适用场景
当您进行作业开发时,如果某些任务的参数有差异、但处理逻辑全部一致,在这种情况下您可以通过For Each算子避免重复开发作业。
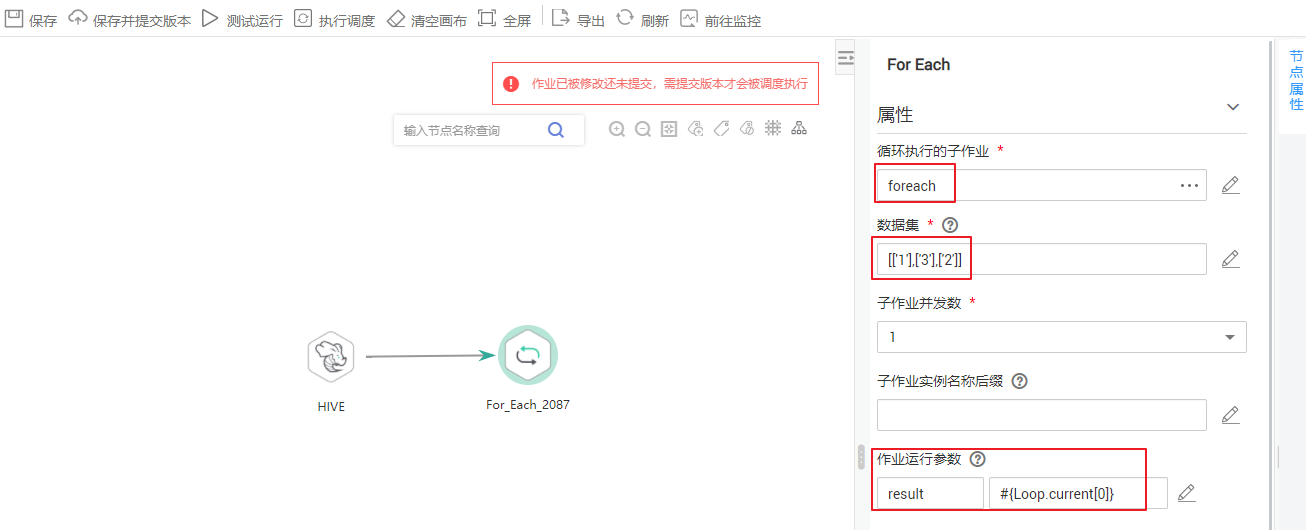
For Each算子可指定一个子作业循环执行,并通过数据集对子作业中的参数进行循环替换。关键参数如下:
-
子作业:选择需要循环执行的作业。
-
数据集:即不同子任务的参数值的集合。可以是给定的数据集,如“[['1'],['3'],['2']] ”;也可以是EL表达式如
#{Job.getNodeOutput('preNodeName')}即前一个节点的输出值。
-
作业运行参数:参数名即子作业中定义的变量;参数值一般配置为数据集中的某组数据,每次运行中会将参数值传递到子作业以供使用。例如参数值填写为:#{Loop.current[0]},即将数据集中每组数据的第一个数值遍历传递给子作业。
For Each算子举例如下图所示。从图中可以看出,子作业“foreach”中的参数名为“result”,参数值为一维数组数据集“[['1'],['3'],['2']] ”的遍历(即第一次循环为1,第二次循环为3,第三次循环为2)。
for each算子

For Each算子与EL表达式
要想使用好For Each算子,您必须对EL表达式有所了解。EL表达式用法请参考表达式概述。
下面为您展示For Each算子常用的一些EL表达式。
