操作场景
CDM支持在同构、异构数据源之间进行整库迁移,迁移原理与新建表/文件迁移作业相同,关系型数据库的每张表、Redis的每个键前缀、Elasticsearch的每个类型、MongoDB的每个集合都会作为一个子任务并发执行。
支持整库迁移的数据源请参见支持的数据源中整库迁移支持的数据源类型。
自动建表时的字段类型映射
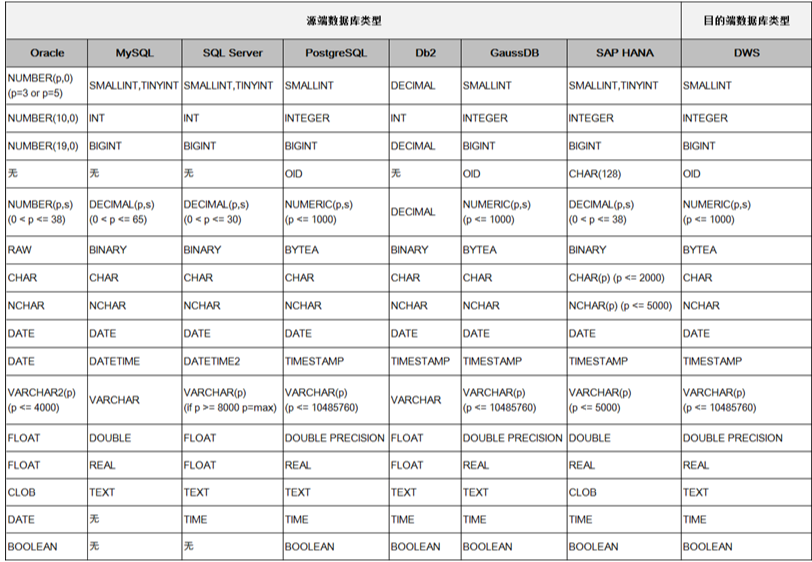
CDM迁移数据库时支持在目的端自动建表。CDM在数据仓库服务(Data Warehouse Service,简称DWS)中自动建表时,DWS的表与源表的字段类型映射关系如下图所示。例如使用CDM将Oracle整库迁移到DWS,CDM在DWS上自动建表,会将Oracle的 NUMBER(3,0) 字段映射到DWS的 SMALLINT 。
详见下图:DWS端自动建表时的字段映射
前提条件
- 已新建连接。
- CDM集群与待迁移数据源可以正常通信。
操作步骤
1.进入CDM主界面,单击左侧导航上的“集群管理”,选择集群后的“作业管理”。
2.选择“整库迁移 > 新建作业”,进入作业参数配置界面。
3.配置源端作业参数,根据待迁移的数据库类型配置对应参数,如下表所示。
源端作业参数
| 源端数据库类型 | 源端参数 | 参数说明 | 取值样例 |
|---|---|---|---|
| DWS FusionInsight LibrA MySQL PostgreSQL SQL Server Oracle SAPHANA MYCAT |
模式或表空间 | “使用SQL语句”选择“否”时,显示该参数,表示待抽取数据的模式或表空间名称。单击输入框后面的按钮可进入模式选择界面,用户也可以直接输入模式或表空间名称。 如果选择界面没有待选择的模式或表空间,请确认对应连接里的帐号是否有元数据查询的权限。 |
schema |
| DWS FusionInsight LibrA MySQL PostgreSQL SQL Server Oracle SAPHANA MYCAT |
Where子句 | 该参数适用于整库迁移中的所有子表,配置子表抽取范围的Where子句,不配置时抽取整表。如果待迁移的表中没有Where子句的字段,则迁移失败。 该参数支持配置为时间宏变量,实现抽取指定日期的数据。 |
age > 18 and age <= 60 |
| DWS FusionInsight LibrA MySQL PostgreSQL SQL Server Oracle SAPHANA MYCAT |
分区字段是否允许空值 | 选择分区字段是否允许空值。 | 是 |
| HIVE | 数据库名称 | 待迁移的数据库名称,源连接中配置的用户需要拥有读取该数据库的权限。 | hivedb |
| HBASE CloudTable |
起始时间 | 起始时间(包含该值)。格式为'yyyy-MM-dd hh:mm:ss',支持dateformat时间宏变量函数。例如:"2017-12-31 20:00:00"或"{dateformat(yyyy-MM-dd, -1, DAY)} 02:00:00"或 {dateformat(yyyy-MM-dd HH:mm:ss, -1, DAY)} | - |
| HBASE CloudTable |
终止时间 | 终止时间(不包含该值)。格式为'yyyy-MM-dd hh:mm:ss',支持dateformat时间宏变量函数。例如:"2018-01-01 20:00:00"或"{dateformat(yyyy-MM-dd, -1, DAY)} 02:00:00"或" {dateformat(yyyy-MM-dd HH:mm:ss, -1, DAY)}" | - |
| Redis | 键过滤字符 | 填写键过滤字符后,将迁移符合条件的键。例如:a*,迁移所有:* | - |
| DDS MongoDB |
数据库名称 | 待迁移的数据库名称,源连接中配置的用户需要拥有读取该数据库的权限。 | mongodb |
| DDS MongDB |
