版本差异
DCS在创建实例时,Redis可选择“版本号”、“实例类型”。
- 版本号
版本号共有3.0,4.0,5.0,6.0,它们的区别如下表。更多Redis 4.0和Redis 5.0的特性,请参考“Redis4.0支持的新特性说明”和“Redis 5.0支持的新特性说明”章节。
不同版本支持的特性、性能差异说明
| 比较项 | Redis 3.0 | Redis 4.0 & Redis 5.0 | Redis 6.0 |
|---|---|---|---|
| 兼容开源版本 | Redis 3.0兼容开源3.0.7版本 | Redis 4.0兼容开源4.0.14版本Redis 5.0最新版本兼容开源5.0.14版本。存量用户可以参考查询Redis原生版本进行查询。 | Redis 6.0兼容开源6.2.7版本 |
| 实例部署模式 | 采用虚机部署 | 在物理机上容器化部署 | 在物理机上容器化部署 |
| CPU架构 | 支持x86和Arm | 支持x86和Arm | 支持x86 |
| 创建实例耗时 | 3-15分钟,集群约10-30分钟 | 约8秒 | 约8秒 |
| QPS | 单节点约10万QPS | 单节点约10万QPS | 单节点约15万QPS |
| 可视化数据管理 | 不支持 | 提供Web CLI访问Redis,管理数据 | 提供Web CLI访问Redis,管理数据 |
| 实例类型 | 支持单机、主备、Proxy集群 | 支持单机、主备、Proxy集群、Cluster集群、读写分离 | 支持单机、主备 |
| 实例规格 | 提供2G、4G、8G直至1024G多种规格 | 提供2G、4G、8G直至1024G多种规格,同时单机主备还支持128MB、256MB、512MB、1GB四种小规格实例 | 提供4G、8G、16G、32G、64G多种规格,同时单机主备还支持128MB、256MB、512MB、1GB四种小规格实例 |
| 扩容/缩容 | 支持在线扩容和缩容 | 支持在线扩容和缩容 | 支持在线扩容和缩容 |
| 备份恢复 | 主备和集群实例支持 | 主备、读写分离、集群实例支持 | 主备 |
说明由于Redis不同版本的底层架构不一样,在创建Redis实例时,确定Redis版本后,将不能修改,如Redis 3.0暂不支持升级到Redis 4.0或者Redis 5.0。如果需要由低版本升级到高版本,建议重新创建高版本实例,然后进行数据迁移。
- 实例类型
Redis实例类型分为单机、主备、读写分离、Proxy集群、Cluster集群,它们的架构与应用场景,请参考“实例类型”章节。
Redis4.0支持的新特性说明
与Redis 3.0版本相比,Redis 4.0及以上版本,除了开源Redis增加的特性之外,创建耗时也相应缩短。
实例由虚机方式改成了物理机容器化部署,创建实例只需要8~10秒时间完成。
Redis 4.0版本更新的特性,主要涉及三个方面:
- 新命令的增加,如MEMORY、SWAPDB。
- Lazyfree机制,延迟删除大key,降低删除操作对系统资源的占用影响。
- 内存性能优化,即主动碎片整理。
MEMORY命令
在Redis 3.0及之前,只能通过info memory命令了解有限的几个内存统计信息。Redis 4.0引入新的命令memory,让您能够更深入了解Redis的内存使用情况。
127.0.0.1:6379[8]> memory help
1) MEMORY <subcommand> arg arg ... arg. Subcommands are:
2) DOCTOR - Return memory problems reports.
3) MALLOC-STATS -- Return internal statistics report from the memory allocator.
4) PURGE -- Attempt to purge dirty pages for reclamation by the allocator.
5) STATS -- Return information about the memory usage of the server.
6) USAGE <key> [SAMPLES <count>] -- Return memory in bytes used by <key> and its value. Nested values are sampled up to <count
> times (default: 5).
127.0.0.1:6379[8]>
usage
输入 memory usage [key] ,如果当前key存在,则返回key的value实际使用内存估算值;如果key不存在,则返回nil。
127.0.0.1:6379[8]> set dcs "DCS is an online, distributed, in-memory cache service compatible with Redis, and Memcached."
OK
127.0.0.1:6379[8]> memory usage dcs
(integer) 141
127.0.0.1:6379[8]>
 说明
说明
- usage统计value内存占用,以及key自身的内存占用,不包含key的Expire内存占用。
//以下内容基于Redis 5.0.2版本验证,不同Redis版本,统计结果可能有差异。
192.168.0.66:6379> set a "Hello, world!"
