操作场景
CDM可以实现在同构、异构数据源之间进行表或文件级别的数据迁移,支持表/文件迁移的数据源请参见支持的数据源中表/文件迁移支持的数据源类型。
约束限制
- 记录脏数据功能依赖于OBS服务。
- 作业导入时,JSON文件大小不超过1MB。
前提条件
- 已新建连接。
- CDM集群与待迁移数据源可以正常通信。
操作步骤
1.进入CDM主界面,单击左侧导航上的“集群管理”,选择集群后的“作业管理”。
2.选择“表/文件迁移 > 新建作业”,进入作业配置界面。
详见下图:新建表/文件迁移的作业
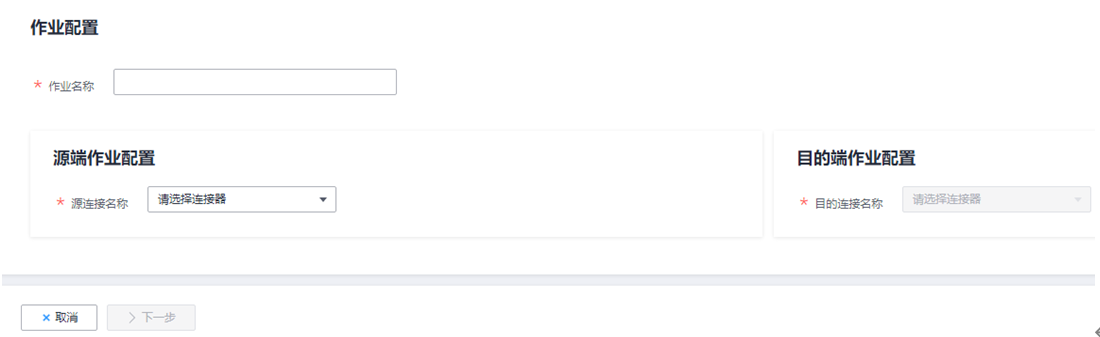
3.选择源连接、目的连接:
- 作业名称:用户自定义任务名称,名称由中文、数字、字母、中划线、下划线、点号,且首字符不能是中划线或点号组成,长度必须在1到240个字符之间,例如“oracle2obs_t”。
- 源连接名称:选择待迁移数据的数据源,作业运行时将从此端复制导出数据。
- 目的连接名称:选择将数据迁移到哪个数据源,作业运行时会将数据导入此端。
4.选择源连接后,配置作业参数。
每种数据源对应的作业参数不一样,其它类型数据源的作业参数请根据下表选择。
源端作业参数说明
| 源端类型 | 说明 | 参数配置 |
|---|---|---|
| OBS | 支持以CSV、JSON或二进制格式抽取数据,其中二进制方式不解析文件内容,性能快,适合文件迁移。 | 参见配置OBS源端参数。 |
| MRS HDFs FusionInsight HDFS Apache HDFS |
支持以CSV、Parquet或二进制格式抽取HDFS数据,支持多种压缩格式。 | 参见配置HDFS源端参数。 |
| MRS HBase FusionInsight HBase Apache HBase CloudTable |
支持从MRS、FusionInsight HD、开源Apache Hadoop的HBase,或CloudTable服务导出数据,用户需要知道HBase表的所有列族和字段名。 | 参见配置HBase/CloudTable源端参数。 |
| MRS Hive FusionInsight Hive Apache Hive |
支持从Hive导出数据,使用JDBC接口抽取数据。 Hive作为数据源,CDM自动使用Hive数据分片文件进行数据分区。 | 参见配置Hive源端参数。 |
| DLI | 支持从DLI导出数据。 | 参见配置DLI源端参数。 |
| FTP SFTP |
支持以CSV、JSON或二进制格式抽取FTP/SFTP的数据。 | 参见配置FTP/SFTP源端参数。 |
| HTTP | 用于读取一个公网HTTP/HTTPS URL的文件,包括第三方对象存储的公共读取场景和网盘场景。 当前只支持从HTTP URL导出数据,不支持导入。 | 参见配置HTTP源端参数。 |
| 数据仓库DWS 云数据库MySQL 云数据库SQL Server 云数据库PostgreSQL |