查询筛选 | 创建用于匹配文档的筛选器。例如:{HTTPStatusCode:{ $ gt:"400",$lt:"500"},HTTPMethod:"GET"}。 |
- |
| Elasticsearch CSS |
索引 | 待抽取数据的索引,支持配置为通配符,一次迁移多个符合通配符条件的索引。例如这里配置为cdm*时,CDM将迁移所有名称为cdm开头的索引:cdm01、cdmB3、cdm_45…… 如果源端配置为迁移多个索引时,目的端的作业参数“索引”将不允许配置。 |
cdm* |
4.配置目的端作业参数,根据待导入数据的云服务配置对应参数,如下表所示。
目的端作业参数
| 源端数据库类型 | 源端参数 | 参数说明 | 取值样例 |
|---|---|---|---|
| DWS FusionInsight LibrA MySQL PostgreSQL SQL Server |
- | 整库迁移到关系数据库时,目的端作业参数请参见配置常见关系数据库目的端参数。 | schema |
| MRS HIVE | - | 整库迁移到MRS HIVE时,目的端作业参数请参见配置Hive目的端参数。 | hivedb |
| MRS HBASE CloudTable | - | 整库迁移到MRSHBASE或CloudTable时,目的端作业参数请参见配置HBase/CloudTable目的端参数。 | 是 |
| MRS HDFS | - | 整库迁移到MRS HDFS时,目的端作业参数请参见配置HDFS目的端参数。 | - |
| OBS | - | 整库迁移到OBS时,目的端作业参数请参见配置OBS目的端参数。 | - |
| DCS | - | 整库迁移到DCS时,目的端作业参数请参见配置DCS目的端参数。 | - |
| DDS | 数据库名称 | 待迁移的数据库名称,源连接中配置的用户需要拥有读取该数据库的权限。 | mongodb |
| 迁移行为 | 新增 有则替换,无则新增 |
- | |
| CSS | 索引 | 待抽取数据的索引,支持配置为通配符,一次迁移多个符合通配符条件的索引。 例如这里配置为cdm*时,CDM将迁移所有名称为cdm开头的索引:cdm01、cdmB3、cdm_45…… 如果源端配置为迁移多个索引时,目的端的作业参数“索引”将不允许配置。 |
cdm* |
5.如果是关系型数据库整库迁移,则作业参数配置完成后,单击“下一步”会进入表的选择界面,您可以根据自己的需求选择迁移哪些表到目的端。
6.单击“下一步”配置任务参数。
详见下图:任务参数
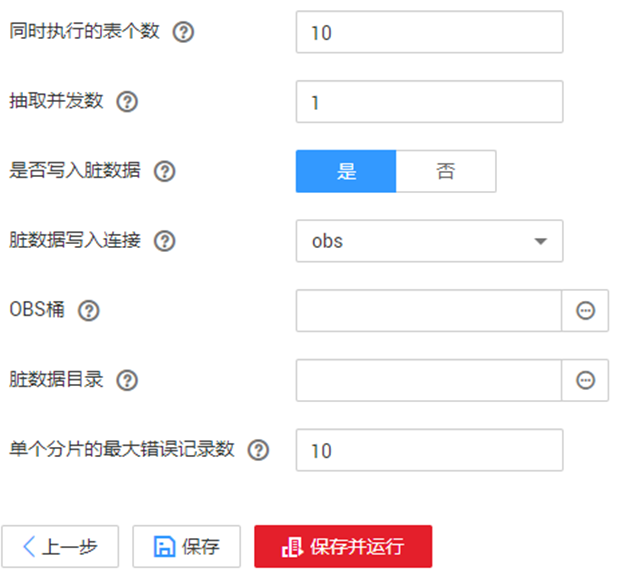
各参数说明如下表所示。
表任务配置参数
| 参数 | 说明 | 取值样例 |
|---|---|---|
| 同时执行的表个数 | 抽取时并发执行的表的数量。 | 3 |
| 抽取并发数 | 设置同时执行的抽取任务数,一般保持默认即可。 | 1 |
| 是否写入脏数据 | 选择是否记录脏数据,默认不记录脏数据。 | 是 |
| 脏数据写入连接 | 当“是否写入脏数据”为“是”才显示该参数。 脏数据要写入的连接,目前只支持写入到OBS连接。 | obs_link |
| OBS桶 | 当“脏数据写入连接”为OBS类型的连接时,才显示该参数。 写入脏数据的OBS桶的名称。 | dirtydata |
| 脏数据目录 | “是否写入脏数据”选择为“是”时,该参数才显示。 OBS上存储脏数据的目录,只有在配置了脏数据目录的情况下才会记录脏数据。 用户可以进入脏数据目录,查看作业执行过程中处理失败的数据或者被清洗过滤掉的数据,针对该数据可以查看源数据中哪些数据不符合转换、清洗规则。 | /user/dirtydir |
| 单个分片的最大错误记录数 | 当“是否写入脏数据”为“是”才显示该参数。 单个map的错误记录超过设置的最大错误记录数则任务自动结束,已经导入的数据不支持回退。推荐使用临时表作为导入的目标表,待导入成功后再改名或合并到最终数据表。 | 0 |
7.单击“保存”,或者“保存并运行”。
作业任务启动后,每个待迁移的表都会生成一个子任务,单击整库迁移的作业名称,可查看子任务列表。