- #{Loop.dataArray} :For循环算子输入的数据集,是一个二维数组。
- #{Loop.current}:由于For循环算子在处理数据集的时候,是一行一行进行处理的,那Loop.current就表示当前处理到的某行数据,Loop.current是一个一维数组,一般定义格式为#{Loop.current[0]}、#{Loop.current[1]}或其它,0表示遍历到当前行的第一个值。
- #{Loop.offset}:For循环算子在处理数据集时当前的偏移量,从0开始。
- #{Job.getNodeOutput('preNodeName')}:获取前面节点的输出。
使用案例
案例场景
因数据规整要求,需要周期性地将多组DLI源数据表数据导入到对应的DLI目的表,如下表所示。
需要导入的列表情况
| 源数据表名 | 目的表名 |
|---|---|
| a_new | a |
| b_2 | b |
| c_3 | c |
| d_1 | d |
| c_5 | e |
| b_1 | f |
如果通过SQL节点分别执行导入脚本,需要开发大量脚本和节点,导致重复性工作。在这种情况下,我们可以使用For Each算子进行循环作业,节省开发工作量。
配置方法
- 准备源表和目的表。为了便于后续作业运行验证,需要先创建DLI源数据表和目的表,并给源数据表插入数据。
- 创建DLI表。您可以在DataArts Studio数据开发中,新建DLI SQL脚本执行以下SQL命令,也可以在数据湖探索(DLI)服务控制台中的SQL编辑器中执行以下SQL命令:
/* 创建数据表 */
CREATE TABLE a_new (name STRING, score INT) STORED AS PARQUET;
CREATE TABLE b_2 (name STRING, score INT) STORED AS PARQUET;
CREATE TABLE c_3 (name STRING, score INT) STORED AS PARQUET;
CREATE TABLE d_1 (name STRING, score INT) STORED AS PARQUET;
CREATE TABLE c_5 (name STRING, score INT) STORED AS PARQUET;
CREATE TABLE b_1 (name STRING, score INT) STORED AS PARQUET;
CREATE TABLE a (name STRING, score INT) STORED AS PARQUET;
CREATE TABLE b (name STRING, score INT) STORED AS PARQUET;
CREATE TABLE c (name STRING, score INT) STORED AS PARQUET;
