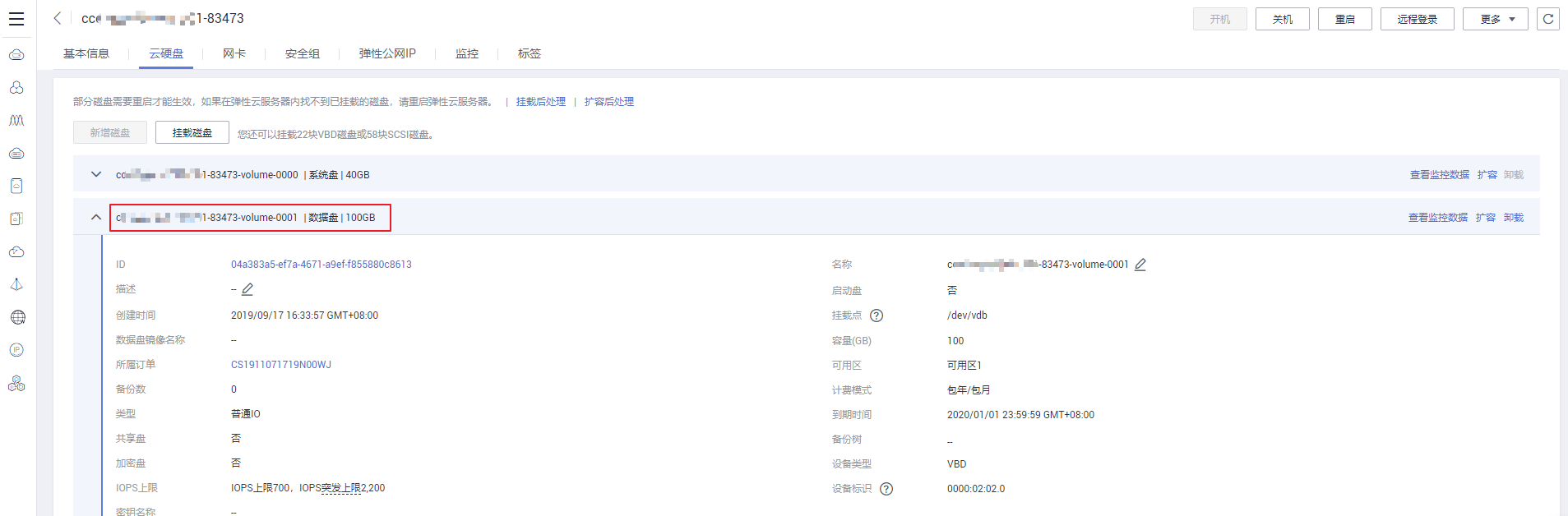
请检查节点挂载的数据盘是否已被卸载。若已卸载请重新挂载数据盘,再重启节点,节点可恢复。
磁盘检查

排查项七:内部组件是否正常
步骤 1 登录不可用节点对应的弹性云服务器。
步骤 2 执行以下命令判断paas组件是否正常。
systemctl status kubelet
执行成功,可查看到各组件的状态为Active,如下图:

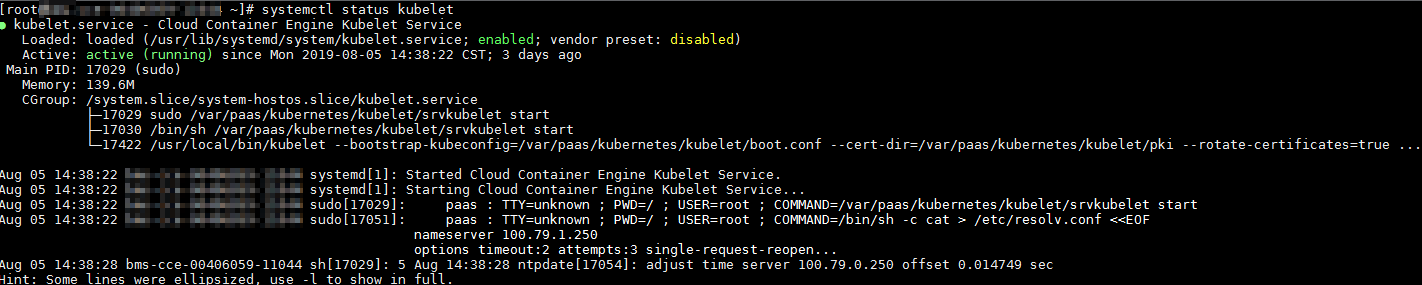
若服务的组件状态不是Active,执行如下命令:
重启命令根据出错组件指定,如canal组件出错,则命令为:systemctl restart canal
重启后再查看状态:systemctl status canal
步骤 3 若执行失败,请执行如下命令,查看monitrc进程的运行状态。
ps -ef | grep monitrc
若存在此进程,请杀死此进程,进程杀死后会自动重新拉起。
kill -s 9 ps -ef | grep monitrc | grep -v grep | awk '{print $2}'
排查项八:DNS地址配置错误
步骤 1 登录节点,在日志/var/log/cloud-init-output.log中查看是否有域名解析失败相关的报错。
cat /var/log/cloud-init-output.log | grep resolv
如果回显包含如下内容则说明无法解析该域名。
Could not resolve host: test.obs.cn-gz1.ctyun.cn; Unknown error
步骤 2 在节点上ping上一步无法解析的示例域名,确认节点上能否解析此域名。
ping test.obs.cn-gz 1 .ctyun.cn
- 如果不能,则说明DNS无法解析该地址。请确认/etc/resolv.conf文件中的DNS地址与配置在VPC的子网上的DNS地址是否一致,通常是由于此DNS地址配置错误,导致无法解析此域名。请修改VPC子网DNS为正确配置,然后重置节点。
- 如果能,则说明DNS地址配置没有问题,请排查其他问题。
排查项九:检查节点中的vdb盘是否被删除
如果节点中的vdb盘被删除,可参考此章节内容恢复节点。
排查项十:排查Docker服务是否正常
步骤 6 执行以下命令确认docker服务是否正在运行:
systemctl status docker

