分布式消息服务Kafka 是一个分布式、高吞吐量、高可用的消息队列服务,针对开源的 Kafka 提供全托管服务,解决开源产品长期以来的痛点,用户只需专注于业务开发,无需部署运维,低成本、更弹性、更可靠,广泛用于日志收集、监控数据聚合、流式数据处理、在线和离线分析等大数据领域,是大数据生态中不可或缺的产品之一。
关于Kafka的帮助手册阅读指引
考虑到篇幅的限制,我们提供的Kafka用户手册主要描述了产品相关的信息,以及与开源社区版Kafka的差异,如天翼云Kafka的产品规格、控制台操作、API接口调用,以及客户端对接等方面。
如果您需要了解Kafka的基础入门知识或者消息的生产和消费等技术细节,请查阅Kafka官网资料。
产品架构
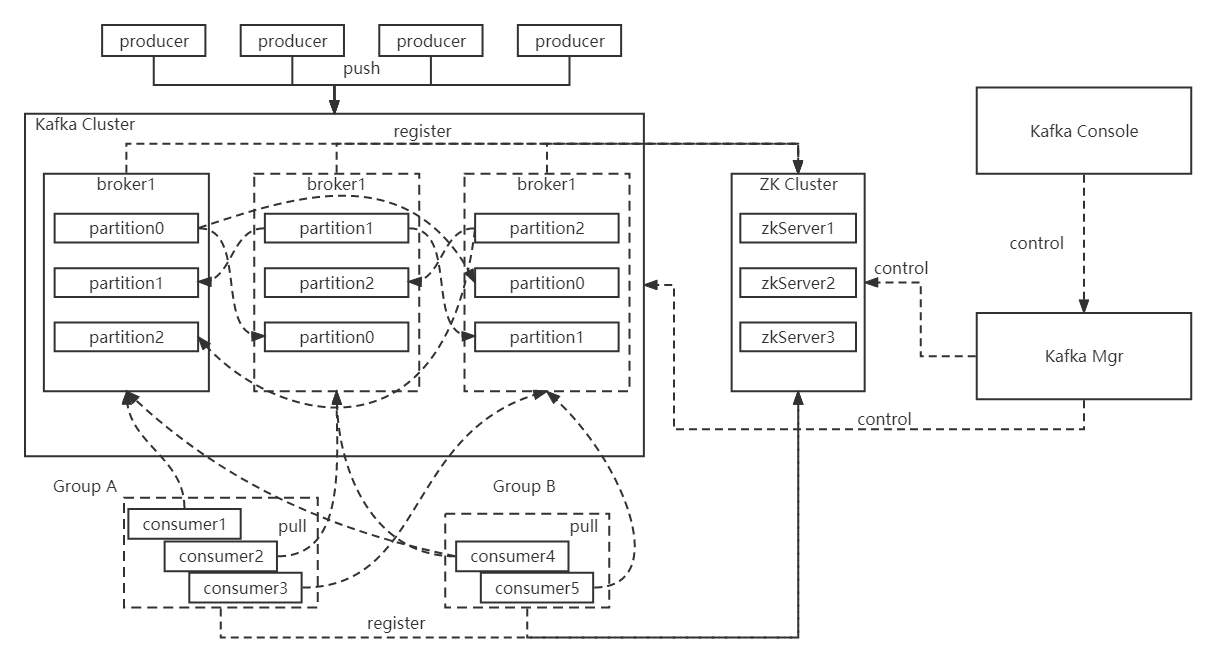
- Broker:消息中间件处理结点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
- Topic:主题 一类消息的集合。
- Partition:分区,topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。
- Segment:partition物理上由多个segment组成。
- offset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息。
- Producer:消息和数据生成者,一般为应用调用API进行消息生产,并向Kafka的Topic发布消息。
- Consumer:消息订阅者,也成为消息消费者,负责向 Kafka Broker 读取消息并进行消费。
- Consumer Group:一类Consumer的集合名称,这类Consumer通常消费一类消息,且消费逻辑一致,Consumer Group 和 Topic 的关系是 N:N,同一个 Consumer Group 可以订阅多个 Topic,同一个 Topic 也可以被多个 Consumer Group 订阅。
更多信息请参见名词解释。
开源对比
相较于开源自建Kafka,分布式消息服务Kafka在低成本运维、分区规模、消息查询、ACL访问控制、可视化配置、运维监控、集群巡检、稳定可靠、安全保证、简单易用等方面更具优势。更多信息请参见开源对比。
产品优势
分布式消息服务Kafka具备高可用性、高安全性、可靠性、全托管等优势,使其成为大规模数据处理和实时流处理的理想选择。更多信息请参见产品优势。
功能特性
分布式消息服务Kafka的功能特性主要体现在以下几个方面:
消息能力
- 广播消息:在同一个消费组内对所有消费者投递相同消息。
- 消息回溯:支持根据时间重置消费进度。
- 消息数据自动删除功能:在磁盘满后,在保护期外的数据,能自动删除,保证服务可用性。
- 自动故障切换功能:生产消费自动负载均衡,消息节点故障时自动主备切换,保证服务的连续性。
队列能力
- 高吞吐,消息多副本异步复制。
- 高可靠,消息多副本同步复制。
可视化管理
- 应用用户管理:多个应用可调用同一个消息服务,通过应用用户,对消息服务下的应用接入权限进行管理。
- 主题管理:支持对实例下的主题进行管理,执行创建删除等操作。
- 消费组管理:支持对实例下的消费组进行管理。
- Broker监控:提供Broker详细信息以及多维度的监控指标查看。
- Topic监控:提供Topic详细信息以及多维度的监控指标查看。
安全防护
- 可追溯租户管理操作的记录。
- 提供用户鉴权和SASL授权访问机制,提供企业级的安全防护。
更多信息请参见功能特性。
应用场景
分布式消息服务kafka适用于物联网、电信、电子商务、金融服务等等行业,通常用于业务的流计算处理、日志聚合等场景。更多信息请参见应用场景。
使用限制
分布式消息服务kafka对实例、Topic等对象信息进行限制,使用时注意不要超过限制,以免程序出现异常。更多信息请参见使用限制。