CREATE TABLE d (name STRING, score INT) STORED AS PARQUET;
CREATE TABLE e (name STRING, score INT) STORED AS PARQUET;
CREATE TABLE f (name STRING, score INT) STORED AS PARQUET;
- 给源数据表插入数据。您可以在DataArts Studio数据开发模块中,新建DLI SQL脚本执行以下SQL命令,也可以在数据湖探索(DLI)服务控制台中的SQL编辑器中执行以下SQL命令:
/* 源数据表插入数据 */
INSERT INTO a_new VALUES ('ZHAO','90'),('QIAN','88'),('SUN','93');
INSERT INTO b_2 VALUES ('LI','94'),('ZHOU','85');
INSERT INTO c_3 VALUES ('WU','79');
INSERT INTO d_1 VALUES ('ZHENG','87'),('WANG','97');
INSERT INTO c_5 VALUES ('FENG','83');
INSERT INTO b_1 VALUES ('CEHN','99');
- 准备数据集数据。您可以通过以下方式之一获取数据集:
- 您可以将上表数据导入到DLI表中,然后将SQL脚本读取的结果作为数据集。
- 您可以将上表数据保存在OBS的CSV文件中,然后通过DLI SQL或DWS SQL创建OBS外表关联这个CSV文件,然后将OBS外表查询的结果作为数据集。DLI创建外表请参见,DWS创建外表请参见。
- 您可以将上表数据保存在HDFS的CSV文件中,然后通过HIVE SQL创建Hive外表关联这个CSV文件,然后将HIVE外表查询的结果作为数据集。DLI创建外表请参见。
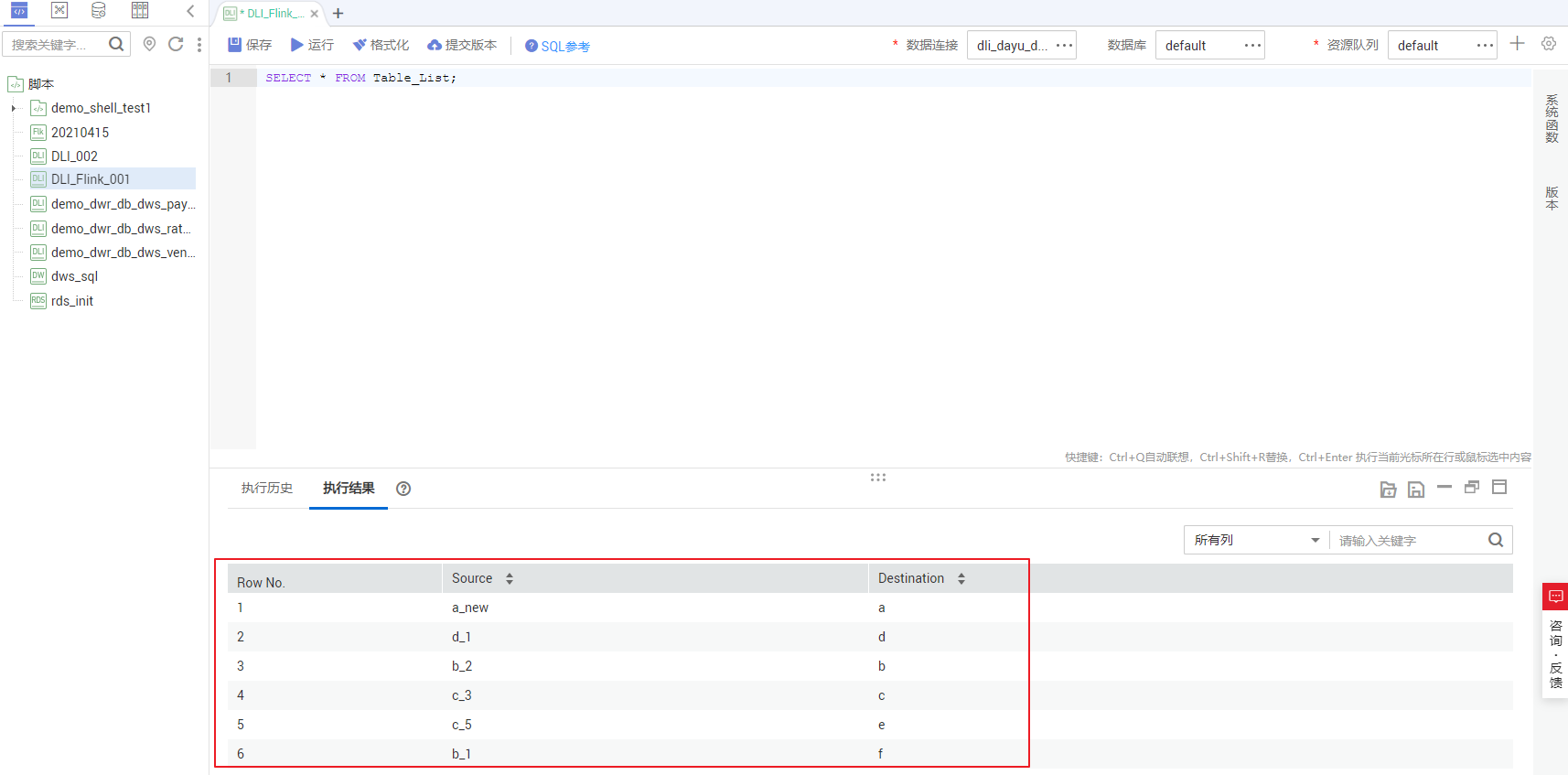
本例以方式1进行说明,将上表中的数据导入到DLI表(Table_List)中。您可以在DataArts Studio数据开发模块中,新建DLI SQL脚本执行以下SQL命令导入数据,也可以在数据湖探索(DLI)服务控制台中的SQL编辑器中执行以下SQL命令:
/* 创建数据表TABLE_LIST,然后插入表1数据,最后查看生成的表数据 */
CREATE TABLE Table_List (Source STRING, Destination STRING) STORED AS PARQUET;
INSERT INTO Table_List VALUES ('a_new','a'),('b_2','b'),('c_3','c'),('d_1','d'),('c_5','e'),('b_1','f');
SELECT * FROM Table_List;
生成的Table_List表数据如下:
