冷热数据问题导致SQL执行速度慢
场景描述
从自建MySQL或友商MySQL迁移到云上TaurusDB实例,发现同一条SQL语句执行性能远差于原数据库。
原因分析
同一条SQL语句在数据库中执行第一次和第二次可能会性能差异巨大,这是由数据库的buffer_pool机制决定的:
- 第一次执行时,数据在磁盘上,称之为冷数据,读取需要一定的耗时。
- 读取完,数据会被存放于内存的buffer_pool中,称为热数据,读取迅速;对于热数据的访问速度极大的超过冷数据,所以当数据是热数据时,SQL语句的执行速度会远快于冷数据。
该场景中,源端数据库中常用的数据一般是热数据,所以访问时速度极快。当数据迁移到云上TaurusDB时,第一次执行同样的SQL语句,很可能是冷数据,就会访问较慢,但再次访问速度就会得到提升。
解决方案
该场景是正常现象,在同一个数据库中,我们经常会遇到第一次执行一条语句时很慢,但再次执行就很快,也是因为受到了buffer_pool的冷热数据原理的影响。
复杂查询造成磁盘满
场景描述
主机或只读节点偶尔出现磁盘占用高或磁盘占用满,其他只读节点磁盘空间占用正常。
原因分析
MySQL内部在执行复杂SQL时,会借助临时表进行分组(group by)、排序(order by)、去重(distinct)、Union等操作,当内存空间不够时,便会使用磁盘空间。
排查思路:
- 因为其他只读节点磁盘占用空间正常,且是偶尔出现,说明该实例磁盘占用高,与承载的业务相关。
- 获取该实例的慢日志,分析磁盘占用高期间,是否有对应的慢SQL。
- 如果有慢SQL,执行 **explain ** [慢SQL语句] ,分析相应慢SQL语句。
- 观察explain语句输出的extra列,是否有using temporary、using filesort,如果有,说明该语句用到了临时表或临时文件,数据量大的情况下,会导致磁盘占用高。
解决方案
- 复杂查询语句导致磁盘打满,建议客户从业务侧优化响应查询语句,常见优化措施:
- 加上合适的索引。
- 在where条件中过滤更多的数据。
- 重写SQL,优化执行计划。
- 如果不得不使用临时表,那么一定要减少并发度。
- 临时规避措施:考虑业务侧优化复杂查询语句需要一定时间,可以通过临时扩容磁盘空间规避。
业务死锁导致响应变慢
场景描述
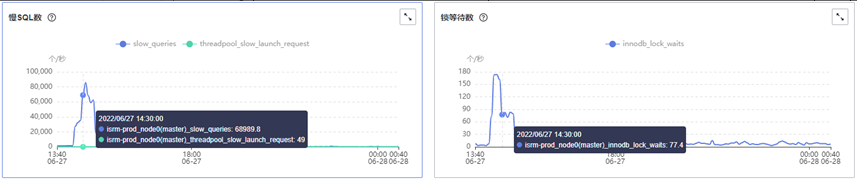
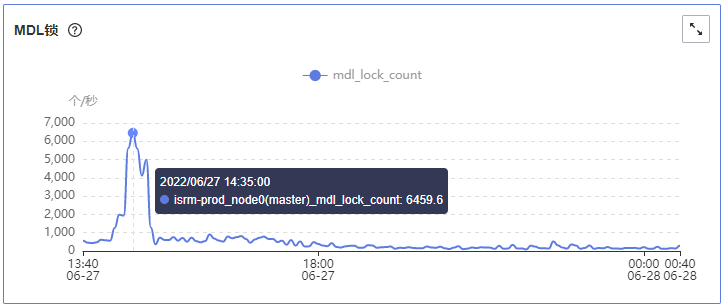
14点~15点之间数据库出现大量行锁冲突,内核中大量update/insert会话在等待行锁释放,导致CPU使用率达到70%左右,数据库操作变慢。
查看CES指标行锁等待个数、MDL锁数量,下图仅供参考:

