DMS for Kafka 消费者poll的优化
更新时间 2023-12-22 15:07:48
最近更新时间: 2023-12-22 15:07:48
本文主要介绍DMS for Kafka 消费者poll的优化。
场景介绍
在DMS提供的原生Kafka SDK中,消费者可以自定义拉取消息的时长,如果需要长时间的拉取消息,只需要把poll(long)方法的参数设置合适的值即可。但是这样的长连接可能会对客户端和服务端造成一定的压力,特别是分区数较多且每个消费者开启多个线程的情况下。
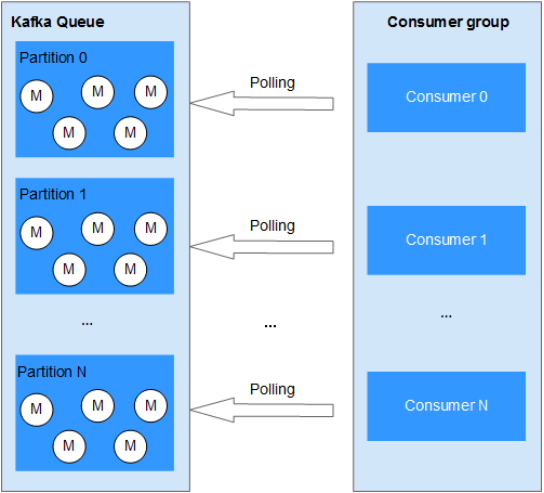
如图所示,Kafka队列含有多个分区,消费组中有多个消费者同时进行消费,每个线程均为长连接。当队列中消息较少或者没有时,连接不断开,所有消费者不间断地拉取消息,这样造成了一定的资源浪费。
图 Kafka消费者多线程消费模式
优化方案
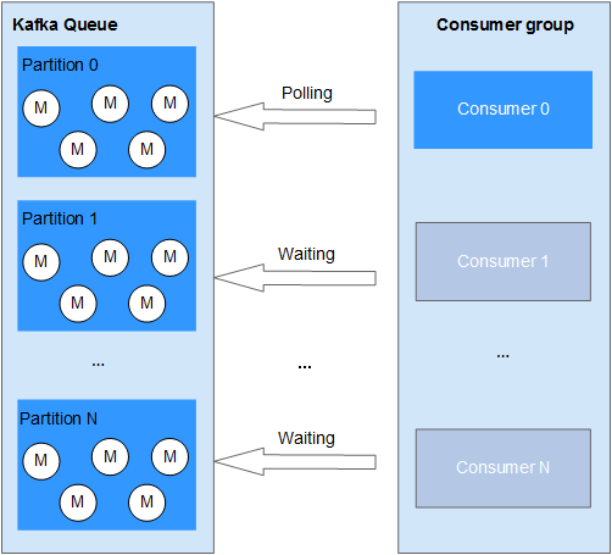
在开了多个线程同时访问的情况下,如果队列里已经没有消息了,其实不需要所有的线程都在poll,只需要有一个线程poll各分区的消息就足够了,当在polling的线程发现队列中有消息,可以唤醒其他线程一起消费消息,以达到快速响应的目的。如图所示。
这种方案适用于对消费消息的实时性要求不高的应用场景。如果要求准实时消费消息,则建议保持所有消费者处于活跃状态。
图 优化后的多线程消费方案
说明消费者(Consumer)和消息分区(Partition)并不强制数量相等,Kafka的poll(long)方法帮助实现获取消息、分区平衡、消费者与Kafka broker节点间的心跳检测等功能。
因此在对消费消息的实时性要求不高场景下,当消息数量不多的时候,可以选择让一部分消费者处于wait状态。

