建表时timestamp字段默认值无效
场景描述
客户执行一个建表SQL语句失败,详细SQL语句及报错如下:
CREATE TABLE cluster_membership
(
...
session_start TIMESTAMP DEFAULT '1970-01-01 00:00:01',
...
);
执行失败,失败原因:ERROR 1067: Invalid default value for 'session_start'
原因分析
表字段类型是TIMESTAMP类型,
关于timestamp字段:MySQL会把该字段插入的值从当前时区转换成UTC时间(世界标准时间)存储,查询时,又将其从UTC时间转化为当前时区时间返回
- timestamp类型字段的时间范围:'1970-01-01 00:00:01' UTC -- '2038-01-19 03:14:07' UTC,详见官方文档:
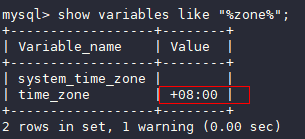
- 使用如下命令,查看当前的时区:
show variables like "%zone%";
- 故障场景中使用的是utc+8时区,如下图,所以timestamp字段默认值需要加8小时才是有效范围,有效支持的范围是从1970-01-01 08:00:01开始;

解决方案
执行命令,修改timestamp字段参数默认值。
session_start TIMESTAMP DEFAULT '1970-01-01 08:00:01',
索引长度限制导致修改varchar长度失败
场景描述
执行alter table修改表结构失败,报错如下:
Specified key was too long; max key length is 3072 bytes
原因分析
- 在“innodb_large_prefix”设置为off的情况下,InnoDB表的单字段索引的最大字段长度不能超过767字节,联合索引的每个字段的长度不能超过767字节,且所有字段长度合计不能超过3072字节。
- 当“innodb_large_prefix”设置为on时,单字段索引最大长度可为3072字节,联合索引合计最大长度可为3072字节。
- 索引长度与字符集相关。使用utf8字符集时,一个字符占用三个字节,在“innodb_large_prefix”参数设置为on情况下,索引的所有字段的长度合计最大为1072个字符。
查看表结构如下:
CREATE TABLE `xxxxx` (
……
`subscription_type` varchar(64) NOT NULL DEFAULT 'DEVICE_EXCEPTION' COMMENT '订阅类型',
`auth_key` varchar(255) DEFAULT '' COMMENT '签名,接口请求头会根据这个值增加token',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `enterprise_id` (`subscription_type`,`enterprise_id`,`callback_url`) USING BTREE)
) ENGINE=InnoDB AUTO_INCREMENT=1039 DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC
该表使用了utf8字符集,一个字符占用三个字节。联合索引“enterprise_id”包含了“callback_url”字段,如果执行DDL操作将“callback_url”修改为varchar(1024),会超出联合索引最大长度限制,所以报错。
解决方案
MySQL机制约束,建议修改索引或字段长度。
delete大表数据后,再查询同一张表时出现慢SQL
场景描述
一次性删除多条宽列数据(每条记录数据长度在1GB左右),再次对同一张表进行增删改查时均执行缓慢,20分钟左右后恢复正常。
场景案例
- 假定max_allowed_packet参数大小为1073741824。
- 创建表。
CREATE TABLE IF NOT EXISTS zstest1
(
id int PRIMARY KEY not null,
c_longtext LONGTEXT
);
- 向表中插入数据。
insert into zstest1 values(1, repeat('a', 1073741800));
insert into zstest1 values(2, repeat('a', 1073741800));
insert into zstest1 values(3, repeat('a', 1073741800));
insert into zstest1 values(4, repeat('a', 1073741800));
insert into zstest1 values(5, repeat('a', 1073741800));
insert into zstest1 values(6, repeat('a', 1073741800));
insert into zstest1 values(7, repeat('a', 1073741800));
