场景描述
业务侧云数据库TaurusDB实例上以往执行耗时8秒的查询,在11:00后耗时超过30秒。
原因分析
- 查看查询变慢对应的时间段中,实例CPU监控指标并无飙升情况且使用率一直都较低,因此排除了CPU冲高导致查询变慢的可能。
- 分析对应时间段该实例的慢日志,该SQL执行快时其扫描行数为百万级,当SQL执行慢时其扫描行数为千万级,与业务确认该表短期内并无大量数据插入,因此推断执行慢是因为未走索引或选错索引。且通过EXPLAIN查看该SQL的执行计划确实是全表扫描。
图 慢日志

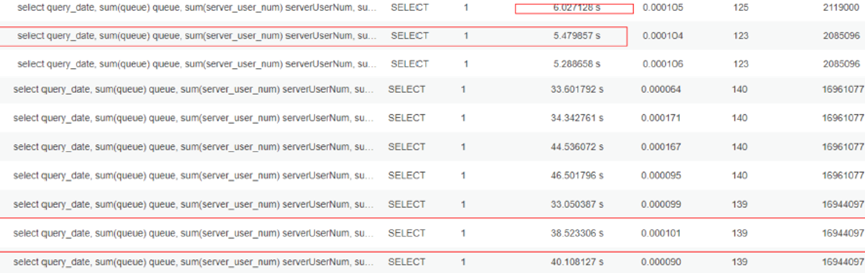
- 在实例上对该表执行SHOW INDEX FROM检查三个字段的基数,。
图 查看基数

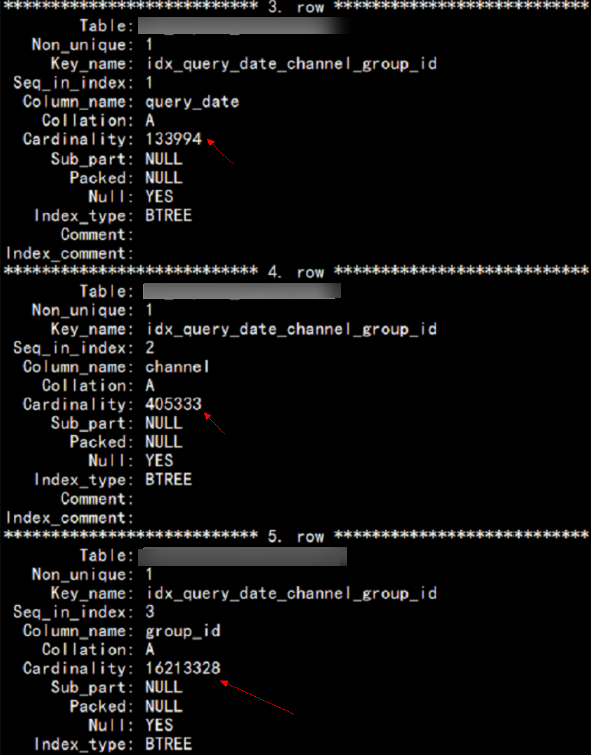
可知基数最小的字段“query_date”在联合索引的第一位,基数最大的字段“group_id”在联合索引最后一位,而且原SQL包含对“query_date”字段的范围查询,导致当索引走到“query_date”就会停止匹配,后面两个字段已经无序,无法走索引。
所以该SQL本质上只能利用到对“query_date”这一列的索引,而且还有可能因为基数太小,导致优化器成本估计时选择了全表扫描。
业务重新创建了联合索引将“group_id”字段放在第一位,“query_date”字段放在最后一位后,查询耗时符合预期。
解决方案
- 查询变慢首先确认是否由于CPU利用率达到性能瓶颈导致执行慢。
- 库表结构设计不合理,索引缺失或索引设置不恰当会导致慢SQL。
- 表数据大批量插入删除等操作可能会导致统计信息未能及时更新,建议定期执行ANALYZE TABLE防止执行计划走错。