发生死锁的表:
********* 1. row *********
Table: table_test Create Table: CREATE TABLE table_test(
...
CONSTRAINT act_fk_exe_parent FOREIGN KEY (parent_id_) REFERENCES act_ru_execution (id_) ON DELETE CASCADE,
CONSTRAINT act_fk_exe_procdef FOREIGN KEY (proc_def_id_) REFERENCES act_re_procdef (id_),
CONSTRAINT act_fk_exe_procinst FOREIGN KEY (proc_inst_id_) REFERENCES act_ru_execution (id_) ON DELETE CASCADE ON UPDATE CASCADE, CONSTRAINT act_fk_exe_super FOREIGN KEY (super_exec_) REFERENCES act_ru_execution (id_) ON DELETE CASCADE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
原因分析
- 部分表发生死锁,导致CPU一定幅度抬升。
- 死锁的表中有大量的外键,这些表的记录在更新时,不仅需要获取本表的行锁,还需要检查外键关联表的记录,获取相应锁。高并发情况下,比普通表更容易锁冲突或死锁,详解官方文档。
- 当MySQL检查到死锁的表时,会进行事务的回滚。其影响范围不仅是某个表,还会影响外键所在的表,最终导致数据库相关操作变慢。
解决方案
建议排查并优化死锁表相关的业务,业务上合理使用外键,避免更新冲突,避免产生死锁。
TaurusDB实例CPU升高定位思路
TaurusDB实例CPU升高或100%,引起业务响应慢,新建连接超时等。
场景1 慢查询导致CPU升高
问题原因:大量慢SQL导致实例CPU升高,需要优化相应的慢SQL。
排查思路:
查看CPU使用率和慢日志个数统计监控指标。

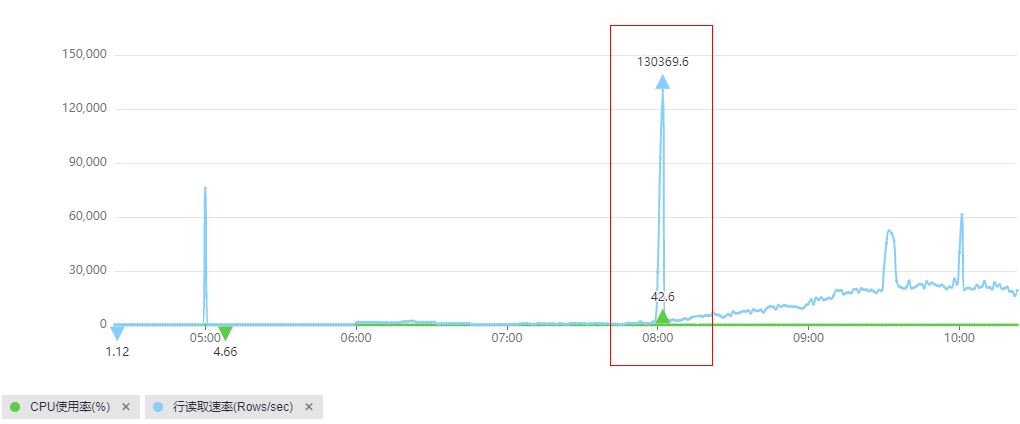
- 如果慢日志个数很多,且与CPU曲线吻合,可以确定是慢SQL导致CPU升高。
- 如果慢日志个数不多,但与CPU使用率基本一致,进一步查看行读取速率指标是否与CPU曲线吻合。