insert into zstest1 values(8, repeat('a', 1073741800));
insert into zstest1 values(9, repeat('a', 1073741800));
insert into zstest1 values(10, repeat('a', 1073741800));
- 删除数据。
delete from zstest1;
- 执行查询语句。
select id from zstest1; //执行缓慢
原因分析
执行完delete操作后,后台purge线程会去清理标记为delete mark的记录。由于当前删除的数据量较大,purge遍历释放page的过程中会去获取page所在索引根节点的SX锁,导致select语句无法获取到根节点page的rw-lock,一直在等待。
解决方案
- 该场景为正常现象,等待purge操作完成后即可恢复正常。
- 扩大实例规格,提高purge效率。
- 调整优化业务,避免突然删除大量数据。如果需要删除表中所有数据,建议使用 truncate table 。
更新emoji表情数据报错Error 1366
场景描述
业务插入或更新带有emoji表情的数据时,报错Error 1366。
java.sql.SQLException: Incorrect string value: '\xF0\x9F\x90\xB0\xE5\xA4...' for column 'username' at row 1 ;
uncategorized SQLException for SQL []; SQL state [HY000]; error code [1366];
Incorrect string value: '\xF0\x9F\x90\xB0\xE5\xA4...' for column 'username' at row 1;
原因分析
原因是字符集配置有误:
- emoji表情为特殊字符,需要4字节字符集存储。
- 该问题场景下,数据库字符集为utf-8,它最多支持3个字节;utf8mb4才是支持4个字节的字符集;
解决方案
- 将存储emoji表情的字段的字符集修改为utf8mb4。
如果涉及的表和字段比较多,建议把对应表、数据库的编码也设置为utf8mb4。参考命令:
ALTER DATABASE database_name CHARACTER SET= utf8mb4 COLLATE= utf8mb4_unicode_ci;
ALTER TABLE table_name CONVERTTOCHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
ALTER TABLE table_name MODIFY 字段名 VARCHAR(128) CHARSET utf8mb4 COLLATE utf8mb4_unicode_ci;
- 若对应字段的字符集已经是utf8mb4,则为客户端或MySQL服务端字符集转换问题,将客户端和MySQL服务端的字符集都设置为utf8mb4。
存储过程和相关表字符集不一致导致执行缓慢
场景描述
TaurusDB存储过程执行很慢,处理少量数据耗时1min以上,而单独执行存储过程中的SQL语句却很快。
原因分析
存储过程和相关表、库的字符集不一致,导致查询结果存在大量字符转换,从而执行缓慢。
排查过程:
使用如下命令查看存储过程和相关表的定义,观察存储过程和表的字符集是否一致。
SHOW CREATE PROCEDURE xxx;
SHOW CREATE TABLE xxx
示例:
mysql> SHOW CREATE PROCEDURE testProc \G
*************************** 1. row ***************************
Procedure: showstuscore
sql_mode: STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
Create Procedure: xxx
character_set_client: utf8mb4
collation_connection: utf8mb4_general_ci
Database Collation: utf8_general_ci
1 row in set (0.01 sec)
可以看出,上述存储过程collation为utf8mb4_general_ci,而所在库collation默认为utf8_general_ci,collation值不一致,容易导致性能问题。
解决方案
将存储过程和相关表、库的字符集改成一致后,执行缓慢问题解决。
报错ERROR [1412]的解决方法
场景描述
连接TaurusDB执行SQL时,出现如下报错:
ERROR[1412]:Table definition has changed, please retry transaction``
原因分析
启动一致性快照事务后,其他会话(session)执行DDL语句导致。问题复现步骤:
- 会话1启动一致性快照事务。