详见下图:Table_List表数据

- 创建要循环运行的子作业ForeachDemo。在本次操作中,定义循环执行的是一个包含了DLI SQL节点的任务。
- 进入DataArts Studio数据开发模块选择“作业开发”页面,新建作业ForeachDemo,然后选择DLI SQL节点,编排下图所示的作业。
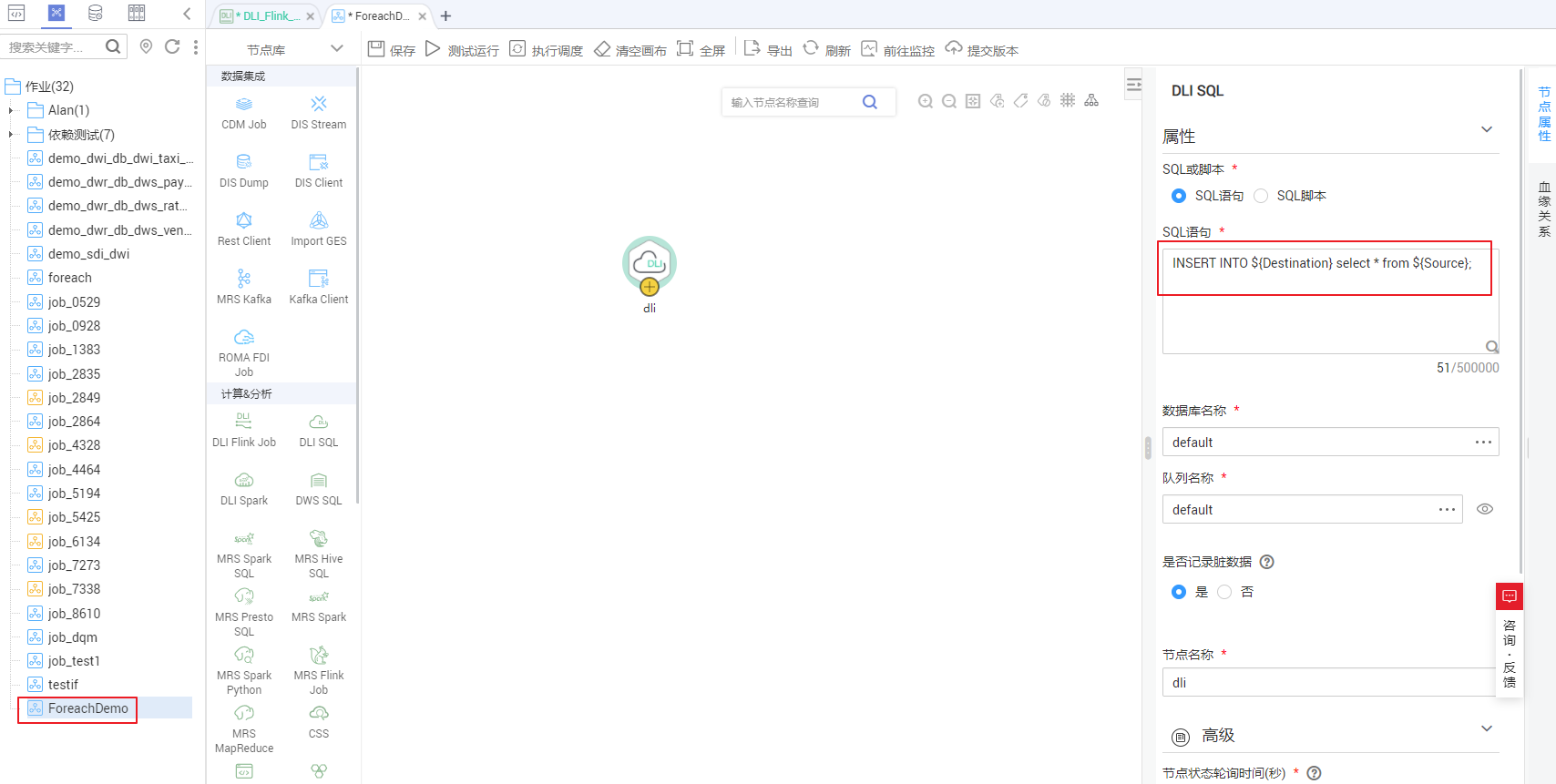
DLI SQL的语句中把要替换的变量配成{}这种参数的形式。在下面的SQL语句中,所做的操作是把{Source}表中的数据全部导入{Destination}中,{fromTable}、${toTable} 就是要替换的变量参数。SQL语句为:
INSERT INTO **{Destination} select * from **{Source};
说明此处不能使用EL表达式#{Job.getParam("job_param_name")} ,因为此表达式只能直接获取当前作业里配置的参数的value,并不能获取到父作业传递过来的参数值,也不能获取到工作空间里面配置的全局变量,作用域仅为本作业。
而表达式${job_param_name},既可以获取到父作业传递过来的参数值,也可以获取到全局配置的变量。
详见下图:循环执行子作业

- 配置完成SQL语句后,在子作业中配置作业参数。此处仅需要配置参数名,用于主作业ForeachDemo_master中的For Each节点识别子作业参数;参数值无需填写。