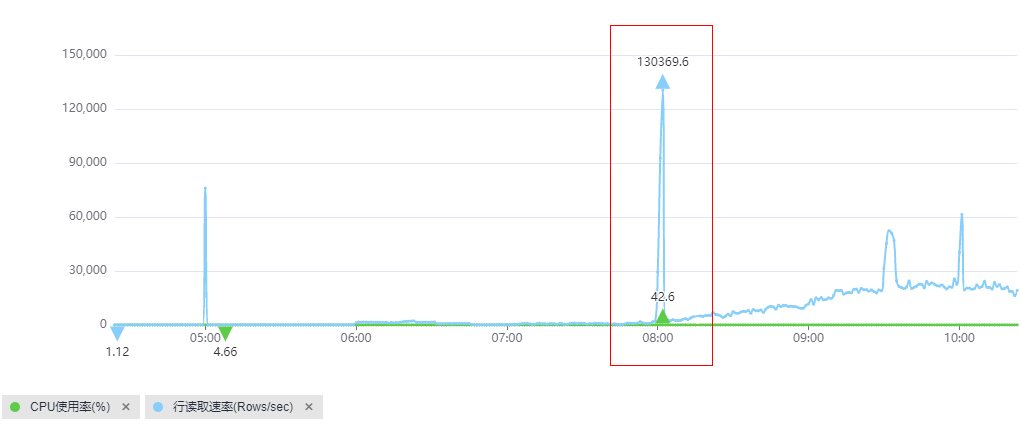
如果吻合,说明是少量慢SQL访问大量行数据导致CPU升高:由于这些慢SQL查询执行效率低,为获得预期的结果需要访问大量的数据导致平均IO高,因此在QPS并不高的情况下(例如网站访问量不大),也会导致实例的CPU使用率偏高。
解决方案:
- 根据CPU使用率过高的时间点,查看对应时间段的慢日志信息。
- 重点关注扫描行数、返回结果行数超过百万级别的慢查询,以及锁等待时间长的慢查询。
- 慢查询用户可自行分析,或使用数据管理服务(DAS)对慢查询语句进行诊断。
- 通过分析数据库执行中的会话来定位执行效率低的SQL。
- 连接数据库。
- 执行 show full processlist; 。
- 分析执行时间长、运行状态为Sending data、Copying to tmp table、Copying to tmp table on disk、Sorting result、Using filesort的会话,均可能存在性能问题,通过会话来分析其正在执行的SQL。
场景2 连接和QPS升高导致CPU上升
问题原因:业务请求增高导致实例CPU升高,需要从业务侧分析请求变化的原因。
排查思路:
查看QPS、当前活跃连接数、数据库总连接数、CPU使用率监控指标是否吻合。
QPS的含义是每秒查询数,QPS和当前活跃连接数同时上升,且QPS和CPU使用率曲线变化吻合,可以确定是业务请求增高导致CPU上升,如下图:

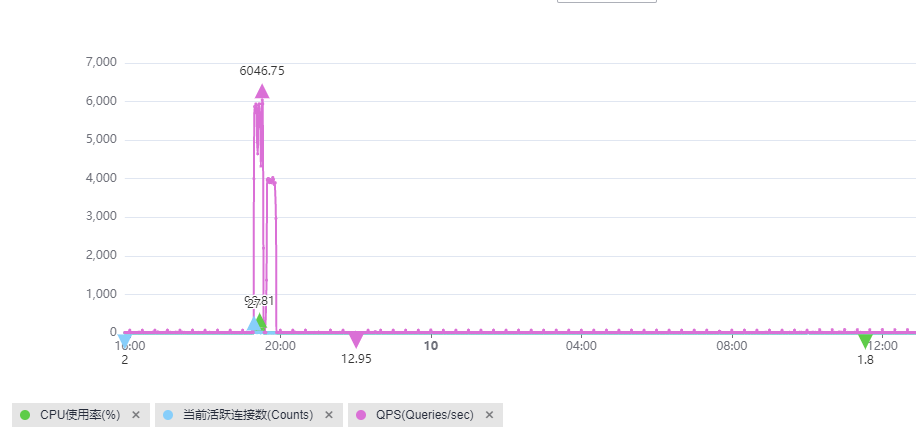
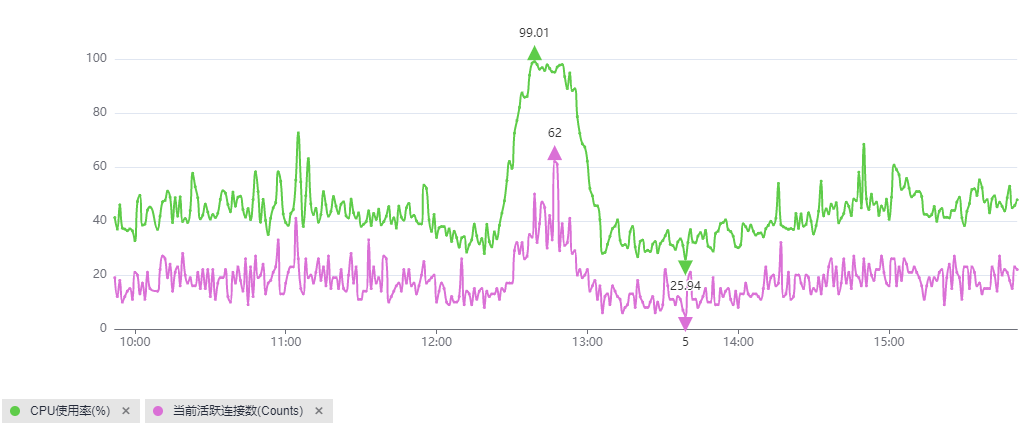