- 会话2执行DDL操作,修改表结构。

- 会话1执行普通的查询语句。


也可以通过Binlog或者审计日志,分析业务侧是否有同一个表DDL和一致性快照事务一起执行的情况。
解决方案
若经排查,是由上述原因引起的报错,需要业务侧避免同一个表的DDL语句和一致性快照事务同时执行。
存在外键的表无法删除
场景描述
删除MySQL表时,如果表中有外键(foreign key),会出现如下报错,且和用户权限无关:
ERROR 1451 (23000): Cannot delete or update parent row: a foreign key constraint fails …………
原因分析
这个表和其他表有外键关系,在MySQL中,设置了外键关联,会造成无法更新或删除数据,避免破坏外键的约束。
可以通过设置变量FOREIGN_KEY_CHECKS值为off,来关闭上述机制,详见官方文档。
解决方案
通过设置变量FOREIGN_KEY_CHECKS值为off,来关闭上述机制:
set session foreign_key_checks=off;
drop table table_name;
GROUP_CONCAT结果不符合预期
场景描述
SQL语句中使用GROUP_CONCAT()函数时,出现结果不符合预期的情况。
原因分析
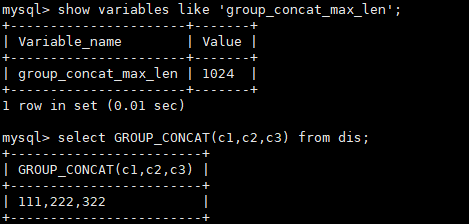
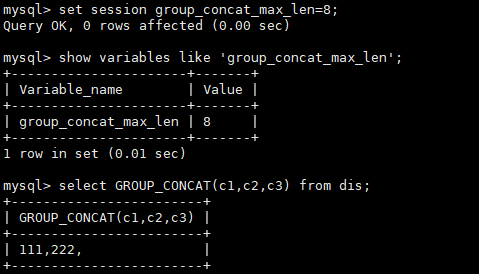
GROUP_CONCAT()函数返回一个字符串结果,该结果由分组中的值连接组合而成。需要注意的是:这个函数的结果长度是有限制的,由group_concat_max_len参数决定。
示例:


解决方案
调整group_concat_max_len参数值,适配GROUP_CONCAT()函数的结果长度。
创建二级索引报错Too many keys specified
场景描述
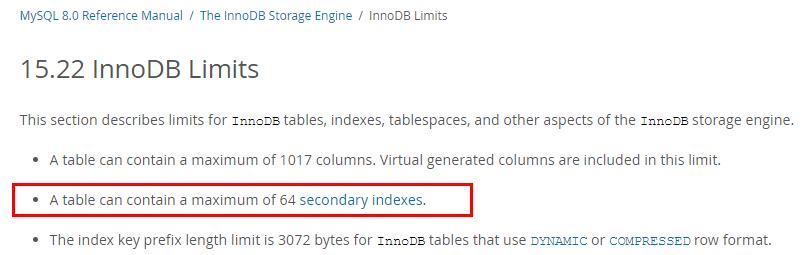
创建二级索引失败,报错:Too many keys specified; max 64 keys allowed.
故障分析
MySQL对InnoDB每张表的二级索引的数量上限有限制,限制上限为64个,超过限制会报错“Too many keys specified; max 64 keys allowed”。详见官方文档。
解决方案
MySQL机制导致,建议优化业务,避免单表创建过多索引。
说明InnoDB表的其他限制:
1. 一个表最多可以包含1017列(包含虚拟生成列)。
2. InnoDB对于使用DYNAMIC或COMPRESSED行格式的表,索引键前缀长度限制为3072字节。
3. 多列索引最多允许16列,超过限制会报错。
distinct与group by优化
场景描述
使用distinct或group by的语句执行比较慢。
原因分析
大部分情况下,distinct是可以转化成等价的group by语句。在MySQL中,distinct关键字的主要作用就是去重过滤。
distinct进行去重的原理是先进行分组操作,然后从每组数据中取一条返回给客户端,分组时有两种场景:
- distinct的字段全部包含于同一索引:该场景下MySQL直接使用索引对数据进行分组,然后从每组数据中取一条数据返回。
- distinct字段未全部包含于索引:该场景下索引不能满足去重分组需要,会用到临时表(首先将满足条件的数据写入临时表中,然后在临时表中对数据进行分组,返回合适的数据)。因为使用临时表会带来额外的开销,所以一般情况下性能会较差。
综上,在使用distinct或group by的时候,尽量在合理的情况下设置可以包含所有依赖字段的索引,优化示例:
- 没有合适索引,导致需要用到临时表。

