多行全文模式
更新时间 2025-11-11 15:02:19
最近更新时间: 2025-11-11 15:02:19
本文主要结构化解析-多行全文模式。
概述
多行全文日志是指一条完整的日志数据可能跨占多行,您需要指定首行正则表达式以进行匹配,当某行日志匹配上预先设置的正则表达式,则认为是一条日志的开头,而下一个行首出现作为该条日志的结束标识符。提取的日志内容同样也会存放在 __message__字段中。
示例
在多行全文模式下,日志数据本身不再进行日志结构化处理,采集器会将日志内容存放在 __message__字段中。如您需要采集的原始数据为:
原始日志:
“2019-12-15 17:13:06,043 [main] ERROR com.test.logging.FooFactory: java.lang.NullPointerException at com.test.logging.FooFactory.createFoo(FooFactory.java:15) at com.test.logging.FooFactoryTest.test(FooFactoryTest.java:11)”行首正则表达式:
\d+-\d+-\d+\s\d+:\d+:\d+,\d+\s.*采集到云日志服务后的日志:
__message__:“2019-12-15 17:13:06,043 [main] ERROR com.test.logging.FooFactory: java.lang.NullPointerException at com.test.logging.FooFactory.createFoo(FooFactory.java:15) at com.test.logging.FooFactoryTest.test(FooFactoryTest.java:11)”
配置方式
在日志接入流程中-创建采集配置步骤中,按如下参数说明配置切割模式: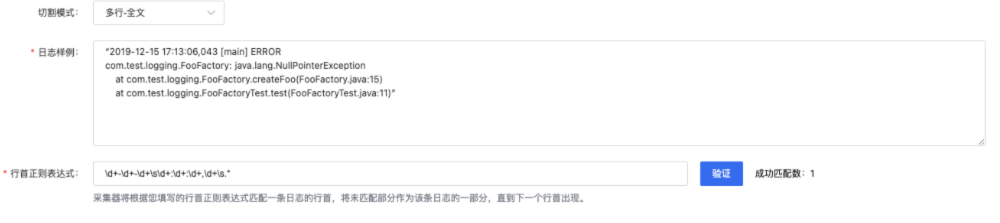
| 参数 | 描述 |
|---|---|
| 切割模式 | 针对原始日志执行分词的模式,选择“多行全文”。 |
| 日志样例 | 输入您需要采集的日志样例。 |
| 首行正则表达式 | 首行正则表达式用于匹配每一条日志的行首,以确认每条日志的开头位置。 输入完成后,点击【验证】,系统将根据您输入的日志样例判断表达式是否通过,以及成功解析的日志条数。 |

