


近年来,互联网数据出现了爆炸式增长,单机数据库在容量和性能上往往难以满足各个互联网服务的需求。在此背景下,很多数据库通过支持横向扩展能力来满足业务需求,通过分片的方式将数据打散到多台服务器上,使得整体性能和容量得到成倍提升。
MongoDB 从最初设计上考虑到了海量数据的需求,因此原生就支持分片集群。本文将对 MongoDB 的分片原理进行分析,阐述分片架构和实现原理,并说明使用分片的注意事项。
MongoDB 分片架构
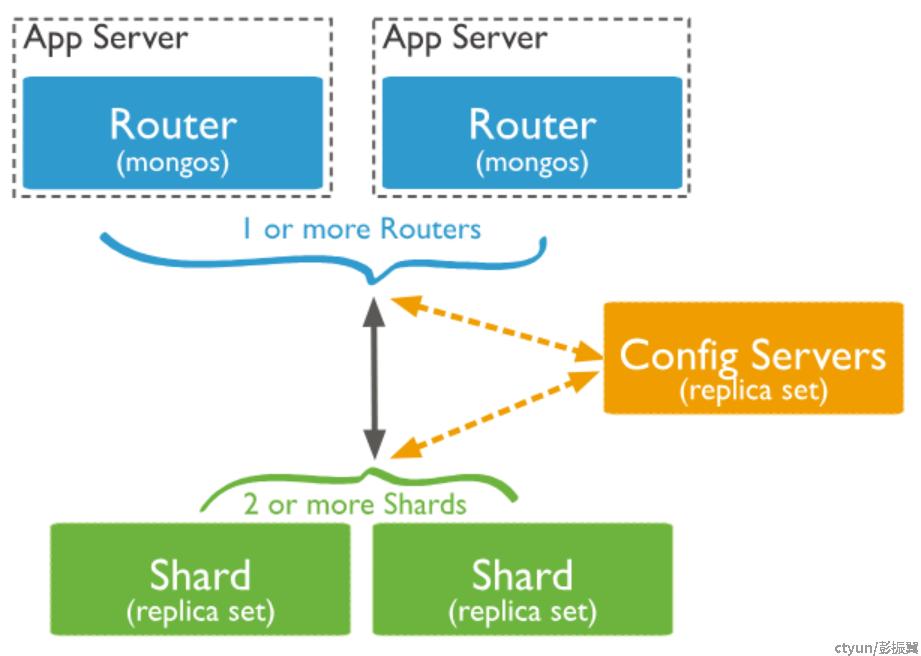
MongoDB 的分片架构如下,包含 3 种角色:
- mongos: 作为分片集群的接入层,接受用户的读写请求,并根据路由转发到底层 shard. 1 个分片集群可以有 1 个或者多个 mongos 节点。
- shard:1 个 shard 存储了一部分分片表的数据,1 个分片集群可以有 1 个或者多个 shard. 每个 shard 有多个 mongod 节点组成的副本集构成。
- config servers: 存储配置元数据以及分片表的路由等信息。 1 个分片集群有 1 个 config servers, config servers 是由多个 mongod 节点组成的副本集。
从 0 开始探究分片原理
分片无非是选好 shardKey 之后,按照某种规则将数据均匀分布到多个shard 中,保证每个 shard 的数据量和请求量基本均衡。因此,本质上来说要解决 2 个核心问题:
- 如何选择 shardKey?
- 如何选取合适的分片算法?
ShardKey 选取
分片键的选取需要保障数据分布足够离散,每个分片的存储容量均衡,并能够将数据操作均匀分发到集群中的所有分片中。
如果分片键选取不佳,可能会导致各个分片负载不均,出现 jumbo chunk 导致无法分裂等问题。而且分片键一旦确定之后,不能在运行过程中进行变更,需要按新分片键创建新表后重新导入数据(4.4及以上版本支持 shardKey 变更,但是并不建议做这种在线操作)。
一般选取分片键时,会考虑以下因素:
1. 分片键的区分度
分片键的取值基数决定了最多能包含多少个 chunk,如果取值基数太小,则会导致 chunk 数量很低,可能会有负载不均的问题。
比如按照“性别”来设置分片键就不是合理的选择,因为 “性别” 只有 “男”、“女” 2 种取值,这样最多 2 个 chunk.