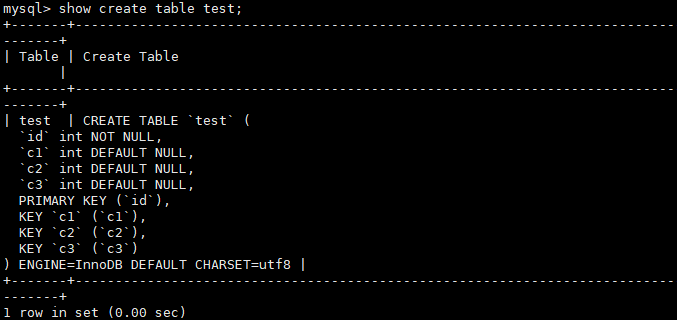

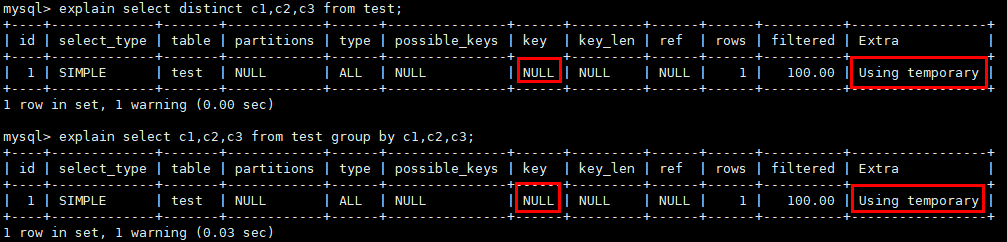
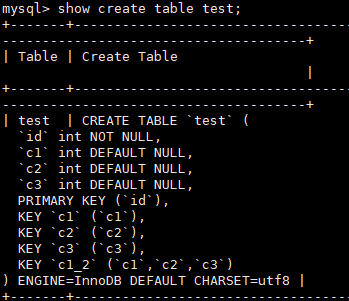
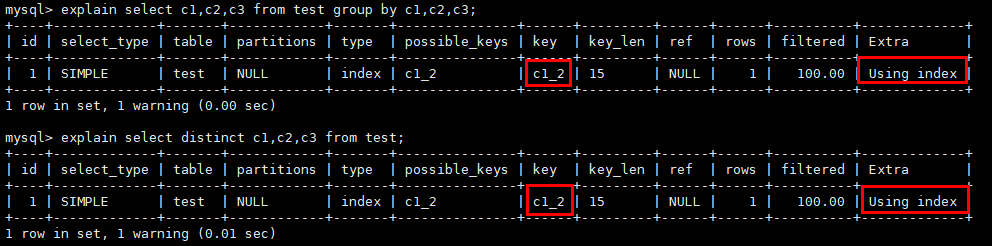
- 有合适的索引,不会使用临时表,直接走索引。




解决方案
在使用distinct或group by的时候,尽量在合理的情况下,创建可以包含所有依赖字段的索引。
为什么有时候用浮点数做等值比较查不到数据
原因分析
浮点数的等值比较问题是一种常见的浮点数问题。因为在计算机中,浮点数存储的是近似值而不是精确值,所以等值比较、数学运算等场景很容易出现预期外的情况。
MySQL中涉及浮点数的类型有float和double。如下示例中遇到的问题:

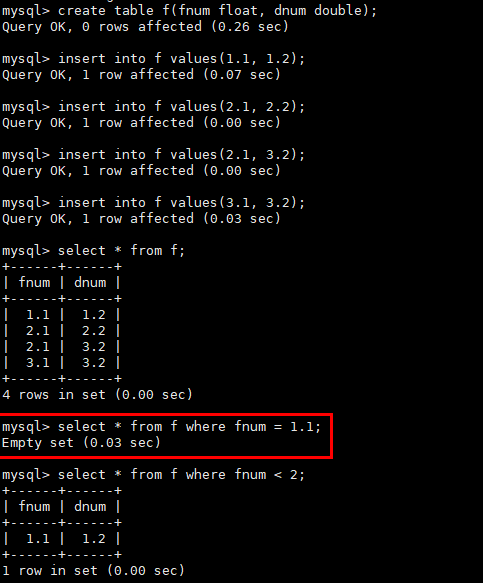
解决方案
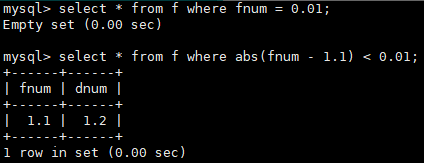
- 使用精度的方法处理,使用字段与数值的差值的绝对值小于可接受的精度的方法。示例:

