对SQL脚本进行在线开发、调试和执行,开发完成的脚本也可以在作业中执行(请参见开发作业)。
前提条件
- 已开通相应的云服务并在云服务中创建数据库。Flink SQL脚本不涉及该操作。
- 已创建与脚本的数据连接类型匹配的数据连接,请参见新建数据连接。Flink SQL脚本不涉及该操作。
- 当前用户已锁定该脚本,否则需要通过“抢锁”锁定脚本后才能继续开发脚本。新建或导入脚本后默认被当前用户锁定,详情参见提交版本并解锁章节中的“编辑锁定功能”。
操作步骤
1.登录DataArts Studio控制台。选择实例,点击“进入控制台”,选择对应工作空间的“数据开发”模块,进入数据开发页面。
详见下图:选择数据开发

2.在数据开发主界面的左侧导航栏,选择“数据开发 > 脚本开发”。
3.在脚本目录中,双击脚本名称,进入脚本开发页面。
4.在编辑器上方,选择如下表所示的属性。创建Flink SQL脚本时请跳过此步骤。
SQL脚本属性
| 属性 | 说明 |
|---|---|
| 数据连接 | 选择数据连接。 |
| 数据库 | 选择数据库。 |
| 资源队列 | 选择执行DLI作业的资源队列。当脚本为DLI SQL时,配置该参数。如需新建资源队列,请参考以下方法: 单击   ,进入DLI的“队列管理”页面新建资源队列。 ,进入DLI的“队列管理”页面新建资源队列。前往DLI管理控制台进行新建。 说明 DLI提供默认资源队列“default”,该资源队列不支持insert、load、cat命令。 如需以“key/value”的形式设置提交SQL作业的属性,请单击   。最多可设置10个属性,属性说明如下: 。最多可设置10个属性,属性说明如下:dli.sql.autoBroadcastJoinThreshold(自动使用BroadcastJoin的数据量阈值) dli.sql.shuffle.partitions(指定Shuffle过程中Partition的个数) dli.sql.cbo.enabled(是否打开CBO优化策略) dli.sql.cbo.joinReorder.enabled(开启CBO优化时,是否允许重新调整join的顺序) dli.sql.multiLevelDir.enabled(OBS表的指定目录或OBS表分区表的分区目录下有子目录时,是否查询子目录的内容;默认不查询) dli.sql.dynamicPartitionOverwrite.enabled(在动态分区模式时,只会重写查询中的数据涉及的分区,未涉及的分区不删除) |
5.在编辑器中输入SQL语句(支持输入多条SQL语句)。
说明
需要注意,使用SQL语句获取的系统日期和通过数据库工具获取的系统日期是不一样,查询结果存到数据库是以YYYY-MM-DD格式,而页面显示查询结果是经过转换后的格式。
SQL语句之间以“;”分隔。如果其它地方使用“;”,请通过“\”进行转义。例如:
select 1;
select * from a where b="dsfa\;"; --example 1\;example 2.
为了方便脚本开发,数据开发模块提供了如下能力:
− 脚本编辑器支持使用如下快捷键,以提升脚本开发效率。
- Ctrl + /:注释或解除注释光标所在行或代码块
- Ctrl + S:保存
- Ctrl + Z:撤销
- Ctrl + Y:重做
- Ctrl + F:查找
- Ctrl + Shift + R:替换
- Ctrl + X:剪切,光标未选中时剪切一行
- Alt + 鼠标拖动:列模式编辑,修改一整块内容
- Ctrl + 鼠标点选:多列模式编辑,多行缩进
- Shift + Ctrl + K:删除当前行
- Ctrl + →或Ctrl + ←:向右或向左按单词移动光标
- Ctrl + Home或Ctrl + End:移至当前文件的最前或最后
- Home或End:移至当前行最前或最后
- Ctrl + Shift + L:鼠标双击相同的字符串后,为所有相同的字符串添加光标,实现批量修改
− 支持系统函数功能(当前Flink SQL、Spark SQL、ClickHouse SQL、Presto SQL不支持该功能)。
单击编辑器右侧的“系统函数”,显示该数据连接类型支持的函数,您可以双击函数到编辑器中使用。
− 支持可视化读取数据表生成SQL语句功能(当前Flink SQL、Spark SQL、ClickHouse SQL、Presto SQL不支持该功能)。