2. 分片键的取值分布是否均匀
如果分片键的取值存在热点,也可能导致分片负载不均。比如以 “国家” 作为片建,会由于各个国家之间人口的差异出现负载不均,人口多的国家存储量大请求多,而人口少的国家存储量小请求少。
对于这种场景,可以考虑使用复合键来作为分片键,降低出现热点的概率。
3. 是否会按照分片键单调写入
如果业务按照分片键递增或者递减的趋势进行读写,则可能在某一时刻请求集中在某个 chunk 上,无法发挥集群多个分片的优势。
比如对于存储日志的场景,如果按照日志创建时间进行范围分片,则在某一时间内一直对同一个 chunk 进行写入。对于这种场景,可以考虑复合分片键或者哈希分片来避免这种情况。
4. 查询模型是否包含分片键
在确定分片键后,需要考虑业务的查询请求中是否包含有分片键。mongos 节点会根据查询请求中的分片键将请求转发到对应的 shard server 中。如果查询请求中不包含分片键,则 mongos 节点会将请求广播到后端的所有 shard server,进行 scatter/gather 模式的查询,此时查询性能会有所下降。
分片算法
传统的 Hash
提到将数据打散,往往第一个想到的就是 hash. 比如有 N 个 shard,可以通过 Hash(shardKey) mod N 的方式,将每条数据按照 shardKey 映射到 编号为 [0, N-1] 的 shard 中。
这种简单 hash 方式虽然将数据打散的非常均匀,但是无法处理增加和删除 shard 的问题,一旦出现 shard 变更,所有数据都要重新分布。
在实际的业务场景中,增加和删除 shard 是非常常见的操作。因此,一般很少直接使用简单 hash 的方式。
传统的一致性 Hash
一致性 hash 算法能够解决简单 hash 在 shard 数量变动时,所有数据需要重新分布的问题。
其基本思路时将hash 后的线性空间当作一个环,然后根据 shard 个数在环上分配相应的 node,每条数据根据 shardKey 计算出的 hash 值找到距离最近的弄得,而且 node 值不大于 hash 值。
如果新增或者删除 shard,会导致 node 发生变化,但是只有部分涉及到的数据需要重新分布。相比简单 hash 方式,对系统的影响相对较小。
另外,通过引入虚拟 node,可以将重新分布时的数据迁移操作分散到多个节点,并且尽量保证均匀。
不过尽管如此,在增加和删除 node 时,仍然会出现数据不均衡的情况。
MongoDB 的 Range 分片
MongoDB 引入了 chunk 的概念,作为分片、路由以及数据迁移的单元。 1 个 chunk 可以看作是分片表中 shardKey 连续排列的数据集合,是一个逻辑概念,各个 chunk 在底层存储引擎中并不是分开存储。 1 个 chunk 默认是 64MB,用户也可以根据实际需要自行调整。1个 chunk 中的数据数据总大小超过 64MB 会自动进行分裂,如果各个 shard 之间 chunk 的个数不均匀,会自动触发负载均衡操作。
以 shardKey 是 “x” 为例,其取值空间由 1 个或者多个 chunk 组成:
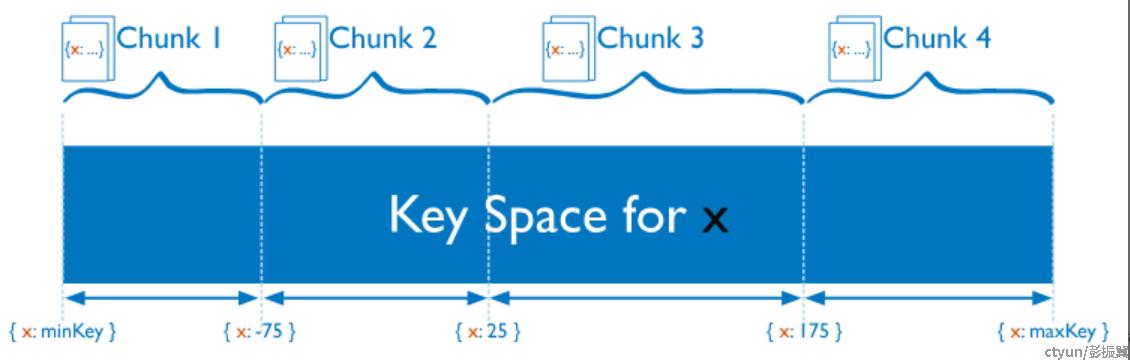
需要注意的是,1个 chunk 只能分布在某1个 shard中。如果读请求是一个小范围的查询,则 mongos 只需要将请求转发到对应的 shard 上,这样能充分利用 range 分片的优势。如果涉及多个 shard, 则 mongos 需要使用 scatter/gather 方式和多个 shard 交互。