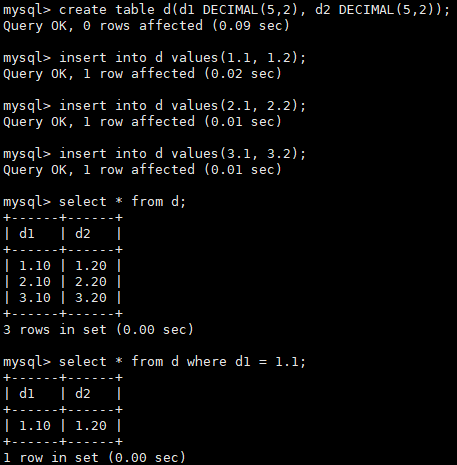
- 使用定点数类型(DECIMAL)取代浮点数类型,示例:

表空间膨胀问题
场景描述
在使用TaurusDB过程中,经常遇到表空间膨胀问题,例如:表中只有11774行数据,表空间却占用49.9GB,将该表导出到本地只有800M。
原因分析
场景1:DRS全量迁移阶段并行迁移导致
原因:DRS在全量迁移阶段,为了保证迁移性能和传输的稳定性,采用了行级并行的迁移方式。当源端数据紧凑情况下,通过DRS迁移到云上TaurusDB后,可能会出现数据膨胀现象,使得磁盘空间使用远大于源端。
场景2:大量删除操作后在表空间留下碎片所致
原因:当删除数据时,mysql并不会回收被删除数据占据的存储空间,而只做标记删除,尝试供后续复用,等新的数据来填补相应空间,如果短时间内没有数据来填补这些空间,就造成了表空间膨胀,形成大量碎片;
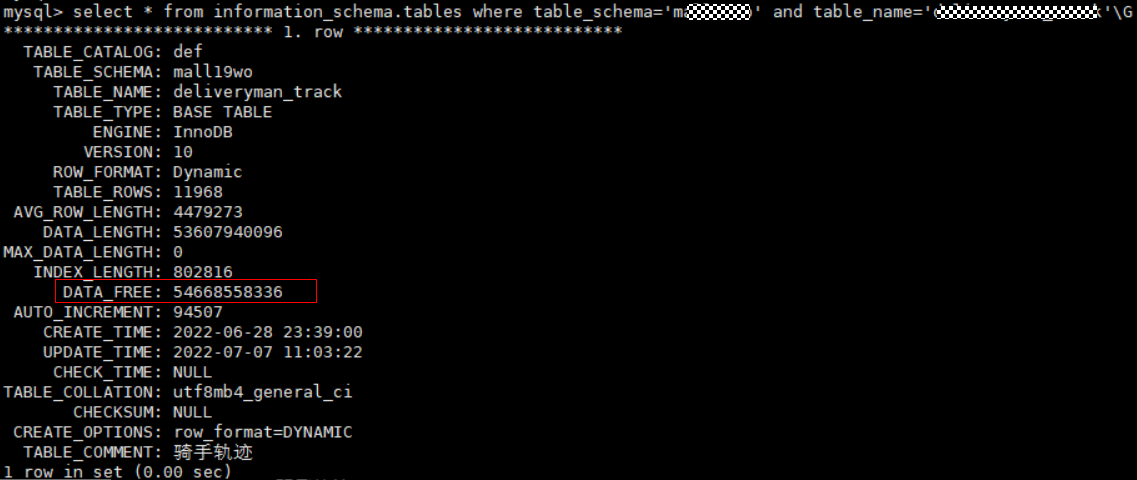
可以通过如下SQL语句,查询某个表详细信息,DATA_FREE字段表示表空间碎片大小:
select * from information_schema.tables where table_schema='db_name' and table_name = 'table_name'\G