OK
192.168.0.66:6379> memory usage a
(integer) 58
192.168.0.66:6379> set abc "Hello, world!"
OK
192.168.0.66:6379> memory usage abc
(integer) 60 //key名称长度变化后,内存占用也有变化,说明usage统计包含了key自身的占用
192.168.0.66:6379> expire abc 1000000
(integer) 1
192.168.0.66:6379> memory usage abc
(integer) 60 //加了过期时间后,内存占用没有改变,说明usage统计不包含expire内存占用
192.168.0.66:6379>
- 对hash、list、set、sorted set等数据类型,usage命令会抽样统计,提供内存占用的估算值。
使用方式:**memory usage **keyset **samples **1000
其中keyset表示一个集合数据类型的key,1000表示抽样个数。
stats
返回当前实例内存使用细节。
使用方法:memory stats
127.0.0.1:6379[8]> memory stats
1) "peak.allocated"
2) (integer) 2412408
3) "total.allocated"
4) (integer) 2084720
5) "startup.allocated"
6) (integer) 824928
7) "replication.backlog"
... ...
以下给出部分数据返回项的具体含义
memory stats
| 数据返回项 | 说明 |
|---|---|
| peak.allocated | Redis实例运行过程中,allocator分配的内存峰值。同info memory的used_memory_peak |
| total.allocated | allocator当前分配的内存字节数。同info memory的used_memory |
| startup.allocated | Redis启动占用的内存字节数 |
| replication.backlog | Redis复制积压缓冲区(replication backlog)内存使用字节数,通过repl-backlog-size参数设置,默认1M |
| clients.slaves | 在master侧,所有slave clients消耗的内存字节数 |
| clients.normal | Redis所有常规客户端消耗内存字节数 |
| overhead.total | Redis额外的总开销内存字节数; 即分配器分配的总内存total.allocated,减去数据实际存储使用内存。 |
| keys.count | Redis实例中key的数量 |
| keys.bytes-per-key | 每个key平均占用字节数。注意,overhead也会均摊到每个key上,因此不能以此值来表示业务实际的key平均长度。 |
| dataset.bytes | 表示Redis数据占用的内存容量。即分配的内存总量,减去总的额外开销内存量。 |
| dataset.percentage | 表示Redis数据占用内存占总内存分配的百分比 |
| peak.percentage | 当前内存使用量与峰值时的占比 |
| fragmentation | 表示Redis的内存碎片率 |
doctor
使用方法: memory doctor
used_memory(total.allocated)小于5M,doctor认为内存使用量过小,不做进一步诊断。当满足以下某一点,Redis会给出诊断结果和建议:
- peak分配内存大于当前total_allocated的1.5倍,即peak.allocated/total.allocated > 1.5,说明内存碎片率高,RSS远大于used_memory
- High fragmentation/fragmentation大于1.4,说明内存碎片率高
- 每个Normal Client平均使用内存大于200KB,说明pipeline可能使用不当,或Pub/Sub客户端处理消息不及时
- 每个Slave Client平均使用内存大于10MB,说明master的写入流量过高
purge
使用方法:memory purge
用途:通过调用jemalloc内部命令,进行内存释放。释放对象包括Redis进程占用但未有效使用的内存,即常说的内存碎片。
说明memory purge只适用于使用jemalloc作为allocator的Redis实例。
Lazy free机制
解决的痛点/问题