MongoDB 的 Hash 分片
如果用户的写入操作存在按 shardKey 的单调性,比如以时间戳为 shardKey并按照时间顺序写入。此时会导致写入操作始终集中在 shardKey 最大的 chunk 上,压力始终在某一个 shard 中,而且会触发大量的分裂和迁移操作。对于 range 分片来说简直就是灾难。
MongoDB 的 hash 分片方式能够很好的解决这个问题。和 range 分片不同,shardKey 首先会经过 hash函数(md5)计算出一个整数类型的 hash 值,然后根据这个 hash 值分散到对应的 chunk 和 shard 上。如下图所示。
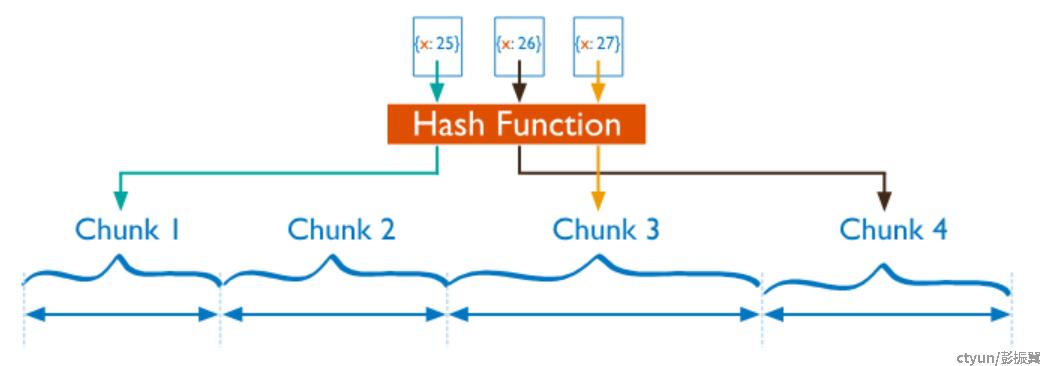
Hash 函数对用户来说是不感知的,而且代码中固定为 md5 算法。
MongoDB 的 hash 分片算法和一致性 hash 算法有点类似,但是不同之处在于 chunk 分裂机制和自动负载均衡机制使得数据分布理论上更加均匀。
MongoDB 的 Zone 分区
MongoDB 可以根据 shardKey 对 shard 设置 zone 属性,比如对于多地域部署场景,可以将华南机房的 shard 设置为 “South” zone,将华北机房的 shard 设置为 “North” zone,通过这种方式可以将对应的数据限定在特定的 shard 中存储。
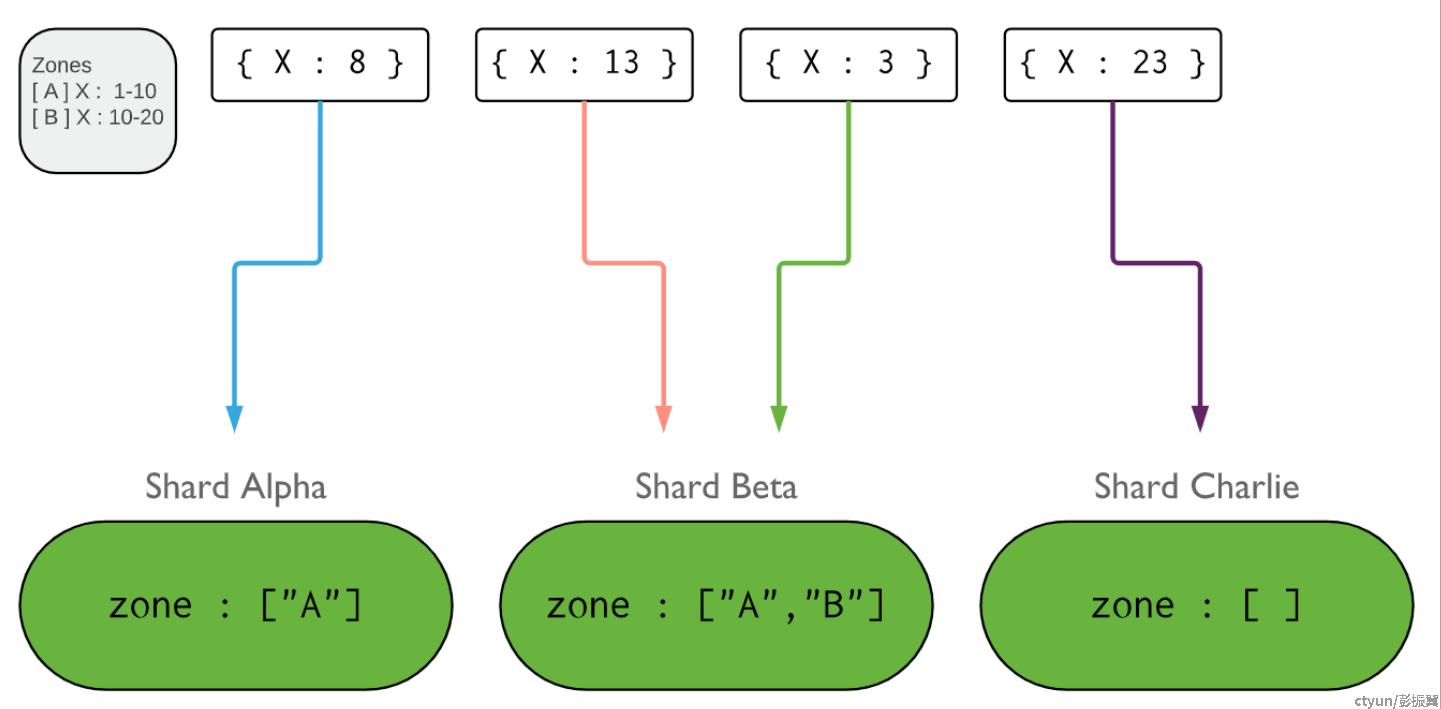
Zone 必须按照 shardKey 或者 shardKey 的前缀进行设置。属于某个 zone 的数据,在数据迁移时只会在同一个 zone 的多个shard 之间移动。
路由管理
无论是 range 分片还是 hash 分片,都至少需要维护以下 2 种信息:
- 表属性元数据。包括 shardKey、分片算法、创建时间以及是否删除等。
- 路由信息。描述了每个 chunk 的取值范围、存储在哪个 shard、版本号信息等。
MongoDB 分片集群在 config server 节点上使用 config 库存储这些信息,其中 config.collections 表存储了各个分片表的属性元数据,config.chunks 表存储了各个分片表的路由信息。
比如在一个 4.0 版本分片集群中,采用 hash分片方式创建了一个分片表 db2.shardcoll1, 则 config.collections 存储的属性元数据为:
mongos> use config
switched to db config
mongos> db.collections.find({ "_id" : "db2.shardcoll1"}).pretty()
{
"_id" : "db2.shardcoll1", // 表名
"lastmodEpoch" : ObjectId("64c725bcdae50f066c478c7f"), // 创建时间
"lastmod" : ISODate("1970-02-19T17:02:47.297Z"),
"dropped" : false, // 是否被删除
"key" : { // shardKey 和分片算法
"a" : "hashed"
},
"unique" : false, // shardKey是否具有唯一属性
"uuid" : UUID("0eafa40d-2b84-4326-9033-2cf8923a8c18") // 唯一 ID