单击编辑器右侧的“数据表”,显示当前数据库或schema下的所有表,可以根据您的需要勾选数据表和对应的列名,在右下角点击“生成SQL语句”,生成的SQL语句需要您手动格式化。
− 支持脚本参数(当前仅Flink SQL不支持该功能)。
在SQL语句中直接写入脚本参数,调试脚本时可以在脚本编辑器下方输入参数值。如果脚本被作业引用,在作业开发页面可以配置参数值,参数值支持使用EL表达式(参见表达式概述)。
脚本示例如下,其中str1是参数名称,只支持英文字母、数字、“-”、“_”、“<”和“>”,最大长度为16字符,且参数名称不允许重名。
select ${str1} from data;
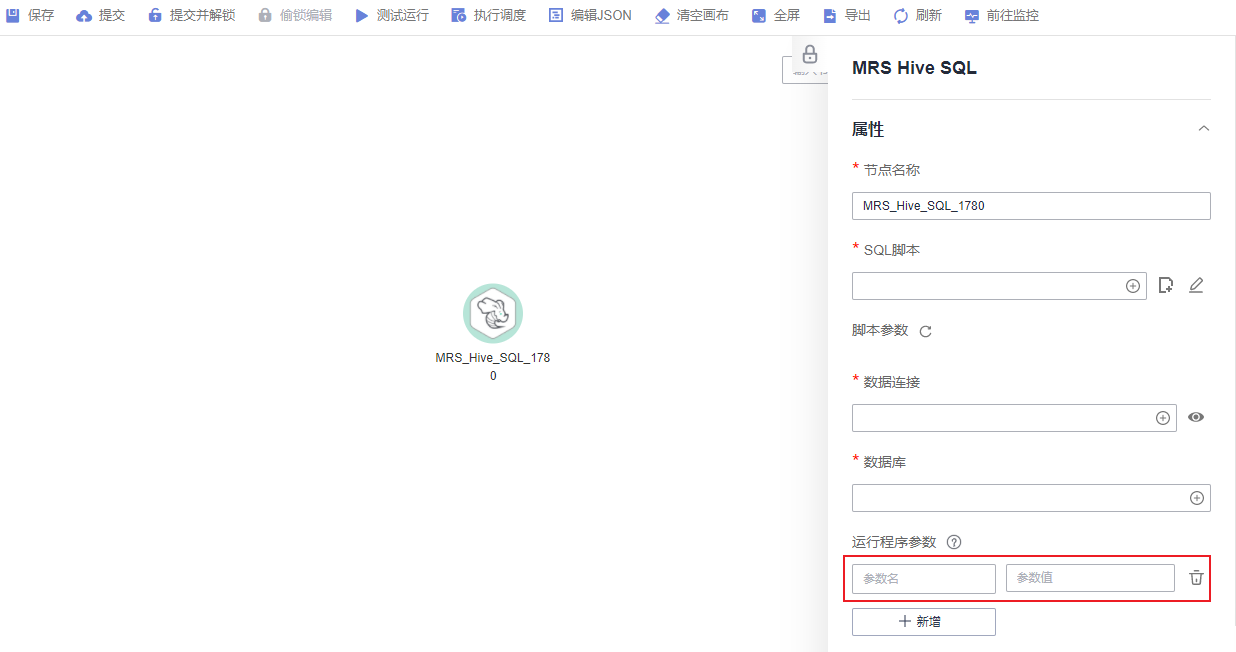
另外,对于MRS Spark SQL和MRS Hive SQL脚本的运行程序参数,除了在SQL脚本中参考语句“set hive.exec.parallel=true;”配置参数,也可以在对应作业节点属性的“运行程序参数”中配置该参数。
详见下图:运行程序参数

− 支持设置脚本责任人
单击编辑器右侧的“脚本基本信息”,可设置脚本的责任人和描述信息。
6.(可选)在编辑器上方,单击“格式化”,格式化SQL语句。创建Flink SQL脚本请跳过此步骤。
7.在编辑器上方,单击“运行”。如需单独执行某部分SQL语句,请选中SQL语句再运行。SQL语句运行完成后,在编辑器下方可以查看脚本的执行历史、执行结果。Flink SQL脚本不涉及,请跳过该步骤。
说明
对于执行结果支持如下操作:
重命名:可通过双击执行结果页签的名称进行重命名,也可通过右键单击执行结果页签的名称,单击重命名。重命名不能超过16个字符。
可通过右键单击执行结果页签的名称关闭当前页签、关闭左侧页签、关闭右侧页签、关闭其它页签、关闭所有页签。
MRS集群为非安全集群、且未限制命令白名单时,在Hive SQL执行过程中,添加application name信息后,则可以方便的根据脚本名称与执行时间在MRS的Yarn管理界面中根据job name找到对应任务。需要注意若默认引擎为tez,则要显式配置引擎为mr,使tez引擎下不生效。
8.在编辑器上方,单击
 ,保存脚本。
,保存脚本。
如果脚本是新建且未保存过的,请配置如下表所示的参数。
保存脚本
| 参数 | 是否必选 | 说明 |
|---|---|---|
| 脚本名称 | 是 | 脚本的名称,只能包含字符:英文字母、数字、中文、中划线、下划线和点号,且长度小于等于128个字符。 |
| 责任人 | 否 | 为该脚本指定责任人。默认为创建脚本的人为责任人。 |
| 描述 | 否 | 脚本的描述信息。 |
| 选择目录 | 是 | 选择脚本所属的目录,默认为根目录。 |
说明如果脚本未保存,重新打开脚本时,可以从本地缓存中恢复脚本内容。
下载或转储脚本执行结果
约束限制 :转储脚本执行结果功能依赖于OBS服务,如无OBS服务,则不支持该功能。
脚本运行成功后,您可以在执行结果页签下载或转储执行结果,仅支持具有拥有DAYU Administrator或Tenant Administrator权限的用户下载和转储。
- 下载结果:下载CSV格式的结果文件到本地。
- 转储结果:转储CSV格式的结果文件到OBS中,请参见下表。
说明Flink SQL脚本、RDS SQL脚本、Shell脚本的执行结果,不支持转储。
转储结果
| 参数 | 是否必选 | 说明 |
|---|---|---|
| 数据格式 | 是 | 目前仅支持导出CSV格式的结果文件。 |
| 资源队列 | 否 | 选择执行导出操作的DLI队列。当脚本为DLI SQL时,配置该参数。 |
| 压缩格式 | 否 | 选择压缩格式。当脚本为DLI SQL时,配置该参数。 none bzip2 deflate gzip |
| 存储路径 | 是 | 设置结果文件的OBS存储路径。选择OBS路径后,您需要在选择的路径后方自定义一个文件夹名称,系统将在OBS路径下创建文件夹,用于存放结果文件。 |
| 覆盖类型 | 否 | 如果“存储路径”中,您自定义的文件夹在OBS路径中已存在,选择覆盖类型。当脚本为DLI SQL时,配置该参数。 覆盖:删除OBS路径中已有的重名文件夹,重新创建自定义的文件夹。 存在即报错:系统返回错误信息,退出导出操作。 |

