开发一个Hive SQL作业
更新时间 2023-08-17 17:14:43
最近更新时间: 2023-08-17 17:14:43
本章节主要介绍DataArts Studio的开发一个Hive SQL作业流程。
本章节介绍如何在数据开发模块上进行Hive SQL开发。
场景说明
数据开发模块作为一站式大数据开发平台,支持多种大数据工具的开发。Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能;可以将SQL语句转换为MapReduce任务进行运行。
环境准备
- 已开通MapReduce服务MRS,并创建MRS集群,为Hive SQL提供运行环境。
- MRS集群创建时,组件要包含Hive。
- 已开通数据集成CDM,并创建CDM集群,为数据开发模块提供数据开发模块与MRS通信的代理。
- CDM集群创建时,需要注意:虚拟私有云、子网、安全组与MRS集群保持一致,确保网络互通。
建立Hive的数据连接
开发Hive SQL前,我们需要在“管理中心 > 数据连接”模块中建立一个到MRS Hive的连接,数据连接名称为“hive1009”。
关键参数说明:
- 集群名:已创建的MRS集群。
- 绑定Agent:已创建的CDM集群。
开发Hive SQL脚本
在“数据开发 > 脚本开发”模块中创建一个Hive SQL脚本,脚本名称为“hive_sql”。在编辑器中输入SQL语句,通过SQL语句来实现业务需求。
开发脚本

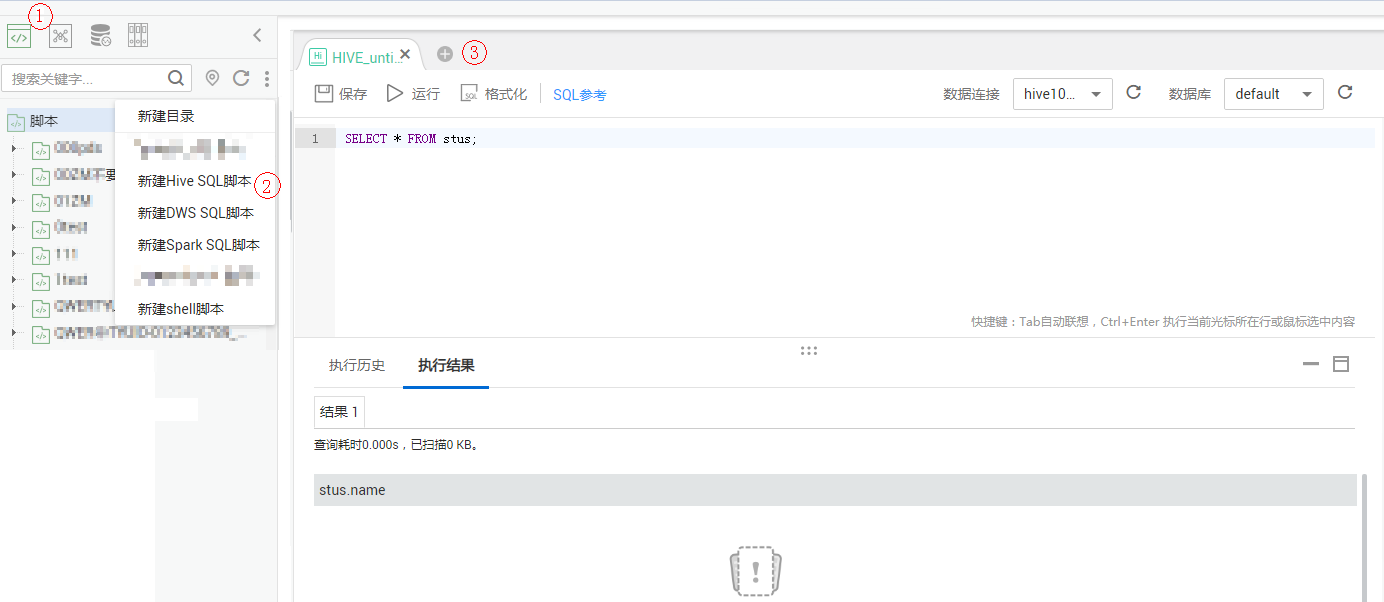
关键说明:
- 上图中的脚本开发区为临时调试区,关闭脚本页签后,开发区的内容将丢失。您可以通过“提交”来保存并提交脚本版本。
- 数据连接:建立Hive的数据连接创建的连接。
开发Hive SQL作业
Hive SQL脚本开发完成后,我们为Hive SQL脚本构建一个周期执行的作业,使得该脚本能定期执行。
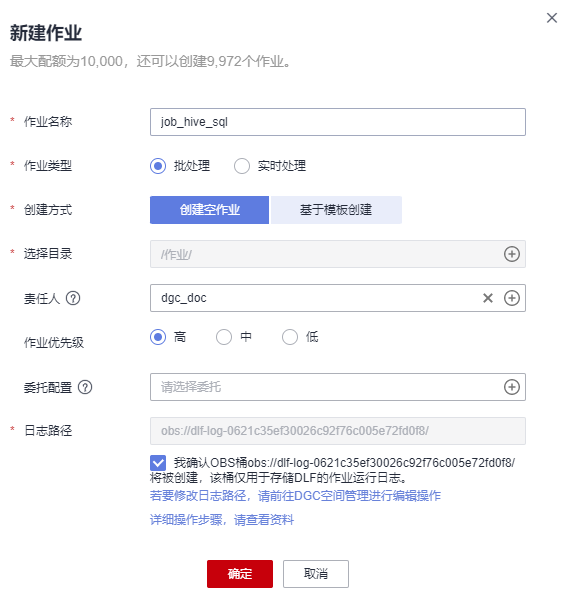
- 创建一个数据开发模块空作业,作业名称为“job_hive_sql”。
创建job_hive_sql作业