}采用 hash 方式创建分片表后,默认会生成 2 个 chunk,路由表为:
mongos> use config
switched to db config
mongos> db.chunks.find({"ns" : "db2.shardcoll1"}).pretty()
{ // 第 1 个 chunk
"_id" : "db2.shardcoll1-a_MinKey", // 以表名和 chunk 的最小值作为 id
"ns" : "db2.shardcoll1", // 表名
"min" : { // 本 chunk 的最小值为 $minKey (包含)
"a" : { "$minKey" : 1 }
},
"max" : { // 本 chunk 的最大值为 0 (不包含)
"a" : NumberLong(0)
},
"shard" : "sharding_shard1", // 本 chunk 存储在 sharding_shard1 上
"lastmod" : Timestamp(1, 0), // 版本号
"lastmodEpoch" : ObjectId("64c725bcdae50f066c478c7f"), // 最近修改时间
"history" : [ // 历史记录
{
"validAfter" : Timestamp(1690772924, 6),
"shard" : "sharding_shard1"
}
]
}
{
"_id" : "db2.shardcoll1-a_0", // 以表名和 chunk 的最小值作为 id
"ns" : "db2.shardcoll1", // 表名
"min" : { // 本 chunk 的最小值为 0 (包含)
"a" : NumberLong(0)
},
"max" : { // 本 chunk 的最大值为 $maxKey (不包含)
"a" : { "$maxKey" : 1 }
},
"shard" : "sharding_shard1", // 本 chunk 存储在 sharding_shard1 上
"lastmod" : Timestamp(1, 1), // 版本号
"lastmodEpoch" : ObjectId("64c725bcdae50f066c478c7f"), // epoch 信息,最近修改时间
"history" : [ // 历史记录
{
"validAfter" : Timestamp(1690772924, 6),
"shard" : "sharding_shard1"
}
]
}对于数据量很大的分片表来说,其路由表也是非常大的。按照 1 个 chunk 默认 64 MB 来计算,1个 6TB 的分片表对应的路由表会有 10 万多条记录。而且随着数据不断写入,chunk 不断分裂使得路由表不断更新,如何感知路由变化以及快速进行路由同步就成了非常关键的问题。
路由表版本
MongoDB 采用版本控制方式来追踪路由变化,每个 chunk 的路由版本信息由 3 部分组成:
- Major Version, 主版本号,如果出现了迁移则 version 增加。
- Minor Version, 小版本,如果出现了 split 分裂则 version 增加。
- Epoch,ObjectId 类型的唯一 ID
根据上述 chunk version 派生出 2 个概念:
- Shard Version, 某个 shard 上维护的最高的 chunk version.
- Collection Version, 分片表全局最高的 chunk version.
路由信息同步
Config server 上存储的一定是最新而且最权威的路由信息,mongos 和 mongod 的路由信息都从 config server 增量获取。
对于 mongos 节点会在内存中维护路由信息,启动时没有路由信息,会从 config server 上做一次全量拉取。对于 mongod 节点,会在内存中维护路由信息,而且会在 config.cache.chunks.{ns} 表中缓存路由信息,而且这个缓存路由信息的表会进行主从同步。
路由信息的更新整体上采用懒加载的方式。具体来说,mongos 转发给 mongod 的请求会额外携带mongos 认为的路由版本信息,mongod 在收到请求之后会先进行路由版本比较。如果发现有某一方的版本比较旧,则先从 config server 上拉取到最新路由之后再进行请求重试。如果 2 边的路由版本一样,则正常执行请求。
Chunk 分裂
对于 4.0 及以下版本,会在 mongos 节点上记录每个 chunk 的写入情况。对于 4.2 及以上版本,会在 mongod 节点上记录 chunk 的大小。
如果 chunk 的大小达到了设定的阈值(默认 64MB),则会触发 chunk 分裂。分为 2 个步骤:
- SplitVector,确定分裂点。大致步骤为根据 shardKey 索引扫描出 chunk 的文档条数以及平均文档长度信息,然后将 chunk 划分成满足阈值大小的多个子 chunk。
- SplitChunk, 执行 chunk 分裂。由于 chunk 只是一个逻辑上的概念,因此不会涉及存储引擎侧的表变更,只会涉及到路由信息变更。大致流程为将分裂出的chunk 信息提交到 config server 并删除原先chunk 的路由信息,然后刷新 mongod 本地的路由表。
Balancer 数据均衡
Config server 主节点上会启动一个后台线程定期检查(默认 2 次操作之间间隔 10 s)分片表的 chunks 数量在各个分片之间是否均衡。是否均衡的评判标准为chunk 数量最多的 shard 和 chunk 数量最少的 shard 之间的差值是否超过了如下阈值:

如果满足迁移条件,则 config server 会通过 moveChunk 命令,通知 shard 之间进行 chunk 迁移。值得注意的是,chunk 数据移动不会经过 config server,只会在 shard 之间进行,config server 只会充当控制者角色。
数据迁移是非常消耗资源的,从运营经验来看,很多业务的请求毛刺都和数据均衡操作有关。因此,对于请求延迟敏感或资源使用率较高的用户,尽量使用 hash 分片保证数据分布均匀,并将数据均衡窗口配置在业务低峰期。
使用 MongoDB 分片集群的注意事项
- 合理选择 shardKey,避免出现数据和请求倾斜的情况,避免出现 jumbo chunk 导致负载不均。
- 分片集群尽量创建分片表。如果确实需要创建非分片表,也尽量不要放在同一个 db 中,避免出现该 db 所在的 primary shard 数据量过大或者负载过高。
- 使用 hash 分片时,尽量使用预分片时创建 initial chunks 的方式,这样可以避免后续的 chunk 分裂和迁移。
- 根据业务需求,配置合理的 balancer 运行窗口,尽量避开业务高峰期。
总结
MongoDB 原生支持了非常完善的数据分片能力,通过数据分片也使得 MongoDB 在应对海量数据时游刃有余。MongoDB 支持 range 和 hash 分片方式,并通过配置 zone 分区来进行更加灵活的控制。
MongoDB 通过路由版本控制来保证路由信息在多个节点上的一致性,并通过 chunk 自动分裂和迁移机制保证了数据均衡。