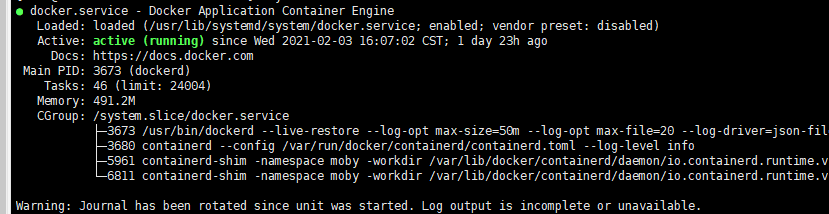
若执行失败或服务状态非active,请确认docker运行失败原因,必要时可提交工单联系技术支持。
步骤 2 执行以下命令检查当前节点上所有容器数量:
docker ps -a | wc -l
若命令卡死、执行时间过长或异常容器数过多(1000以上),请确认外部是否存在重复不断地创删负载现象,在大量容器频繁创删过程中有可能出现大量异常容器且难以及时清理。
在此场景下可考虑停止重复创删负载或采用更多的节点去分摊负载,一般等待一段时间后节点会恢复正常,必要情况可执行docker rm {container_id}手动清理异常容器。
三、 如何变更CCE集群中的节点规格?
操作方法
注意
如果需要变更规格的节点是纳管到集群中的,可将节点从CCE集群中移除后再变更节点规格,避免影响业务。
步骤 1 登录CCE控制台,进入集群,在左侧选择“节点管理”,在右侧单击节点名称,跳转到弹性云服务器详情页。
步骤 2 在弹性云服务器详情页中,单击右上角的“关机”,关机完成后单击“更多 > 变更规格”。
步骤 3 在“云服务器变更规格”页面中根据业务需求选择相应的规格,单击“提交”完成节点规格的变更,返回弹性云服务器列表页,将该云服务器执行“开机”操作。
步骤 4 登录CCE控制台,进入集群,在节点管理列表中找到该节点,并单击操作栏中的“同步云服务器”,同步后即可看到节点规格已与弹性云服务器中变更的规格一致。
四、CCE节点变更规格后,为什么无法重新拉起或创建工作负载?
问题背景
kubelet启动参数中默认将CPU Manager的策略设置为static,允许为节点上具有某些资源特征的pod赋予增强的CPU亲和性和独占性。用户如果直接在ECS控制台对CCE节点变更规格,会由于变更前后CPU信息不匹配,导致节点上的负载无法重新拉起,也无法创建新负载。
更多信息请参Kubernetes控制节点上的CPU管理策略。
影响范围
集群开启了CPU管理策略的集群。
解决方案
步骤 1 登录CCE节点(弹性云服务器)并删除cpu_manager_state文件。
删除命令示例如下:
rm -rf /mnt/paas/kubernetes/kubelet/cpu_manager_state
步骤 2 重启节点或重启kubelet,重启kubelet的方法如下:
systemctl restart kubelet
步骤 3 此时重新拉起或创建工作负载,已可成功执行。
五、thinpool磁盘空间耗尽导致容器或节点异常时,如何解决?
问题描述
当节点上的thinpool磁盘空间接近写满时,概率性出现以下异常:
在容器内创建文件或目录失败、容器内文件系统只读、节点被标记disk-pressure污点及节点不可用状态等。
用户可手动在节点上执行docker info查看当前thinpool空间使用及剩余量信息,从而定位该问题。如下图:

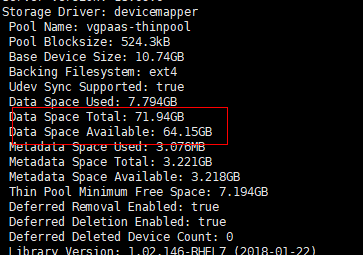
问题原理
docker devicemapper模式下,尽管可以通过配置basesize参数限制单个容器的主目录大小(默认为10GB),但节点上的所有容器还是共用节点的thinpool磁盘空间,并不是完全隔离,当一些容器使用大量thinpool空间且总和达到节点thinpool空间上限时,也会影响其他容器正常运行。
另外,在容器的主目录中创删文件后,其占用的thinpool空间不会立即释放,因此即使basesize已经配置为10GB,而容器中不断创删文件时,占用的thinpool空间会不断增加一直到10GB为止,后续才会复用这10GB空间。如果节点上的 业务容器数*basesize > 节点thinpool空间大小 ,理论上有概率出现节点thinpool空间耗尽的场景。
解决方案
当节点已出现thinpool空间耗尽时,可将部分业务迁移至其他节点实现业务快速恢复。但对于此类问题,建议采用以下方案从根因上解决问题:
方案1:
合理规划业务分布及数据面磁盘空间,避免和减少出现业务容器数*basesize > 节点thinpool空间大小场景。如需对thinpool空间进行扩容。
方案2:
容器业务的创删文件操作建议在容器挂载的本地存储(如emptyDir、hostPath)或云存储的目录中进行,这样不会占用thinpool空间。
方案3:
使用overlayfs存储模式的操作系统,可将业务部署在此类节点上,避免容器内创删文件后占用的磁盘空间不立即释放问题。