- 然后进入到作业开发页面,拖动MRS Hive SQL节点到画布中并单击,配置节点的属性。
配置MRS Hive SQL节点属性

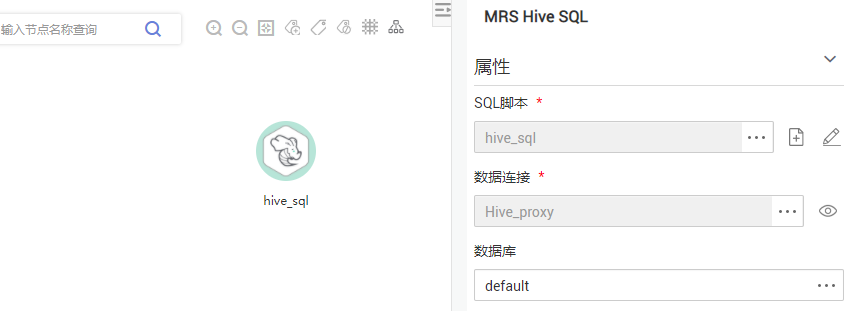
关键属性说明:
- SQL脚本:关联开发Hive SQL脚本中开发完成的Hive SQL脚本“hive_sql”。
- 数据连接:默认选择SQL脚本“hive_sql”中设置的数据连接,支持修改。
- 数据库:默认选择SQL脚本“hive_sql”中设置的数据库,支持修改。
- 节点名称:默认显示为SQL脚本“hive_sql”的名称,支持修改。
- 作业编排完成后,单击

 ,测试运行作业。
,测试运行作业。 - 如果运行成功,单击画布空白处,在右侧的“调度配置”页面,配置作业的调度策略。
配置调度方式

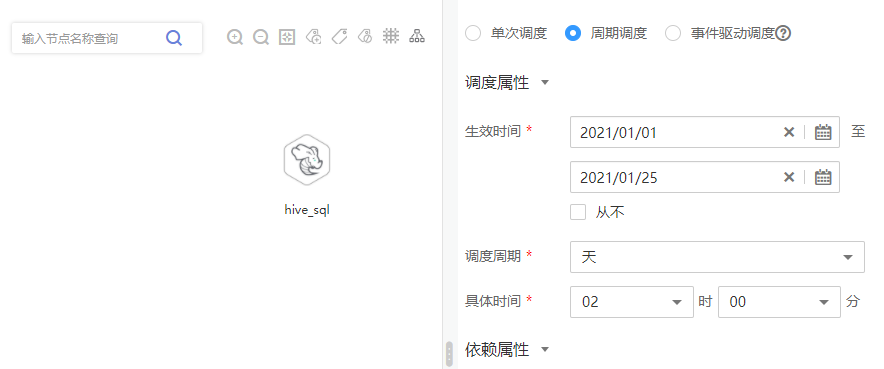
说明2021/01/01至2021/01/25,每天2点执行一次作业。
- 最后我们需要提交版本,执行调度作业,实现作业每天自动运行。