支持从云端的数据库服务导出数据。 | 从这些数据源导出数据时,CDM使用JDBC接口抽取数据,源端作业参数相同,详细请 参见配置作业源端参数文档中的 配置常见关系数据库源端参数。 |
| FusionInsight LibrA | 支持从FusionInsight LibrA导出数据。 | 从这些数据源导出数据时,CDM使用JDBC接口抽取数据,源端作业参数相同,详细请 参见配置作业源端参数文档中的 配置常见关系数据库源端参数。 |
| MySQL PostgreSQL Oracle Microsoft SQL Server SAP HANA MYCAT 分库 |
这些非云服务的数据库,既可以是用户在本地数据中心自建的数据库,也可以是用户在ECS上部署的,还可以是第三方云上的数据库服务。 | 从这些数据源导出数据时,CDM使用JDBC接口抽取数据,源端作业参数相同,详细请 参见配置作业源端参数文档中的 配置常见关系数据库源端参数。 |
| MongoDB 文档数据库服务(DDS) |
支持从MongoDB或DDS导出数据。 | 参见配置MongoDB/DDS源端参数。 |
| Redis | 支持从开源Redis导出数据。 | 参见配置Redis源端参数。 |
| Apache Kafka DMS Kafka MRS Kafka |
仅支持导出数据到云搜索服务。 | 参见配置Kafka/DMS Kafka源端参数。 |
| 云搜索服务 Elasticsearch |
支持从云搜索服务或Elasticsearch导出数据。 | 参见配置Elasticsearch或云搜索服务源端参数。 |
5.配置目的端作业参数,根据目的端数据类型配置对应的参数,具体下表所示。
目的端作业参数说明
| 目的端类型 | 说明 | 参数配置 |
|---|---|---|
| OBS | 支持使用CSV或二进制格式批量传输大量文件到OBS。 | 参见配置OBS源端参数。 |
| MRS HDFS | 导入数据到HDFS时,支持设置压缩格式。 | 参见配置HDFS源端参数。 |
| MRS HBase CloudTable | 支持导入数据到HBase,创建新HBase表时支持设置压缩算法。 | 参见配置HBase/CloudTable源端参数。 |
| MRS Hive | 支持快速导入数据到MRS的Hive。 | 参见配置Hive源端参数。 |
| 数据湖探索(DLI) | 支持导入数据到DLI服务。 | 参见配置DLI目的端参数。 |
| 数据仓库DWS 云数据库MySQL 云数据库SQL Server 云数据库PostgreSQL |
支持导入数据到云端的数据库服务。 | 使用JDBC接口导入数据,参见配置常见关系数据库目的端参数。 |
| 文档数据库服务(DDS) | 支持导入数据到DDS,不支持导入到本地MongoDB。 | 参见配置DDS目的端参数。 |
| 分布式缓存服务(DCS) | 支持导入数据到DCS,支持“String”或“Hashmap”两种值存储方式。不支持导入数据到本地Redis。 | 参见配置DCS目的端参数。 |