Redis是单线程程序,当运行一个耗时较大的请求时,会导致所有请求排队等待,在请求处理完成前,Redis不能响应其他请求,因此容易引发性能问题。而Redis删除大的集合键时,就属于一种比较耗时的请求。
原理
Redis 4.0提供的一种惰性删除或者说延迟释放机制,主要用于解决删除大key对Redis进程的阻塞,从而避免带来性能与可用性问题。
删除key时,Redis异步延时释放key的内存,把key释放操作放在bio(Background I/O)单独的子线程处理中。
使用方法
- 主动删除
- unlink
unlink与del命令目的一样,删除某个key。unlink在删除集合类键时,如果集合键的元素个数大于64个,会把内存释放操作,给单独的bio(Background I/O)线程来执行。因此unlink删除操作能在非常短的时间内完成包含上百万个元素的大key删除。
- flushall /flushdb
通过对flushall/flushdb添加ASYNC异步清理选项,Redis在清理整个实例或单个DB时,操作都是异步的。
- 过期key删除、大key驱逐删除
被动删除有四种场景,每种场景对应一个配置参数,默认都是关闭:
lazyfree-lazy-eviction no //针对redis内存使用达到maxmeory,并设置有淘汰策略时,是否采用lazy free机制
lazyfree-lazy-expire no //针对设置有TTL的键,过期后,被redis清理删除时是否采用lazy free机制
lazyfree-lazy-server-del no //针对有些指令在处理已存在的键时,会带有一个隐式的DEL键的操作
slave-lazy-flush no //针对slave进行全量数据同步,slave在加载master的RDB文件前,会运行flushall来清理自己的数据场景
说明以上配置如需使用,请咨询技术服务人员。
其他新增命令
- swapdb
用途:交换同一Redis实例内2个db的数据。
用法:swapdb dbindex1 dbindex2
- zlexcount
用途:在有序集合中,返回符合条件的元素个数。
用法:zlexcount key min max
内存使用和性能改进
- 使用更少的内存来存储相同数量的数据
- 可以对使用的内存进行碎片整理,并逐渐回收
Redis5.0支持的新特性说明
DCS的Redis 5.0版本继承了Redis 4.0版本的所有功能增强以及新的命令,同时还兼容开源Redis 5.0版本的新增特性。
Stream数据结构
Stream是Redis 5.0引入的一种新数据类型,它是一个全新的支持多播的可持久化消息队列。
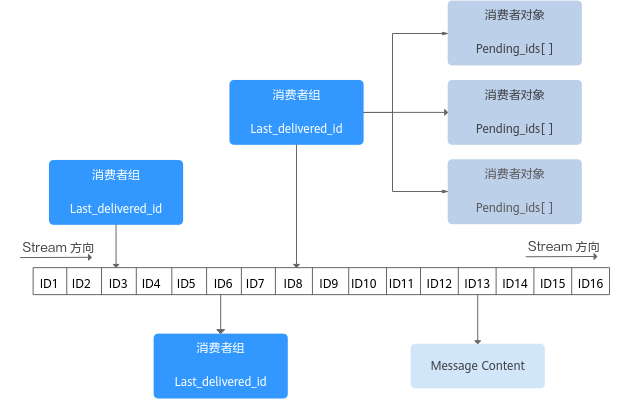
Redis Stream的结构示意图如下图所示,它是一个可持久化的数据结构,用一个消息链表,将所有加入进来的消息都串起来。
Stream数据结构具有以下特性 :
- Stream中可以有多个消费者组。
- 每个消费组都含有一个Last_delivered_id,指向消费组当前已消费的最后一个元素(消息)。
- 每个消费组可以含有多个消费者对象,消费者共享消费组中的Last_delivered_id,相同消费组内的消费者存在竞争关系,即一个元素只能被其中一个消费者进行消费。
- 消费者对象内还维持了一个Pending_ids,Pending_ids记录已发送给客户端,但是还没完成ACK(消费确认)的元素id。
- Stream与Redis其他数据结构的比较,见下表。
Stream数据结构示意图

Stream与Redis现有数据结构比较
| 比较项 | Stream | List、Pub/Sub、Zset |
|---|---|---|
| 复杂度 | 获取元素高效,复杂度为O(logN) | List获取元素的复杂度为O(N) |
| offset | 支持offset,每个消息元素有唯一id。不会因为新元素加入或者其他元素淘汰而改变id。 | List没有offset概念,如果有元素被逐出,无法确定最新的元素 |
| 持久化 | 支持消息元素持久化,可以保存到AOF和RDB中。 | Pub/Sub不支持持久化消息。 |
| 消费分组 | 支持消费分组 | Pub/Sub不支持消费分组 |
| 消息确认 | 支持ACK(消费确认) | Pub/Sub不支持 |
| 性能 | Stream性能与消费者数量无明显关系 | Pub/Sub性能与客户端数量正相关 |
| 逐出 | 允许按时间线逐出历史数据,支持block,给予radix tree和listpack,内存开销少。 | Zset不能重复添加相同元素,不支持逐出和block,内存开销大。 |
| 删除元素 | 不能从中间删除消息元素。 | Zset支持删除任意元素 |
Stream相关命令介绍
