Spark 任务内存不足情况需要根据具体问题进行具体分析。
首先spark统一内存模型将内存分为off-heap和heap两部分内存,每一个部分都可能发生内存不足的情况。
off-heap内存不足的情况
off-heap内存作用
为了进一步优化内存的使用以及提高 Shuffle 时排序的效率,Spark 引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,存储经过序列化的二进制数据。
利用JDK Unsafe API(从 Spark 2.0 开始,在管理堆外的存储内存时不再基于 Tachyon,而是与堆外的执行内存一样,基于 JDK Unsafe API 实现),Spark 可以直接操作系统堆外内存,减少了不必要的内存开销,以及频繁的 GC 扫描和回收,提升了处理性能。堆外内存可以被精确地申请和释放,而且序列化的数据占用的空间可以被精确计算,所以相比堆内内存来说降低了管理的难度,也降低了误差。
off-heap参数和动态扩展机制
Spark堆外内存的大小可以由spark.memory.offHeap.size控制,spark off-heap空间只分为 execution 和 storage 1:1两部分,两部分可以动态扩展。
off-heap不足
目前常用的off-heap常见是 executor端,map task侧 shuffle时候,由于ShuffleExternalSorter占用内存过大,导致内存不足。
此外,在spark native场景中,spark将更多的使用 spark off-heap内存取代heap内存,因此spark off-heap在非shuffle场景下也会占用很多off-heap内存。
如果存在off-heap 内存不足警告,可以酌情添加spark.memory.offHeap.size 或者 降低shuffle 内存缓冲区大小。
heap内存不足的情况
spark将heap内存做如下分割
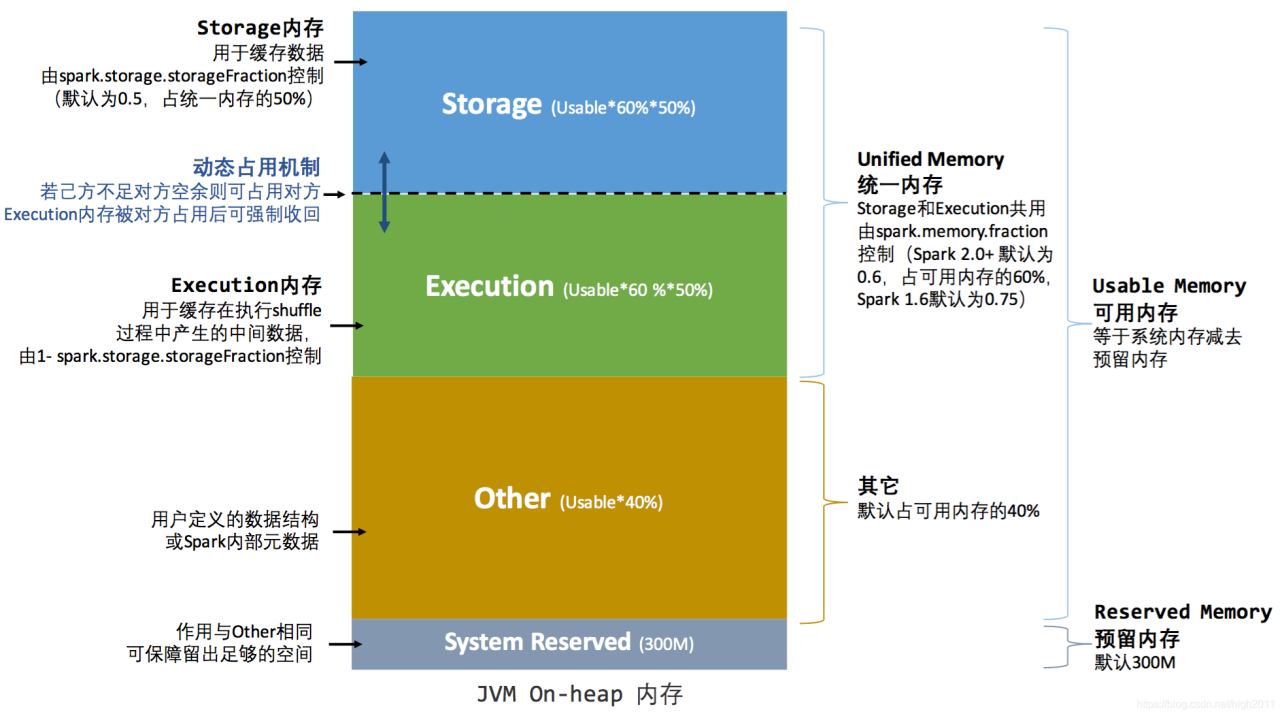
每一个部分超出使用上线都可能产生内存不足的情况。
Spark整体heap内存是由 spark.executor.memory和spark.driver.memory控制的
Spark将spark.xxxx.memory内存分为 user heap(other)、execution heap、storage heap、system heap(300MB)。
spark.memory.fraction 可以将** **spark.xxxx.memory分割出 heap storage 和 heap execution 两部分。
Heap storage
Heap storage作用
Spark Heap Storage内存用于存储spark Rdd cache。
在spark SQL中也可以用于存储 view、或存储 cache table的表。
Heap storage不足
Heap storage不足一般发生在executor端。主要是因为 cache RDD 太多了,因为动态占用机制,占用heap execution空间,导致分配到当前executor的heap execution不够用,从而告警。
我们可以通过spark UI 查看 作业的storage 选项卡,定位告警的executor Id,查看cache的大小,与environment 选项卡中的spark.executor.memory做比对。
这种情况下,我们可以酌情,增加spark.executor.memory,或者uncache 或者 drop view 不需要的RDD 或者cached table。
Heap execution
Heap execution作用
Heap execution 可以用于存储输入数据。
