什么是数据血缘
大数据时代,数据爆发性增长,海量的、各种类型的数据在快速产生。这些庞大复杂的数据信息,通过联姻融合、转换变换、流转流通,又生成新的数据,汇聚成数据的海洋。
数据的产生、加工融合、流转流通,到最终消亡,数据之间自然会形成一种关系。我们借鉴人类社会中类似的一种关系来表达数据之间的这种关系,称之为数据的血缘关系。与人类社会中的血缘关系不同,数据的血缘关系还包含了一些特有的特征:
- 归属性 :一般来说,特定的数据归属特定的组织或者个人,数据具有归属性。
- 多源性 :同一个数据可以有多个来源(多个父亲)。一个数据可以是多个数据经过加工而生成的,而且这种加工过程可以是多个。
- 可追溯性 :数据的血缘关系,体现了数据的生命周期,体现了数据从产生到消亡的整个过程,具备可追溯性。
- 层次性 :数据的血缘关系是有层次的。对数据的分类、归纳、总结等对数据进行的描述信息又形成了新的数据,不同程度的描述信息形成了数据的层次。
详见下图:数据血缘关系示例
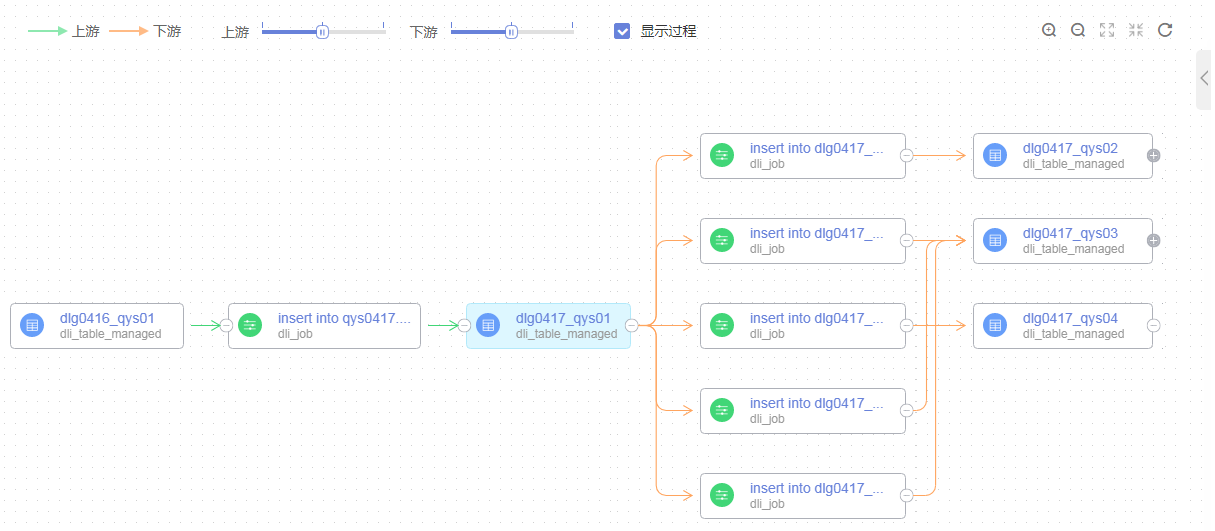
DataArts Studio数据血缘实现方案
- 数据血缘的产生:
在DataArtsStudio平台,自动分析血缘是通过在数据开发模块中配置数据处理迁移类型的节点产生的,当前支持采集节点静态配置产生的血缘和部分节点实例上的血缘。详情请参见 配置数据血缘章节中的 自动分析血缘。
另外,DataArtsStudio平台还支持手动配置血缘方式,当用户手动配置血缘时,自动分析血缘将不生效。详情请参见 配置数据血缘章节中的 手动配置血缘。
- 数据血缘的展示:
当数据开发模块中的作业已完成血缘关系配置后,启动作业调度,并在数据目录模块进行元数据采集任务,则可以在数据目录模块可视化查看数据血缘关系。

