对于DDS集群实例,如果某个集合的存储量很高,建议对该集合设置数据分片。分片是将数据按照某种方式拆分,将其分散存放在不同的机器上,以充分利用各分片节点的存储空间和 计算性能 。
设置数据分片
下面以数据库mytable,集合mycoll,字段“name”为分片键举例说明。
步骤 1 通过mongo shell登录分片集群实例。
步骤 2 判断集合是否已分片。
use <database>
db.<collection>.getShardDistribution()
示例:
use mytable
db.mycoll.getShardDistribution()

步骤 3 对集合所属的数据库启用分片功能。
- 方式一
sh.enableSharding("")
- 示例:
sh.enableSharding("mytable")
- 方式二
use admin
db.runCommand({enablesharding:"<database>"})
步骤 4 对集合进行分片。
- 方式一
sh.shardCollection("<database>.<collection>",{"<keyname>":<value> })
- 示例:
sh.shardCollection("mytable.mycoll",{"name":"hashed"},{numInitialChunks:5})
- 方式二
use admin
db.runCommand({shardcollection:"<database>.<collection>",key:{"keyname":<value> }})
表 参数说明
| 参数 | 说明 |
|---|---|
<database> |
数据库名称。 |
<collection> |
集合名称。 |
<keyname> |
分片键。集群实例将根据该值进行数据分片,请结合实际业务为集合选择合适的分片键,具体操作请参见下文选择合适的分片键。 |
<value> |
基于分片键的范围查询的排序方式。l、 1:表示索引升序。 -1:表示索引降序。 hashed:表示使用Hash分片,通常能将写入均衡分布到各个分片节点。 更多信息,请参见sh.shardCollection()。 |
numInitialChunks |
可选。当使用Hash分片键对空集合进行分片时,指定初始创建的最小分片数。 |
步骤 5 查看数据库在各分片节点的数据存储情况。
sh.status()
示例:

选择合适的分片键
- 背景
分片集群中数据的分片以集合为基础单位,集合中的数据通过分片键被分成多个部分。分片键是在集合中选择的一个合适的字段,数据拆分时以该分片键的值为依据均衡地分布到所有分片中。如果您没有选择到合适的的分片键,可能会降低集群的使用性能,出现执行分片语句时执行过程卡住的问题。
分片键一旦设置后不能再更改。如果未选取到合适的分片键,需要使用正确的分片策略,将数据迁移到新的集合后重新执行分片。
- 合适的分片键的特点
- 所有的插入、更新以及删除操作,将会均匀分发到集群中的所有分片中。
- key的分布足够离散。
- 尽量避免scatter-gather查询。
如果所选分片键不具备以上所有特点,将会影响集群的读写扩展性。例如,通过 find() 操作读取的工作量在分片中非均匀分布,最终会产生查询热分片。同样,如果写工作量(插入、更新和修改)在分片中非均匀分布,最终会产生写热分片,严重限制分片的优势。因此,您需要根据应用读写状态(重读取还是重写入)、经常查询及写入的数据等业务需求,调整您的分片键。
需要注意,对已有数据分片后,如果update请求的filter中未携带片键字段并且选项upsert:true或者multi:false,那么update 请求会报错,并返回“An upsert on a sharded collection must contain the shard key and have the simple collation.”
- 判断标准
您可以通过下表中的几个维度,判断所选分片键是否能够满足业务需求。
合理分片键的判断依据
| 判断依据 | 说明 |
|---|---|
| 片键基数 | 片键基数是指划分数据块的能力。例如,要记录某个学校的学生信息,由于学生的年龄比较集中,如果选择年龄作为分片键,同一个数据段中将存储很多同龄学生的数据,影响集群的性能以及可管理性。由于学生的学号唯一,如果选择学号作为分片键,分片基数较大,有利于数据的均匀分布。 |
| 写分布 | 若用户业务在同一时间段有大量写操作,则希望这些写操作能够均匀分布到各个分片上。如果数据分布策略为范围分片,并以一个单调递增的值作为分片键,此时,大量写入的数据同样是片键字段递增,数据将写入同一个分片。 |
| 读分发 | 若用户业务在同一时间段有大量读操作,则希望这些读操作能够均匀分布到各个分片上,以充分利用各分片节点的计算性能。 |
| 定向读 | mongos查询路由器可以执行定向查询(只查询一个分片)或scatter/gather查询(查询所有分片)。只有查询中存在分片键,mongos才能定位到单一分片,因此,您需要选择在业务运行时可用于普遍查询的分片键。如果您选择合成的分片键,将无法在定向查询中使用该片键,所有的查询方式将变成scatter/gather查询,从而限制扩展读数据的能力。 |
选择合适的数据分布策略
分片集群支持将单个集合的数据分散存储在多个分片上,用户可以根据集合内文档的分片键来分布数据。
目前,主要支持两种数据分布策略,即范围分片(Range based sharding)和Hash分片(Hash based sharding),设置方式请参见步骤4。
下面分别介绍这两种数据分布策略以及各自的优缺点。
- 范围分片
基于范围进行分片,即集群按照分片键的范围把数据分成不同部分。假设有一个数字分片键,为一条从负无穷到正无穷的直线,每一个片键的值均在直线上进行标记。可以理解为将该直线划分为更短的不重叠的片段,并称之为数据块,每个数据块包含了分片键在一定的范围内的数据。
图 数据分布示意图

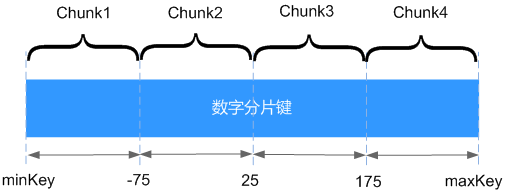
如上图所示,x表示范围分片的片键,x的取值范围为[minKey,maxKey],且为整型。将整个取值范围划分为多个chunk,每个chunk(通常配置为64MB)包含其中一小段的数据。其中,chunk1包含x值在[minKey, -75]中的所有文档,每个chunk的数据都存储在同一个分片上,每个分片可以存储多个chunk,并且chunk存储在分片中的数据会存储在config服务器中,mongos也会根据各分片上的chunk的数据自动执行负载均衡。
范围分片能够很好的满足范围查询的需求,例如,查询x的取值在[-60,20]中的文档,仅需mongos将请求路由到chunk2。
范围分片的缺点在于,如果分片键有明显递增(或递减)趋势,新插入的文档很大程度上会分布到同一个chunk,从而无法扩展写的能力。例如,使用“_id”作为分片键,集群自动生成id的高位值将是递增的时间戳。
- Hash分片
根据用户的分片键值计算出Hash值(长度64bit且为整型),再按照范围分片策略,根据Hash值将文档分布到不同的chunk中。基于Hash分片主要的优势为保证数据在各节点上分布基本均匀,具有“相近”片键的文档很可能不会存储在同一个数据块中,数据的分离性更高。
图 数据分布示意图
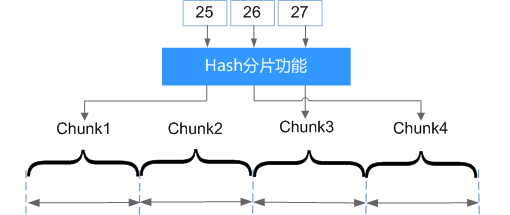

Hash分片与范围分片互补,能将文档随机分散到各个chunk,充分扩展写能力,弥补范围分片的不足。但所有的范围查询要分发到后端所有的分片,才能获取满足条件的文档,查询效率低。

