数据集成:多种方式异构数据源高效接入DataArts Studio数据集成支持批量数据迁移和实时数据接入两种方式。
批量数据迁移
批量数据迁移提供20+同构/异构数据源之间批量数据迁移的功能,帮助您实现数据自由流动。支持自建和云上的文件系统,关系数据库,数据仓库,NoSQL,大数据云服务,对象存储等数据源。
批量数据迁移基于分布式计算框架,利用并行化处理技术,支持用户稳定高效地对海量数据进行移动,实现不停服数据迁移,快速构建所需的数据架构。
详见下图:批量数据迁移
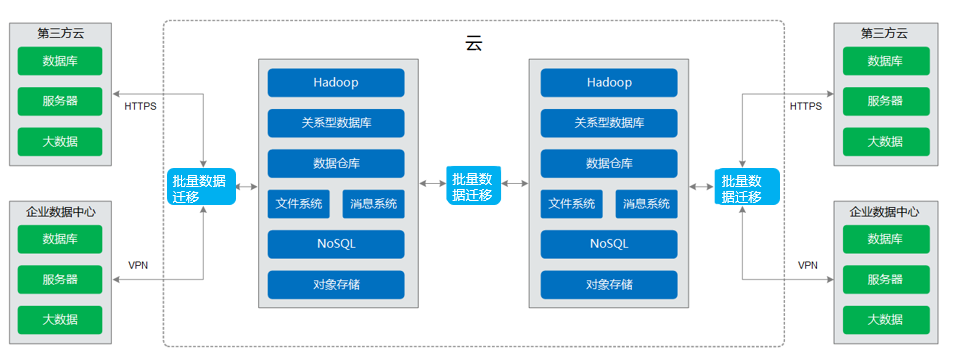
批量数据迁移提供全向导式任务管理界面,帮助用户在几分钟内完成数据迁移任务的创建,轻松应对复杂迁移场景。批量数据迁移支持的功能主要有:
表/ 文件/ 整库迁移
支持批量迁移表或者文件,还支持同构/异构数据库之间整库迁移,一个作业即可迁移几百张表。
增量数据迁移
支持文件增量迁移、关系型数据库增量迁移、HBase增量迁移,以及使用Where条件配合时间变量函数实现增量数据迁移。
事务模式迁移
支持当迁移作业执行失败时,将数据回滚到作业开始之前的状态,自动清理目的表中的数据。
字段转换
支持去隐私、字符串操作、日期操作等常用字段的数据转换功能。
文件加密
在迁移文件到文件系统时,批量数据迁移支持对写入云端的文件进行加密。
MD5校验一致性
支持使用MD5校验,检查端到端文件的一致性,并输出校验结果。
脏数据归档
支持将迁移过程中处理失败的、被清洗过滤掉的、不符合字段转换或者不符合清洗规则的数据自动归档到脏数据日志中,方便用户分析异常数据。并支持设置脏数据比例阈值,来决定任务是否成功。
数据开发:一站式协同开发平台
DataArts Studio数据开发是一个一站式敏捷大数据开发平台,提供可视化的图形开发界面、丰富的数据开发类型(脚本开发和作业开发)、全托管的作业调度和运维监控能力,内置行业数据处理pipeline,一键式开发,全流程可视化,支持多人在线协同开发,支持管理多种大数据云服务,极大地降低了用户使用大数据的门槛,帮助用户快速构建大数据处理中心。
数据开发支持数据管理、数据集成、脚本开发、作业开发、资源管理、作业调度、运维监控等操作,帮助用户轻松完成整个数据的处理分析流程。
数据管理
- 支持管理DWS、MRS Hive等多种数据仓库。
- 支持可视化和DDL方式管理数据库表。
数据集成
与批量数据迁移无缝集成,依托批量数据迁移的强力支撑,支持20多种异构数据源之间可靠高效的数据传输,轻松实现多数据源集成到数据仓库。
脚本开发
- 提供在线脚本编辑器,支持多人协作进行SQL、Shell脚本在线代码开发和调测。
- 支持使用变量和函数。
作业开发
- 提供图形化设计器,支持拖拽式工作流开发,快速构建数据处理业务流水线。
- 预设数据集成、SQL、Shell等多种任务类型,通过任务间依赖完成复杂数据分析处理。
- 支持导入和导出作业。
资源管理
支持统一管理在脚本开发和作业开发使用到的file、jar、archive类型的资源。
作业调度
- 支持单次调度、周期调度和事件驱动调度,周期调度支持分钟、小时、天、周、月多种调度周期。
- 作业调度支持多种云服务的多种类型的任务混合编排,高性能的调度引擎已经经过几百个应用的检验。
运维监控
- 支持对作业进行运行、暂停、恢复、终止等多种操作。
- 支持查看作业和其内各任务节点的运行详情。
- 支持配置多种方式报警,作业和任务发生错误时可及时通知相关人,保证业务正常运行。