| 云搜索服务(CSS) | 支持导入数据到云搜索服务。 | 参见配置云搜索服务目的端参数。 |
6.作业参数配置完成后,单击“下一步”进入字段映射的操作页面。
如果是文件类数据源(FTP/SFTP/HDFS/OBS)之间相互迁移数据,且源端“文件格式”配置为“二进制格式”(即不解析文件内容直接传输),则没有字段映射这一步骤。
其他场景下,CDM会自动匹配源端和目的端数据表字段,需用户检查字段映射关系和时间格式是否正确,例如:源字段类型是否可以转换为目的字段类型。

说明
- 如果字段映射关系不正确,用户可以通过拖拽字段来调整映射关系。
- 如果在字段映射界面,CDM通过获取样值的方式无法获得所有列(例如从HBase/CloudTable/MongoDB导出数据时,CDM有较大概率无法获得所有列),则可以单击
 后选择“添加新字段”来手动增加,确保导入到目的端的数据完整。
后选择“添加新字段”来手动增加,确保导入到目的端的数据完整。 - 如果是导入到数据仓库服务(DWS),则还需在目的字段中选择分布列,建议按如下顺序选取分布列:
- 有主键可以使用主键作为分布列。
(1)多个数据段联合做主键的场景,建议设置所有主键作为分布列。
(2)在没有主键的场景下,如果没有选择分布列,DWS会默认第一列作为分布列,可能会有数据倾斜风险。
7.CDM支持字段内容转换,如果需要可单击操作列下 ,进入转换器列表界面,再单击“新建转换器”。
,进入转换器列表界面,再单击“新建转换器”。
图 新建转换器
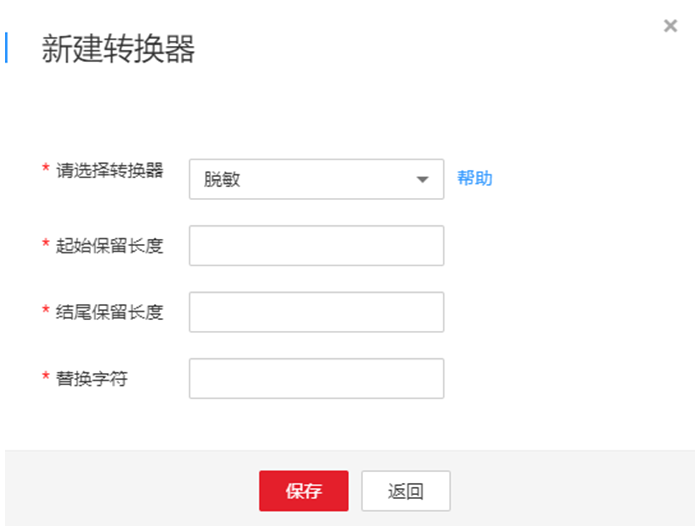
CDM支持以下转换器:
- 脱敏:隐藏字符串中的关键数据。
例如要将“12345678910”转换为“123****8910”,则参数配置如下:
−“起始保留长度”为“3”。
−“结尾保留长度”为“4”。
−“替换字符”为“*”。
- 去前后空格:自动删除字符串前后的空值。
- 字符串反转:自动反转字符串,例如将“ABC”转换为“CBA”。
- 字符串替换:将选定的字符串替换。
- 表达式转换:使用JSP表达式语言(Expression Language)对当前字段或整行数据进行转换。
- 去换行:将字段中的换行符(\n、\r、\r\n)删除。
8.单击“下一步”配置任务参数,单击“显示高级属性”展开可选参数。
详见下图:任务参数
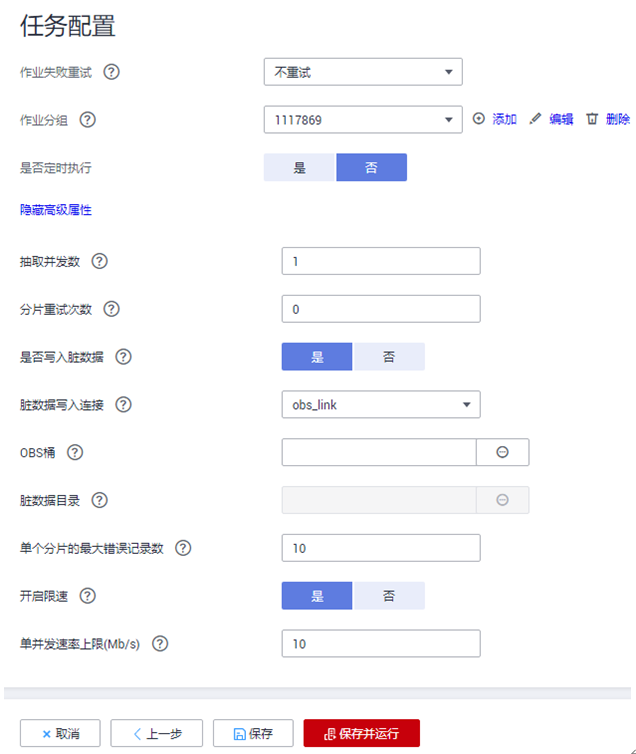
各参数说明如下表所示。
任务配置参数
| 参数 | 说明 | 取值样例 |
|---|---|---|
| 作业失败重试 | 如果作业执行失败,可选择自动重试三次或者不重试。 建议仅对文件类作业或启用了导入阶段表的数据库作业配置自动重试,避免自动重试重复写入数据导致数据不一致。 说明 如果通过DataArts Studio数据开发使用参数传递并调度CDM迁移作业时,不能在CDM迁移作业中配置“作业失败重试”参数,如有需要请在数据开发中的CDM节点配置“失败重试”参数。 |
不重试 |