该场景下,SQL语句一般比较简单,执行效率也高,数据库侧优化余地小,需要从业务源头优化。
解决方案:
- 单纯的QPS高导致CPU使用率过高,往往出现在实例规格较小的情况下,建议升级实例CPU规格。
- 优化慢查询,优化方法参照场景1 慢查询导致CPU升高的解决方案。若优化慢查询后效果不明显,建议升级实例CPU规格。
- 对于数据量大的表,建议通过分库分表减小单次查询访问的数据量。
大并发慢查询导致CPU资源耗尽问题
场景描述
数据库实例上存在大量并发的select count(0)慢操作,系统CPU耗尽,随时有宕机的风险。
Show processlist信息:

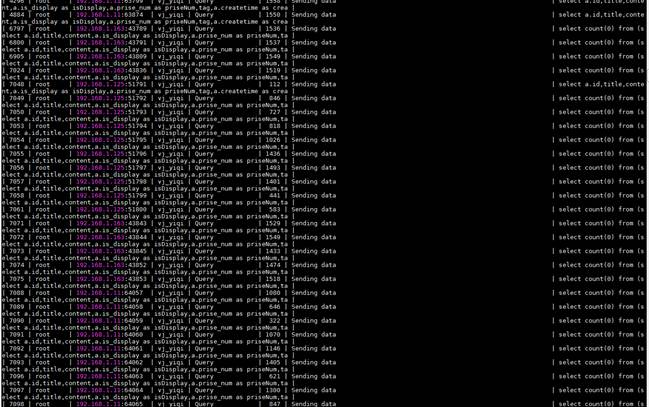
该sql慢日志查询信息:

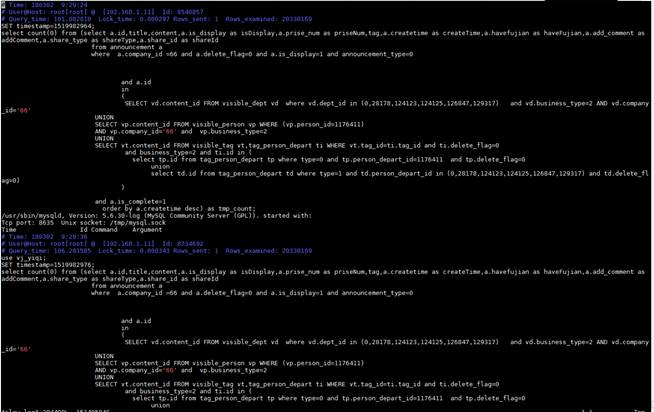
原因分析
应用端大并发触发select count(0)慢操作,导致系统CPU资源耗尽。
解决方案
步骤 1 申请kill权限,间歇性批量执行kill select count(0)慢操作,定位select count(0)触发来源,停止来源,并拆分优化sql。
批量kill动作:

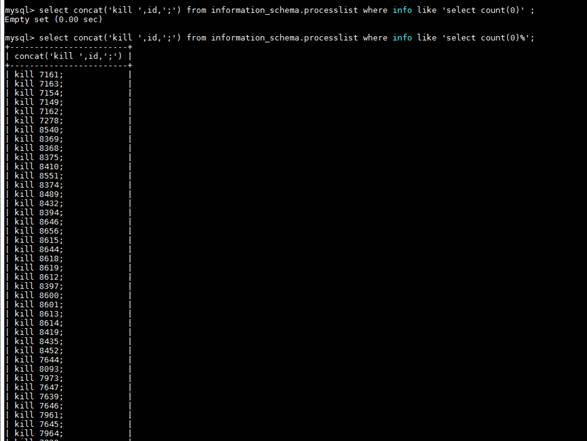
步骤 2 CPU idle恢复: