


BSON 是什么
说起文档数据库,第一个想到的可能是 JSON. 比如 ElasticSearch, PostgreSQL, MySQL 等数据库中都能看到它的身影。
MongoDB 作为目前最流行的文档数据库,却没有直接使用 JSON,而是采用 BSON 格式来支持文档模型。
BSON 全称是 Binary JSON, 和 JSON 很像,但是采用二进制格式进行存储。
一条 BSON 文档的可视化表达如下:
{
"_id" : ObjectId("64af4b1a89c38e320882ed60"),
"name" : "zhang san",
"tele" : NumberLong("13212345678"),
"addr" : "beijing",
"score" : [
80,
90,
95
],
"info" : {
"male" : true,
"introduction" : "I am a student"
}
}BSON相比 JSON 有以下优势:
- 访问速度更快。BSON 会存储 Value 的类型和内存中的原始值,因此不需要进行字符串类型到其他类型的转换操作。以整型 12345678 为例,JSON 需要将字符串转成整型,而 BSON 中存储了整型类型标志,并用 4 个字节直接存储了整型值。对于 String 类型,会额外存储 String 长度,这样解析操作也会快很多;
- 存储空间更低。还是以整型 12345678 为例,JSON 采用明文存储的方式需要 8 个字节,但是 BSON 对于 Int32 的值统一采用 4 字节存储,Long 和 Double 采用 8 字节存储。 当然是否能节省存储空间也要看具体场景,比如对于小整型,BSON 消耗的空间反而更高;
- 数据类型更丰富。BSON 相比 JSON,增加了 BinData,TimeStamp,ObjectID,Decimal128 等类型,全部 BSON 类型参考官方文档;
MongoDB官方文档对此有比较权威直观的描述,总结如下:
| JSON | BSON | |
| 编码方式 | UTF-8 String | Binary |
| 数据类型 | String, Boolean, Number (Integer, Float, Long, Decimal128...), Array, Date, Timestamp, ObjectId, Raw Binary... | String, Boolean, Number (Integer, Float, Long, Decimal128...), Array, Date, Timestamp, ObjectId, Raw Binary... |
| 可读性 | Human and Machine | Machine Only |
下面对 BSON 的存储格式进行深入分析,并从代码级别分析 BSON 的存储和解析过程,使大家对 BSON 有更深入的了解。
BSON 存储格式
一条最简单的 BSON 文档,从前向后可以拆解成以下几个部分:
- 首先是文档的总长度, 占 4 个字节;
- 然后是多个BSONElement按照顺序排列。每个BSONElement包含的内容有:
- Value 类型,占 1 个字节;
- Key 的 C-String 表示形式,只存储 C-String内容,不存储长度,以 '\0' 结尾,占 len(Key)+1 个字节;
- Value 的二进制存储,比如 Int32 占 4 字节,Long 和 Double 占 8 个字节等,本文后续会对常用类型逐一举例分析;
- 文档以 '\0' 结尾,也就是在遍历 BSON 到末尾时,常见的 EOO(End Of Object),占 1 个字节;
下面列举常用的 Int32, Double, String, Object 内嵌文档,Array 类型,并分析它们的 16 进制表现形式。
Int 类型
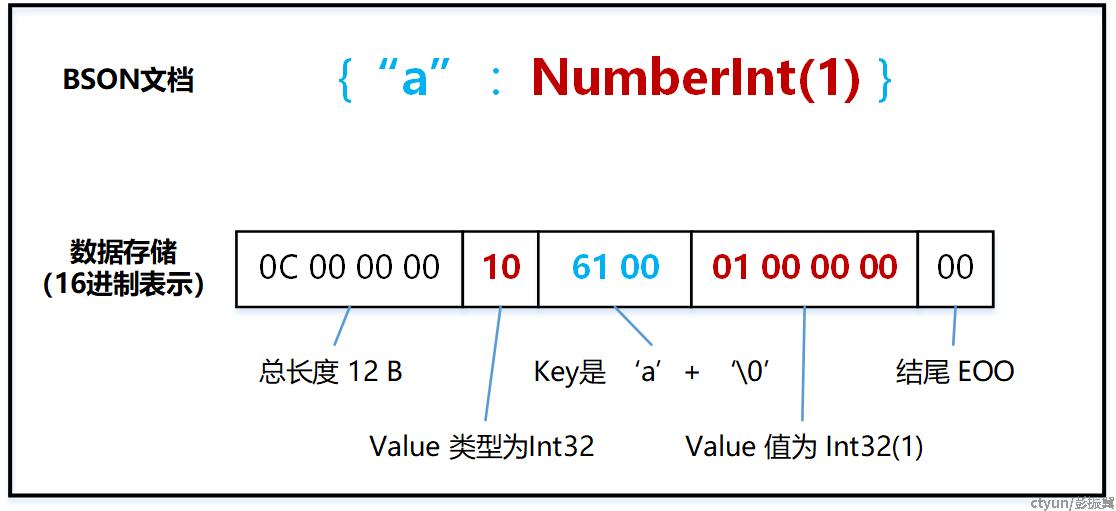
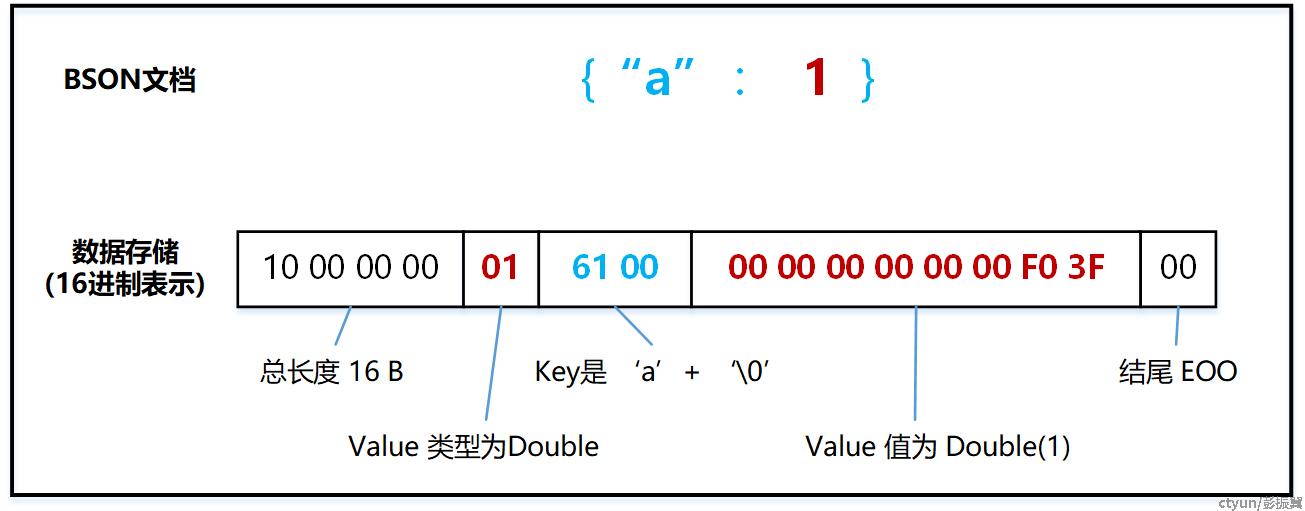
Double 类型
Double 类型占用 8 个字节空间(小端模式),使用 IEEE 754 标准转换成二进制存储。
String 类型,以及多个 KV 对
String 类型头部包含额外的 4 字节长度空间,并且以 '\0' 结尾。
需要注意的是,BSON 有 2 种 String 类型:
- C-String: 一般用于 Key ,以 '\0' 结尾,不存储长度信息;
- String: 一般用于 Value,以'\0' 结尾,头部会存储 4 字节的长度信息;
推测这样设计的好处是:
- Key 一般长度较短,可以很快解析。不需要额外 4 字节的存储和解析开销;
- Value 一般长度较长,通过存储 4 字节的长度信息,可以明显加快解析速度;

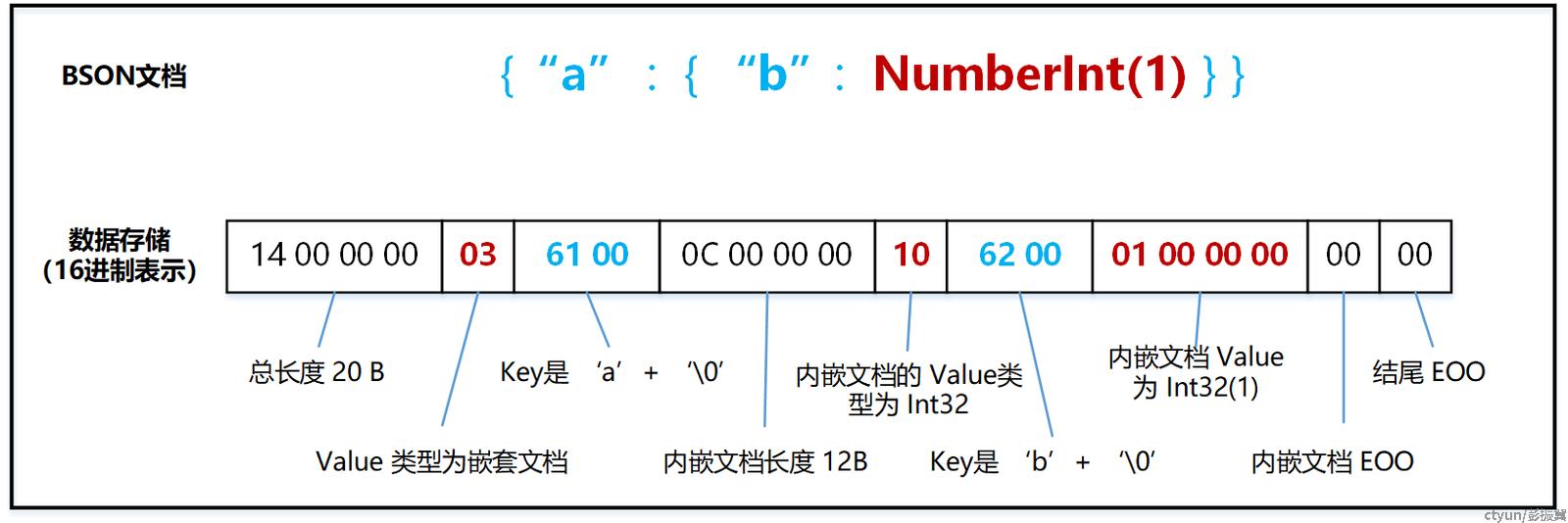
嵌套文档
嵌套文档和普通文档一样,头部也包含了额外的 4 字节长度空间。比如下面的例子 {"b" : NumberInt(1)} 的存储长度为 12 字节。
数组类型
数组类型头部有 4 个字节存储长度,每个元素都对应有下标,从 '0' 开始递增。
比如下面的例子中,"a.0" 表示第 1 个元素,值为 Double(1), "a.3" 表示第 4 个元素,值为 "4".

BSON 的序列化和反序列化
反序列化(解析)流程
解析 BSON文档 时,先用小端模式读取头部的 4 个字节,转换成 Int32 类型的长度信息,得到 BSON 文档的结束位置。
然后根据上一节介绍的 BSON 格式信息,不断获取 Value 类型, Key,以及 Value。通过迭代器重复上述上述流程得到 BSON 文档中的所有 KV 对。
上述流程可以参考 MongoDB 代码中对 BSONObj 和 BSONObjIterator 的定义。
部分关键代码摘抄如下:
// 根据传入的二进制 BSON 数据构造迭代器
explicit BSONObjIterator(const BSONObj& jso) {
int sz = jso.objsize(); // 小端模式读取头 4 个字节,得到 int32 类型的长度
if (MONGO_unlikely(sz == 0)) {
_pos = _theend = 0;
return;
}
_pos = jso.objdata() + 4; // 真正的起始位置
_theend = jso.objdata() + sz - 1; // 末尾
}
// 判断迭代器当前是否到了末尾
bool more() {
return _pos < _theend;
}
// 获取迭代器当前指向的 BSONElement(可以理解为一个 KV 数据),然后迭代器 ++
BSONElement next() {
verify(_pos <= _theend);
BSONElement e(_pos); // 从当前位置,封装 KV 数据
_pos += e.size(); // 迭代器 ++
return e;
}整个解析过程通过迭代器从前向后遍历,时间复杂度为 O(N). 但是由于 存储了 Value 长度的元数据信息,所以效率还是会比较高。
序列化流程
BSON 文档的封装流程可以看做是解析的逆过程。首先在头部保留 4 个字节,然后不断将 Value 类型,Key, Value 的二进制形式进行追加,然后在文档末尾加上 '\0' EOO 标志,最后将计算的长度(包括存储长度的 4 个字节本身)存储在头部预留的 4 个字节中。
上述流程可以参考 MongoDB 代码中对 BSONObjBuilder 的定义。
部分关键代码摘抄如下:
// 构造一个 BSONObjBuilder
BSONObjBuilder(int initsize = 512)
: _b(_buf), _buf(initsize), _offset(0), _s(this), _tracker(0), _doneCalled(false) {
// Skip over space for the object length. The length is filled in by _done.
_b.skip(sizeof(int)); // 头部预留 4 字节,在调用 _done() 时填充长度
// Reserve space for the EOO byte. This means _done() can't fail.
_b.reserveBytes(1); // 尾部预留 1 个字节的 EOO
}
// 往 BSONObjBuilder 中插入一条 Value 类型为 int32 的 KV 对
BSONObjBuilder& append(StringData fieldName, int n) {
_b.appendNum((char)NumberInt); // 先追加 Value 类型, 占 1 个字节
_b.appendStr(fieldName); // 追加字符串类型的 Key,以 '\0' 结尾
_b.appendNum(n); // 追加 4 字节的二进制整型 Value
return *this;
}
// KV 数据追加完毕之后,调用 done 方法处理收尾工作
char* _done() {
if (_doneCalled)
return _b.buf() + _offset;
_doneCalled = true;
// TODO remove this or find some way to prevent it from failing. Since this is intended
// for use with BSON() literal queries, it is less likely to result in oversized BSON.
_s.endField();
_b.claimReservedBytes(1); // Prevents adding EOO from failing.
_b.appendNum((char)EOO);
// 确定最终数据的起始位置和大小
// 这里的 _offset 用于嵌套 builder 共享一个 buffer 空间的场景,否则 _offset 为 0
char* data = _b.buf() + _offset;
int size = _b.len() - _offset;
DataView(data).write(tagLittleEndian(size)); // 将 size 使用小端模式写入头部 4 个字节中
if (_tracker)
_tracker->got(size);
return data; // 返回最终的数据
}如果初次接触 BSON,可能会认为如果只修改 BSON 中的某一个字段,底层只会原地更新这一小块数据,不会有很大开销。但是事实并非如此,从前面的描述可以看到,每个 KV 是顺序紧凑排列的,如果增加、删除或者修改了某个字段,要生成新 BSON 文档。
除了通过 BSONObjBuilder 流式生成 BSON 文档外,MongoDB 代码中也提供了 DOM 接口用于修改或者增删某个字段,但是修改完成后还是需要生成新的 BSON。除非是不改变 BSON 二进制结构的更新才支持 UpdateInPlace, 具体规则可以参考 Element::setValue 流程以及 DamageEvent 的定义。
性能测试
下面使用 Golang driver 对比了同样数据场景下,BSON 和 JSON 的长度和编解码性能。
使用的代码库:
JSON: Golang 内置的 JSON 库
BSON: MongoDB 官方提供的 go-driver
测试的数据类型:
double: 一个结构体包含 10 个 double 成员,分 “短” double(数值 0-10) 和 “长” double(数值 math.maxFloat64) 2 种场景。
int64: 一个结构体包含 10 个 long 成员,分 “短” int64(数值 0-10) 和 “长” int64(数值 math.maxInt64) 2 种场景。
string:一个结构体包含 10 个 string 成员,每个 string 成员的长度是 117 字节。
测试方法:
将每种类型的数据对象,分别使用 JSON 和 BSON 方式 marshal/unmarshal 各 100,000 次。 对比 长度、编码耗时、解码耗时。
测试结果如下(数字越小表现越好):
|
类型 |
BSON 长度 |
JSON 长度 |
BSON-Marshal 单次耗时(us) |
JSON-Marshal 单次耗时(us) |
BSON-Unmarshal 单次耗时(us) |
JSON-Unmarshal 单次耗时(us) |
|
“短” double * 10 |
126 |
73 |
1.4 |
1.3 |
2.1 |
2.8 |
|
“长” double * 10 |
126 |
292 |
1.3 |
1.8 |
2.0 |
4.7 |
|
“短”int64 * 10 |
126 |
72 |
1.4 |
0.5 |
1.7 |
2.6 |
|
“长” int64 * 10 |
126 |
252 |
1.4 |
0.9 |
2.0 |
4.1 |
|
String(117B) * 10 |
1266 |
1252 |
1.9 |
2.7 |
2.7 |
9.7 |
在存储空间(长度)方面:
对于 “长” double/int64 类型,BSON 在空间上,有一定优势。因为 BSON 使用固定 8 字节进行编码。
对于 “短” double/int64 类型,BSON 在空间上,存在劣势。还是因为 BSON 使用固定 8 字节编码的原因。
对于测试使用的 string 类型,BSON 并没有优势。
在序列化(marshal)效率方面:
对于测试使用的 “长” double 类型和 string 类型, BSON 均有10%-30% 的性能提升。
在 “短” double 类型上,BSON 和 JSON 性能相当。
对于 int64 类型,不管数据的长短,BSON 均有明显的性能下降。需要额外关注,并进一步分析。
在反序列化(unmarshal)效率方面:
BSON 优势非常明显。对于测试使用的 “长” double/int64 类型有 100% 的性能提升,对于 string 类型有 200% 以上的性能提升。
对于 “短” double/int64 类型,也有20% 以上的性能提升。
不同的业务场景和不同的数据类型在测试时会存在性能差异,因此上述测试结果仅供参考!
总结
BSON 作为 JSON 的一种扩展存储格式,在速度,存储空间和数据类型方面都有非常大的提升,并在 MongoDB 的文档模型中扮演了关键角色。本文从原理上对比了 BSON 和 JSON 的区别和优缺点,通过一些典型的例子深入分析了 BSON 的数据组织结构,并从代码入手介绍了 BSON 的读写流程和一些注意事项。