| 作业分组 | 选择作业的分组,默认分组为“DEFAULT”。在CDM“作业管理”界面,支持作业分组显示、按组批量启动作业、按分组导出作业等操作。 | DEFAULT |
| 是否定时执行 | 如果选择“是”,可以配置作业自动启动的时间、重复周期和有效期,具体请参见配置定时任务。 说明 如果通过DataArts Studio数据开发调度CDM迁移作业,此处也配置了定时任务,则两种调度均会生效。为了业务运行逻辑统一和避免调度冲突,推荐您启用数据开发调度即可,无需配置CDM定时任务。 |
否 |
| 抽取并发数 | 设置同时执行的抽取任务数。并发抽取数取值范围为1-300,若配置过大,则以队列的形式进行排队。 CDM迁移作业的抽取并发量,与集群规格和表大小有关。 按集群规格建议每1CUs(1CUs=1核4G)配置为4。 表每行数据大小为1MB以下的可以多并发抽取,超过1MB的建议单线程抽取数据。 说明 迁移的目的端为文件时,CDM不支持多并发,此时应配置为单进程抽取数据。 单作业的抽取并发数,受到作业“配置管理”中所配置的“最大抽取并发数”影响。“最大抽取并发数”配置的是抽取并发总数。 |
1 |
| 加载(写入)并发数 | 加载(写入)时并发执行的Loader数量。 仅当HBase或Hive作为目的数据源时该参数才显示。 |
3 |
| 分片重试次数 | 每个分片执行失败时的重试次数,为0表示不重试。 | 0 |
| 是否写入脏数据 | 选择是否记录脏数据,默认不记录脏数据。 CDM中脏数据指的是数据格式非法的数据。当源数据中存在脏数据时,建议您打开此配置。否则可能导致迁移作业失败。 |
是 |
| 脏数据写入连接 | 当“是否写入脏数据”为“是”才显示该参数。 脏数据要写入的连接,目前只支持写入到OBS连接。 |
obs_link |
| OBS桶 | 当“脏数据写入连接”为OBS类型的连接时,才显示该参数。 写入脏数据的OBS桶的名称。 |
dirtydata |
| 脏数据目录 | “是否写入脏数据”选择为“是”时,该参数才显示。 OBS上存储脏数据的目录,只有在配置了脏数据目录的情况下才会记录脏数据。 用户可以进入脏数据目录,查看作业执行过程中处理失败的数据或者被清洗过滤掉的数据,针对该数据可以查看源数据中哪些数据不符合转换、清洗规则。 |
/user/dirtydir |
| 单个分片的最大错误记录数 | 当“是否写入脏数据”为“是”才显示该参数。 单个map的错误记录超过设置的最大错误记录数则任务自动结束,已经导入的数据不支持回退。推荐使用临时表作为导入的目标表,待导入成功后再改名或合并到最终数据表。 |
0 |
| 开启限速 | 设置限速可以保护源端读取压力,速率代表CDM传输速率,而非网卡流量。 | 是 |
| 单并发速率上限(Mb/s) | 开启限速情况下设置的单并发速率上限值。 | 20 |
9.单击“保存”,或者“保存并运行”回到作业管理界面,可查看作业状态。
说明
作业状态有New,Pending,Booting,Running,Failed,Succeeded。
其中“Pending”表示正在等待系统调度该作业,“Booting”表示正在分析待迁移的数据。