接下来按照使用流程中出现的顺序介绍 Stream相关命令 。详细命令见下表
- 首先使用XADD添加流元素,即创建Stream,添加流元素时可指定消息数量最大保存范围。
- 然后通过XGROUP创建消费者组。
- 消费者使用XREADGROUP指令进行消费。
- 客户端消费完毕后使用XACK命令确认消息已消费成功。
Stream相关命令介绍
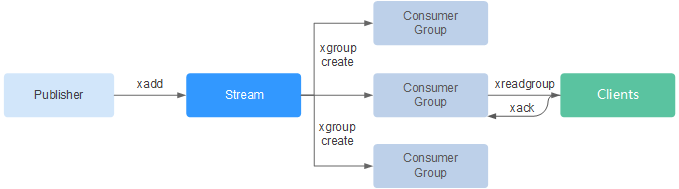

Stream的详细命令
| 命令 | 说明 | 语法 |
|---|---|---|
| XACK | 从流的消费者组的待处理条目列表 (简称PEL)中删除一条或多条消息。 | XACK key group ID [ID ...] |
| XADD | 将指定的流条目追加到指定key的流中。 如果key不存在,作为运行这个命令的副作用,将使用流的条目自动创建key。 | XADD key ID field string [field string ...] |
| XCLAIM | 在流的消费者组上下文中,此命令改变待处理消息的所有权,因此新的所有者是在命令参数中指定的消费者。 | XCLAIM key group consumer min-idle-time ID [ID ...] [IDLE ms] [TIME ms-unix-time] [RETRYCOUNT count] [FORCE] [JUSTID] |
| XDEL | 从指定流中移除指定的条目,并返回成功删除的条目的数量,在传递的ID不存在的情况下, 返回的数量可能与传递的ID数量不同。 | XDEL key ID [ID ...] |
| XGROUP | 该命令用于管理流数据结构关联的消费者组。使用XGROUP你可以:l 创建与流关联的新消费者组。l 销毁一个消费者组。l 从消费者组中移除指定的消费者。l 将消费者组的最后交付ID设置为其他内容。 | XGROUP [CREATE key groupname id-or-] [SETID key id-or- ] [DESTROY key groupname] [DELCONSUMER key groupname consumername] |
| XINFO | 检索关于流和关联的消费者组的不同的信息。 | XINFO [CONSUMERS key groupname] key key [HELP] |
| XLEN | 返回流中的条目数。如果指定的key不存在,则此命令返回0,就好像该流为空。 | XLEN key |
| XPENDING | 通过消费者组从流中获取数据。检查待处理消息列表的接口,用于观察和了解消费者组中哪些客户端是活跃的,哪些消息在等待消费,或者查看是否有空闲的消息。 | XPENDING key group [start end count] [consumer] |
| XRANGE | 返回流中满足给定ID范围的条目。 | XRANGE key start end [COUNT count] |
| XREAD | 从一个或者多个流中读取数据,仅返回ID大于调用者报告的最后接收ID的条目。 | XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...] |
| XREADGROUP | XREAD命令的特殊版本,指定消费者组进行读取。 | XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...] |
| XREVRANGE | 与XRANGE相同,但显著的区别是以相反的顺序返回条目,并以相反的顺序获取开始-结束参数 | XREVRANGE key end start [COUNT count] |
| XTRIM | XTRIM将流裁剪为指定数量的项目,如有需要,将驱逐旧的项目(ID较小的项目)。 | XTRIM key MAXLEN [~] count |
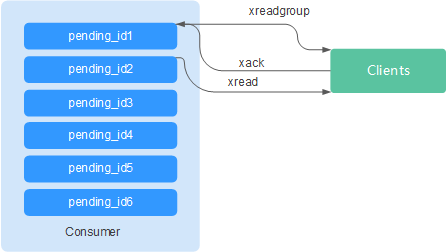
消息(流元素)消费确认
Stream与相比Pub/Sub,不仅增加消费分组模式,还支持消息消费确认。
当一条消息被某个消费者调用XREADGROUP命令读取或调用XCLAIM命令接管的时候, 服务器尚不确定它是否至少被处理了一次。 因此, 一旦消费者成功处理完一条消息,它应该调用XACK知会Stream,这样这个消息就不会被再次处理, 同时关于此消息的PEL(pending_ids)条目也会被清除,从Redis服务器释放内存 。
某些情况下,因为网络问题等,客户端消费完毕后没有调用XACK,这时候PEL内会保留对应的元素ID。待客户端重新连上后,XREADGROUP的起始消息ID建议设置为0-0,表示读取所有的PEL消息及自last_id之后的消息。同时,消费者消费消息时需要能够支持消息重复传递。