解决方案
针对表空间膨胀的问题,可以进行表空间优化整理,从而缩小空间,执行如下SQL命令:
optimize table table_name;
说明optimize table命令会有短暂锁表操作,所以进行表空间优化时,建议避开业务高峰期,避免影响正常业务的进行。
MySQL创建用户提示服务器错误(ERROR 1396)
场景描述
用户帐号在控制台界面上消失,创建不了同名帐号,但使用帐号名和旧密码还能连接。
创建用户失败的报错信息:
ERROR 1396 (HY000): Operation CREATE USER failed for xxx。
问题分析
- 查询确认后,发现消失的账号在mysql.user表中已经被删除,故控制台不再显示;
- 使用帐号名和旧密码还能连接登录,说明使用的是delete from mysql.user方式删除用户。使用这种方式删除用户,需要执行flush privileges后,才会清理内存中相关数据,该用户才彻底不能登录。
- 使用delete from mysql.user方式删除用户,无法重新创建相应账户(报错ERROR 1396),原因是内存中相关数据仍然存在。

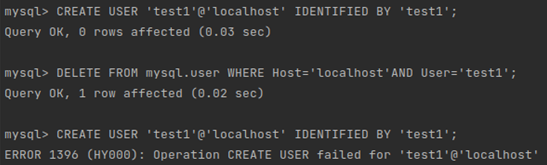
正确删除用户的方式为drop user语句,注意以下几点:
- drop user语句可用于删除一个或多个用户,并撤销其权限。
- 使用drop user语句必须拥有MySQL数据库的DELETE权限或全局CREATE USER权限。
- 在drop user语句的使用中,若没有明确地给出帐户的主机名,则该主机名默认为“%”。
故障场景恢复示例:
创建用户后用delete删除用户,再创建同名用户时报错ERROR 1396。通过执行flush privileges后,可正常创建同名用户。

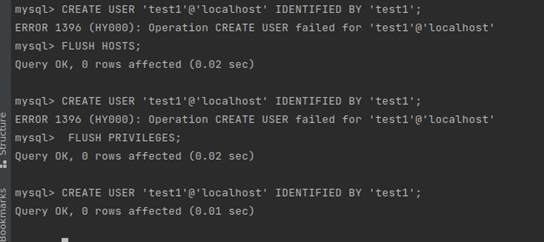
解决方案
- 方式一(推荐):在业务低峰期,使用管理员帐户执行drop user user_name删除用户,再重新创建该用户,修复该问题。
- 方式二:在业务低峰期,使用管理员帐户执行flush privileges后,再重新创建该用户,修复该问题。建议开启数据库全量sql洞察功能,便于分析是哪个客户端删除了用户。
执行alter table xxx discard/import tablespace报错
场景描述
在TaurusDB中执行alter table xxx discard/import tablespace会报错:ERROR 3658 (HY000): Feature IMPORT/DISCARD TABLESPACE is unsupported ().
原因分析
alter table xxx discard/import tablespace是社区MySQL一种基于本地.ibd的表空间文件物理的做数据表内容替换(多用于数据迁移、备份恢复等)的方法。
TaurusDB是存储计算分离架构,实际数据存储于共享存储上,本地没有.ibd文件,所以不支持相应的物理操作。
解决方案
使用其他如导入导出、DRS同步、备份恢复等方式做数据表内容的替换。
数据库报错Native error 1461的解决方案
场景描述
MySQL用户通常在并发读写、大批量插入sql语句或数据迁移等场景出现如下报错信息:
mysql_stmt_prepare failed! error(1461)Can't create more than max_prepared_stmt_count statements (current value: 16382)
故障分析
“max_prepared_stmt_count”的取值范围为0~1048576,默认为“16382”,该参数限制了同一时间在mysqld上所有session中prepared语句的上限,用户业务超过了该参数当前值的范围。
解决方案
请您调大“max_prepared_stmt_count”参数的取值,建议调整为“65535”。
创建表失败报错Row size too large的解决方案
场景描述
MySQL用户创建表失败,出现如下报错信息:
Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs
故障分析
“varchar” 的字段总和超过了65535,导致创建表失败。
解决方案
- 缩减长度,如下所示。
CREATE TABLE t1 (a VARCHAR(10000),b VARCHAR(10000),c VARCHAR(10000),d VARCHAR(10000),e VARCHAR(10000),f VARCHAR(10000) ) ENGINE=MyISAM CHARACTER SET latin1;
- 请参考官方文档修改一个字段为TEXT类型。