Spark是内存计算,需要将父RDD的partition读入内存中,这个数据将会被blockManager读入。
在spark shuffle map stage 或者 reduce stage都会发生读入操作。
Heap execution 可以用于shuffle 缓冲区 和 序列化反序列化。
Spark的一些使用heap缓冲区进行shuffle的场景需要分配heap space。
Heap execution空间不足
一般是读入的数据太多或者发生了数据倾斜。
spark shuffle map task读入hdfs文件块数据。
发生在shuffle map stage,spark需要读取hdfs 文件块。
这个文件快太大且不可分割,或者数据压缩密度太大,会导致task memory 急速膨胀,超过1/n 的 executor heap space 和 executor storage space总和。(此处的n是spark executor的running task数目)。
如果hdfs文件块可以分割读入task,尝试使用spark.files.maxPartitionBytes去分割读取的hdfs文件 或者 扩大 spark.executor.memory。但是后者不适用于个别hdfs大文件块情况。
如果hdfs 文件块是gzip这种的不可压缩,可能只能扩大spark.files.maxPartitionBytes,或者 在业务上有控制写入hdfs的文件格式是可分割的。
spark shuffle reduce task读入shuffle block数据太多了,也就是发生数据倾斜。
一般shuffle block 都会连续小幅度的拉入 reduce task侧,此时如果溢出,spark 会将这些数据spill disk。
如果出现reduce task读取超大shuffle block 或者 并发读取太快,会导致数据内存膨胀太快,而直接OOM。
此时spark会有task重启机制,会过滤并发过多情况。如果是读入shuffle block太大,则会反复的发生task failed情况。
此时可以适当降低map侧 shuffle write的shuffle block大小,可以尝试增加 shuffle reduce的并行度 或者 尽量使用sortBaseShuffleWriter,使用sortBaseShuffleWriter 可以实现map combiner。
如果发生了数据倾斜
此时倾斜executor不会出现Exception,但是内存heap使用量偏高,会发出内存告警。
这一点可以在web UI的task列表中清晰的看到stage的某一个task相对于其他task,其computing time明显很长。
这种情况下一般是shuffle发生了数据倾斜,首先可以使用map combiner,降低map侧的倾斜的shuffle reduce分区的数据量。
此外,可以通过编程,提取出topk的shuffle reduce 分区的key值,然后将对应shuffle Key的rdd partition打上随机数,做一个均匀分割,然后执行reduceByKey操作,最后去掉随机数,再执行一次reduceByKey。
如果不想这样,可以使用hive。
Heap User
Heap User作用
用户自定义数据结构,这个就是用户使用spark core api 或者 spark sql api过程中使用了其他数据结构进行编程,因而产生了一些heap消耗。
Heap User不足
存在heap不足的情况,一般是用户将task的计算结果,RDD.collect 到driver中的数据结构中,这种情况,需要去使用专门的connector,实现分布式计算和读写。
还有就是用户执行sql的时候,会进行非insert 操作,即直接select读取大表,导致driver内存不足够,这种情况下建议使用limit 操作,或者 使用spark的流式返回功能。

