应用场景
使用MirrorMaker进行跨集群数据同步是Kafka中常见的场景之一。MirrorMaker是Kafka提供的一个工具,用于将一个Kafka集群中的消息复制到另一个Kafka集群,实现跨数据中心、跨地域或跨集群的数据同步。
以下是一些常见的使用MirrorMaker进行跨集群数据同步的场景:
-
备份和灾备:
MirrorMaker可用于将生产环境中的消息复制到备份集群,以实现数据的备份和灾备。当主集群发生故障或不可用时,可以切换到备份集群,确保数据的可用性和连续性。
-
数据复制和分发:
如果有多个数据中心或地理位置,可以使用MirrorMaker将消息从一个集群复制到另一个集群,实现数据的复制和分发。这样可以将数据从一个地区或数据中心传输到另一个地区或数据中心,以满足不同地区或数据中心的业务需求。
-
跨云厂商数据同步:
当使用多个云厂商的Kafka服务时,MirrorMaker可以用于将消息从一个云厂商的Kafka集群复制到另一个云厂商的Kafka集群,实现跨云厂商的数据同步和迁移。
-
数据聚合和分析:
当需要将多个Kafka集群中的消息聚合到一个集群中进行分析时,可以使用MirrorMaker将消息从多个集群复制到目标集群,以实现数据的聚合和分析。
需要注意的是,MirrorMaker在进行数据同步时,会引入一定的延迟,并且在网络传输和资源消耗方面会有一定的开销。因此,在使用MirrorMaker进行跨集群数据同步时,需要根据实际情况进行配置和调优,以满足业务需求和性能要求。
方案架构
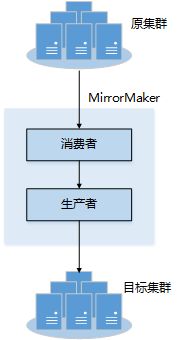
使用MirrorMaker可以实现将源集群中的数据镜像复制到目标集群中。其原理如图1所示,MirrorMaker本质上也是生产消费消息,首先从源集群中消费数据,然后将消费的数据生产到目标集群。
图1 MirrorMaker原理图
约束与限制
使用MirrorMaker进行跨集群数据同步时,有一些约束和限制需要注意:
-
版本兼容性:
MirrorMaker的源集群和目标集群的Kafka版本需要兼容。确保源集群和目标集群的Kafka版本一致或兼容,以避免潜在的兼容性问题。
-
主题和分区配置:
MirrorMaker默认会复制源集群中的所有主题和分区,但可以通过配置文件或命令行参数来选择特定的主题和分区进行复制。需要确保源集群和目标集群的主题和分区配置保持一致。
-
消费者组和偏移量:
MirrorMaker会在目标集群中创建一个消费者组,用于消费源集群中的消息。需要注意,MirrorMaker不会复制消费者组的偏移量,因此,在切换到目标集群后,消费者组的偏移量会从新的消费者组开始。
-
延迟和吞吐量:
在进行数据同步时,MirrorMaker会引入一定的延迟,并且在网络传输和资源消耗方面会有一定的开销。需要根据实际情况进行配置和调优,以平衡延迟和吞吐量的需求。
-
一致性保证:
MirrorMaker使用异步复制的方式进行数据同步,因此无法提供严格的一致性保证。在进行数据同步时,存在一定的消息丢失或消息重复的风险。需要根据业务需求和数据重要性来评估和处理这些风险。
-
高可用性和故障恢复:
MirrorMaker本身不提供高可用性和故障恢复机制。如果MirrorMaker节点发生故障或不可用,需要手动进行故障恢复和替换。可以通过配置多个MirrorMaker节点来提高可用性,以确保数据同步的连续性和可靠性。
需要根据具体的使用场景和需求,合理评估和处理这些约束和限制,以确保数据同步的效果和可靠性。
实施步骤
(1)购买一台弹性云主机,确保弹性云主机与源集群、目标集群网络互通。
(2)登录弹性云主机,安装Java JDK,并配置JAVA_HOME与PATH环境变量。其中“/usr/local/java/jdk1.8.0_161”为JDK的安装路径,请根据实际情况修改。
exportJAVA_HOME=/usr/local/java/jdk1.8.0_161
exportPATH=$JAVA_HOME/bin:$PATH
(3)下载安装kafka
下载页面:https://kafka.apache.org/downloads.html
(4)进入kafka安装目录,修改“config/connect-mirror-maker.properties”配置文件,在配置文件中指定源集群和目标集群的IP地址和端口以及其他配置。
(5)在kafka安装目录下,启动MirrorMaker,进行数据同步。
./bin/connect-mirror-maker.sh config/connect-mirror-maker.properties
验证数据是否同步
要验证MirrorMaker是否成功同步数据,可以采取以下几种方法:
-
检查目标集群的主题和分区:
在目标集群上使用Kafka命令行工具或管理工具,查看MirrorMaker复制的主题和分区是否存在。确保目标集群上有与源集群相同的主题和分区。
-
检查消息偏移量:
使用Kafka消费者API或命令行工具,从目标集群中消费复制的消息。验证消息的偏移量是否与源集群中的消息偏移量一致。如果偏移量相同,表示数据同步成功。
-
检查消息内容:
从目标集群中消费复制的消息,并与源集群中的消息进行比较。验证消息内容是否一致。可以使用Kafka消费者API或命令行工具来消费消息,并进行比较。
-
监控MirrorMaker的指标:
在MirrorMaker节点上启用监控,收集关于复制进度、延迟和吞吐量等指标的数据。通过监控指标,可以了解MirrorMaker的工作状态和性能表现,进一步验证数据同步的情况。
-
进行端到端测试:
在源集群中发送一些测试消息,并在目标集群中验证这些消息是否被成功复制。可以使用Kafka生产者API或命令行工具发送测试消息,并使用Kafka消费者API或命令行工具从目标集群中消费并验证消息。
通过以上方法,可以验证MirrorMaker是否成功同步数据,并确保数据在源集群和目标集群之间的一致性。根据实际需求,可以选择适合的验证方法或组合多种方法来进行验证。