详见下图:配置子作业参数


- 配置完成后保存作业。
- 创建For Each算子所在的主作业ForeachDemo_master。
- 进入DataArts Studio数据开发模块选择“作业开发”页面,新建数据开发主作业ForeachDemo_master。选择DLI SQL节点和For Each节点,选中连线图标

 并拖动,编排下图所示的作业。
并拖动,编排下图所示的作业。
详见下图:编排作业

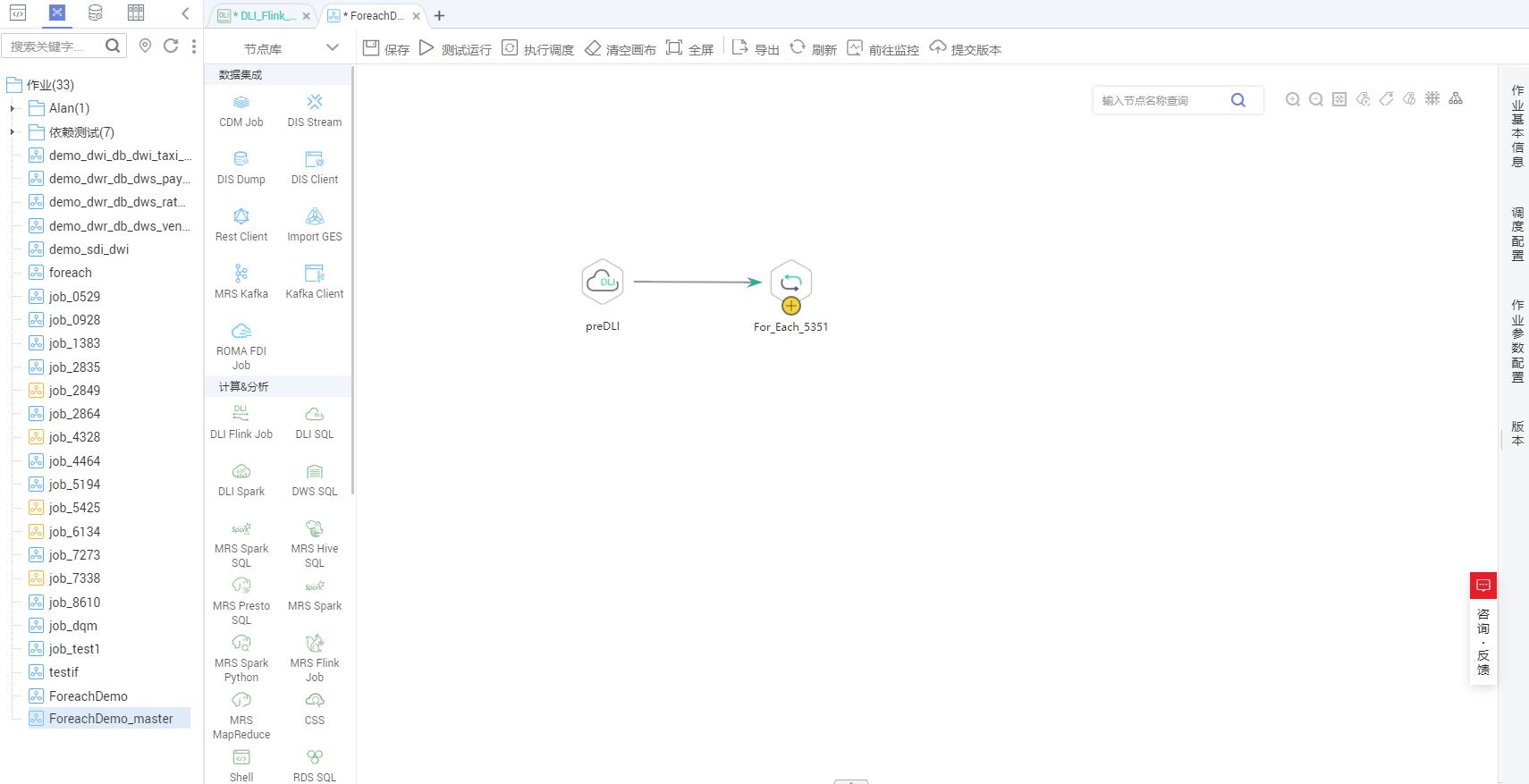
- 配置DLI SQL节点属性,此处配置为SQL语句,语句内容如下所示。DLI SQL节点负责读取DLI表Table_List中的内容作为数据集。
SELECT * FROM Table_List;
详见下图:DLI SQL节点配置

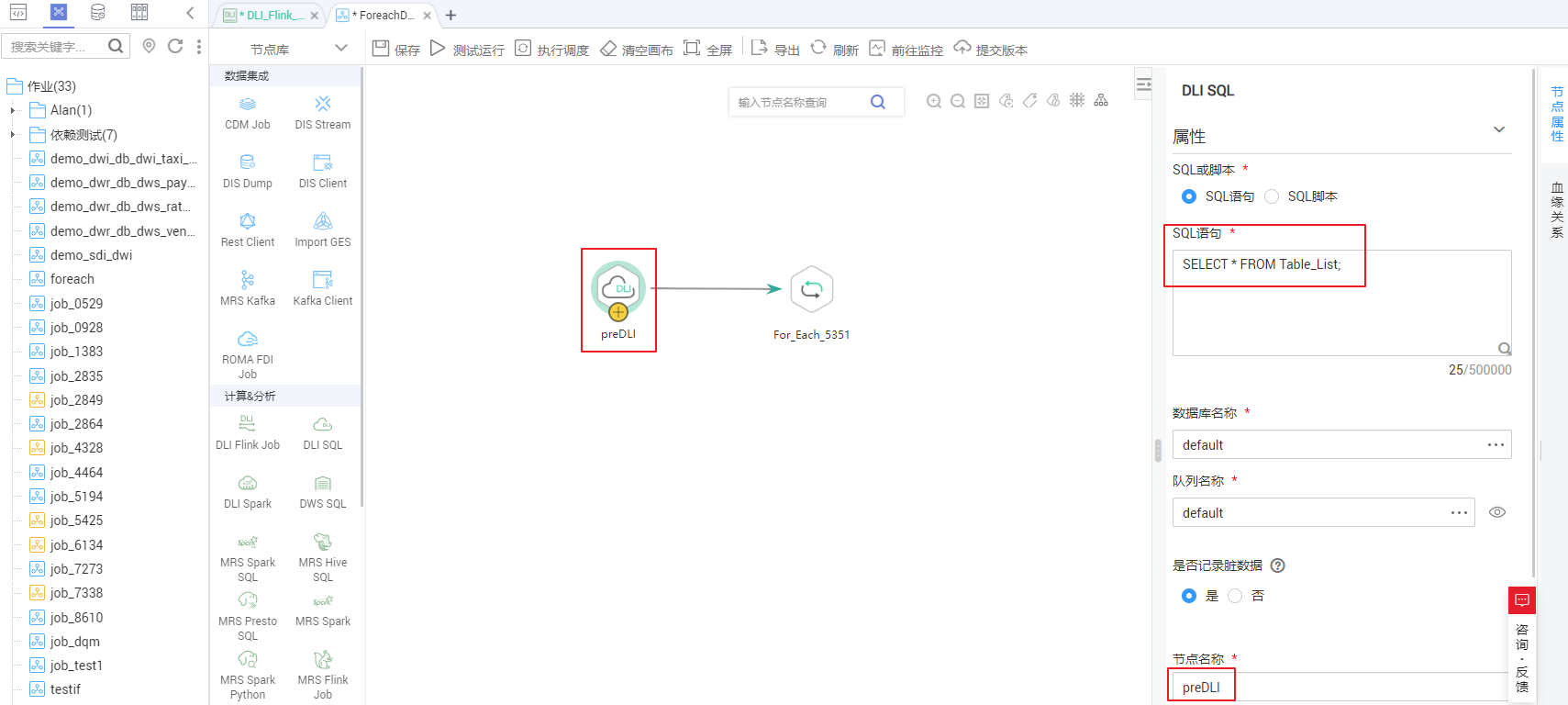
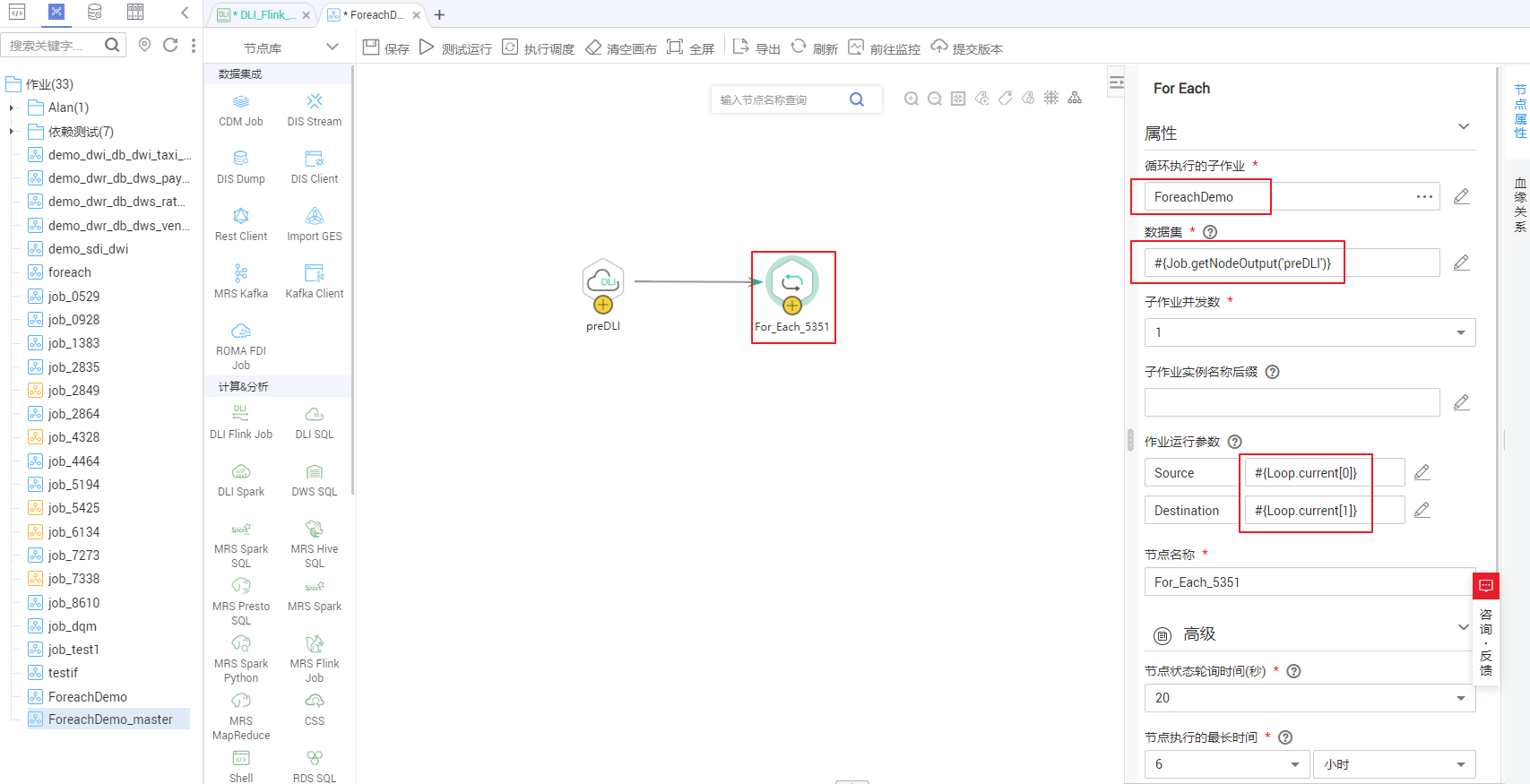
- 配置For Each节点属性。
− 子作业:子作业选择步骤2已经开发完成的子作业“ForeachDemo”。
− 数据集:数据集就是DLI SQL节点的Select语句的执行结果。使用EL表达式 #{Job.getNodeOutput('preDLI')} ,其中preDLI为前一个节点的名称。
− 作业运行参数:用于将数据集中的数据传递到子作业以供使用。Source对应的是数据集Table_List表的第一列,Destination是第二列,所以配置的EL表达式分别为 #{Loop.current[0]} 、 #{Loop.current[1]} 。
详见下图:配置For Each算子

- 配置完成后保存作业。
- 测试运行主作业。
- 点击主作业画布上方的“测试运行”按钮,测试作业运行情况。主作业运行后,会通过For Each节点自动调用运行子作业。
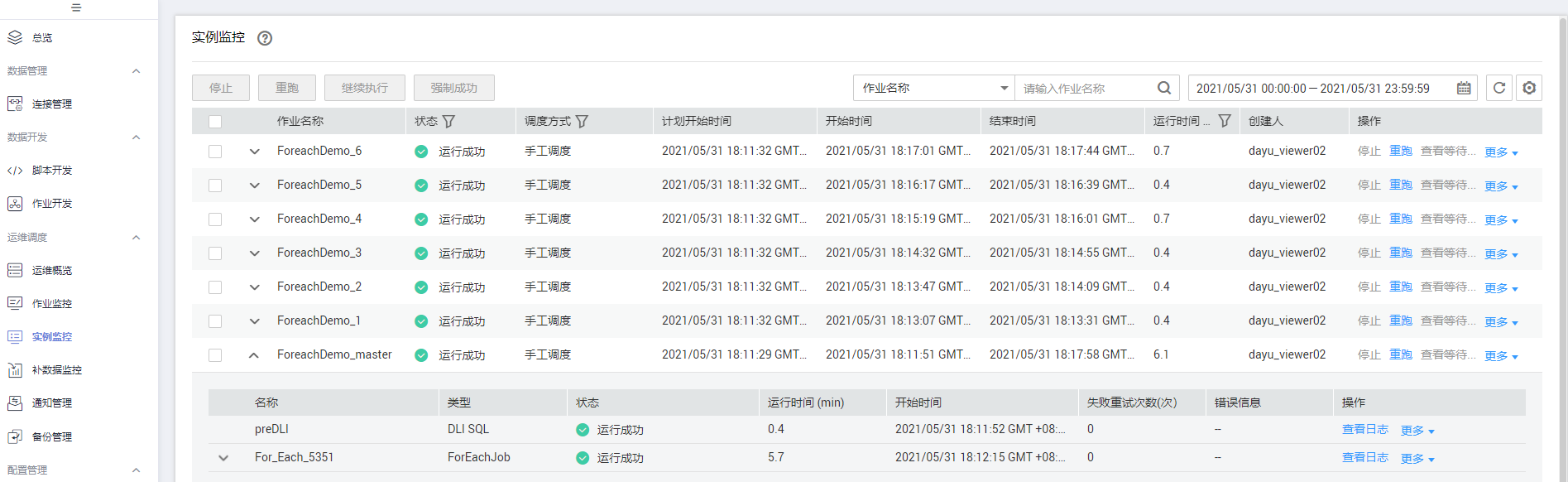
- 点击左侧导航栏中的“实例监控”,进入实例监控中查看作业运行情况。等待作业运行成功后,就能查看For Each节点生成的子作业实例,由于数据集中有6行数据,所以这里就对应产生了6个子作业实例。
详见下图:查看作业实例

- 查看对应的6个DLI目的表中是否已被插入预期的数据。您可以在DataArts Studio数据开发模块中,新建DLI SQL脚本执行以下SQL命令导入数据,也可以在数据湖探索(DLI)服务控制台中的SQL编辑器中执行以下SQL命令:
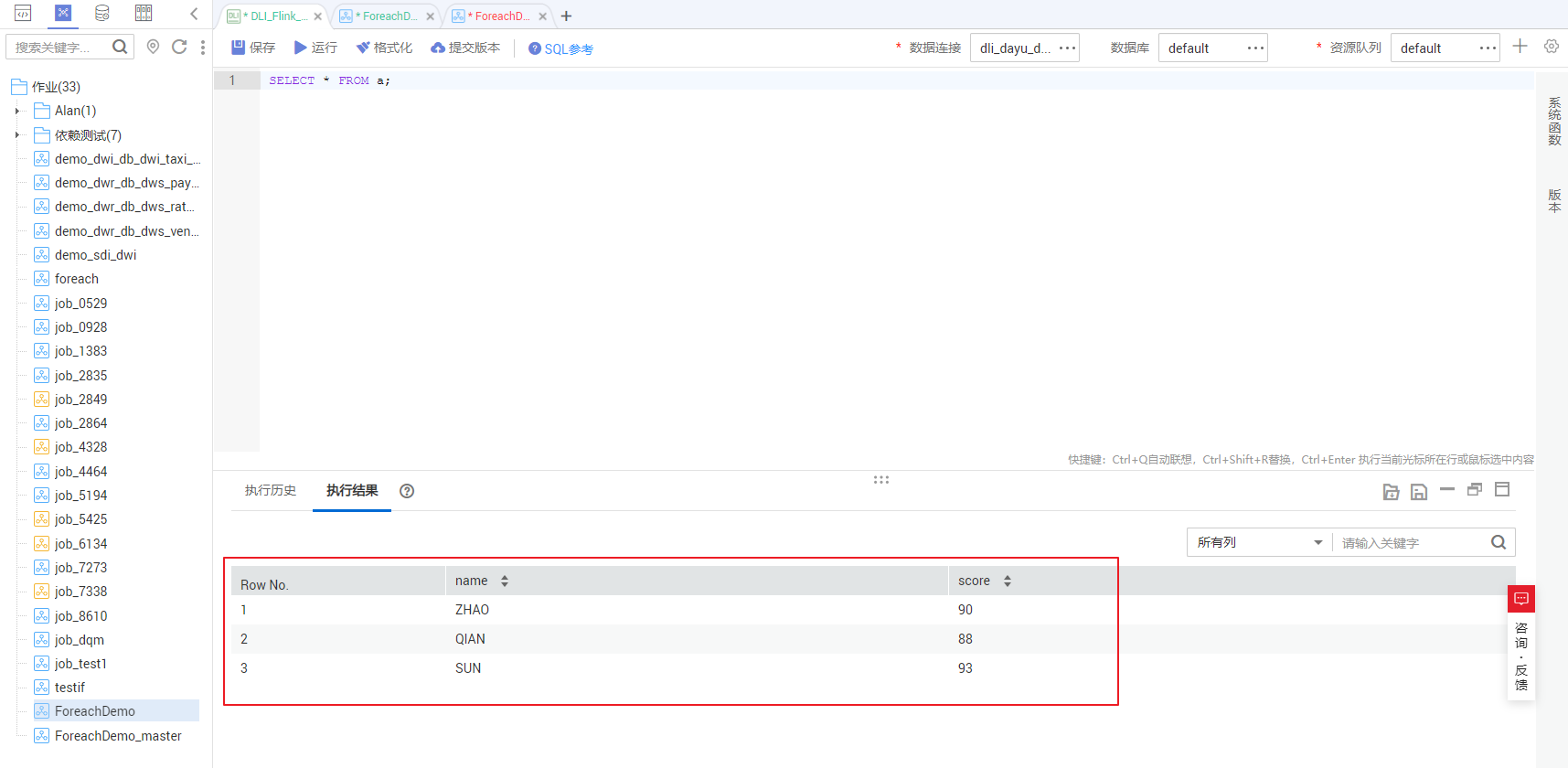
/* 查看表a数据,其他表数据请修改命令后运行 */
SELECT * FROM a;
将查询到的表数据与给源数据表插入数据步骤中的数据进行对比,可以发现数据插入符合预期。
详见下图:目的表数据