ACK机制解读

内存使用优化
Redis 5.0在上一版本基础上,在内存使用上做了进一步优化。
- 主动碎片整理
当key被频繁修改,value长度不断变化时,Redis会为key分配新的内存空间。由于Redis追求高性能,实现了自己的内存分配器来管理内存,因此并不会将原有内存释放给OS,从而导致出现内存碎片。当used_memory_rss/used_memory高于1.5,一般认为内存碎片占比过高,内存利用率低。
因此,合理规划和使用缓存数据,规范数据写入,有助于减少内存碎片的产生。
Redis 3.0及以下:可以通过定期重启服务解决内存碎片问题。建议实际缓存数据不超过配置可用内存的50%。
Redis 4.0:支持主动整理内存碎片,服务在运行期间进行自动内存碎片清理。同时Redis 4.0支持通过memory purge命令手动清理内存碎片。
Redis 5.0:增强版主动碎片整理,配合Jemalloc版本更新,更快更智能,延时更低。
- HyperLogLog算法优化
HyperLogLog是一种基数计数方法,使用少量的内存空间完成海量数据的计数统计,在Redis 5.0中,HyperLogLog算法得到改进,优化了计数统计时的内存使用效率。
举个例子:B树计数效率非常高,但是内存消耗也比较多。而HyperLogLog可节省大量存储空间。当B树需要1M内存统计,HyperLogLog只需要1kb。
- 内存信息统计报告能力增强
INFO命令返回信息更加详实。
命令新增和优化
- 客户端管理增强
- Redis-cli支持集群管理
在Redis 4.0以及之前版本,需要安装redis-trib模块,管理集群。
Redis 5.0对Redis-cli做了优化,集成了集群的所有管理功能。具体使用可以通过命令redis-cli --cluster help查看帮助信息。
- 优化客户端在频繁连接与中断场景下的性能
当您的应用需要使用短连接时,这个优化价值凸显。
2.有序集合使用更简单
有序集合新增两个命令:ZPOPMIN和ZPOPMAX。
- ZPOPMIN key [count]
删除并返回有序集合key中的最多count个具有最低得分的成员。如果返回多个成员,也会按照得分高低(value值比较),从低到高排列。
- ZPOPMAX key [count]
删除并返回有序集合key中的最多count个具有最高得分的成员。如果返回多个成员,也会按照得分高低(value值比较),从高到低排列。
3.help增加更多子命令说明
支持help直接查看快速使用攻略,你不再需要每次登录redis.io去查找。例如,命令行输入stream使用攻略:xinfo help
127.0.0.1:6379> xinfo help
1) XINFO <subcommand> arg arg ... arg. Subcommands are:
2) CONSUMERS <key> <groupname> -- Show consumer groups of group <groupname>.
3) GROUPS <key> -- Show the stream consumer groups.
4) STREAM <key> -- Show information about the stream.
5) HELP -- Print this help.
127.0.0.1:6379>
4.Redis-cli命令输入提示
Redis-cli在输入完整的命令后,会展示参数提醒,帮助用户记忆命令语法格式。
如下图所示,输入zadd命令,Redis-cli使用浅颜色字体显示zadd的语法。

RDB支持存储LFU、LRU
Redis 5.0开始,RDB快照文件中增加存储key逐出策略LRU和 LFU :
- FIFO:先进先出。最早存储的数据,优先被淘汰。
- LRU:最近最少使用。长期未使用的数据,优先被淘汰。
LFU:最不经常使用。在一段时间内,使用次数最少的数据,优先被淘汰。
说明Redis 5.0的RDB文件格式有变化,向下兼容。因此如果使用快照的方式迁移,可以从Redis低版本迁移到Redis 5.0,但不能从Redis 5.0迁移到低版本。
DCS实例的CPU规格是怎么样的
使用DCS实例的用户无需关心CPU规格的指标,仅需关心QPS,带宽,内存大小等核心指标。
Redis实例基于开源Redis构造,开源Redis只能使用单个主线程处理命令,因此只能利用一个核的CPU,用户只需认为单个Redis节点使用1核CPU即可。
Redis由于社区版单线程处理模型的限制,如需增加实例CPU处理性能,则需要使用集群类型的Redis实例,通过增加分片的方式,来增加整个集群的处理性能。集群实例每个节点默认分配1核CPU进行处理。
如何查询Redis实例的原生版本
连接需要查询的实例,执行info命令:
查询实例信息