1.背景介绍
1.1. DeepSeek模型
DeepSeek 2025年初发布DeepSeek-R1(671B),性能对齐OpenAI o1正式版;6款通过R1蒸馏小模型,多项性能超过OpenAI o1-mini。因其优异性能及开源模式引发国内外广泛关注。
DeepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。
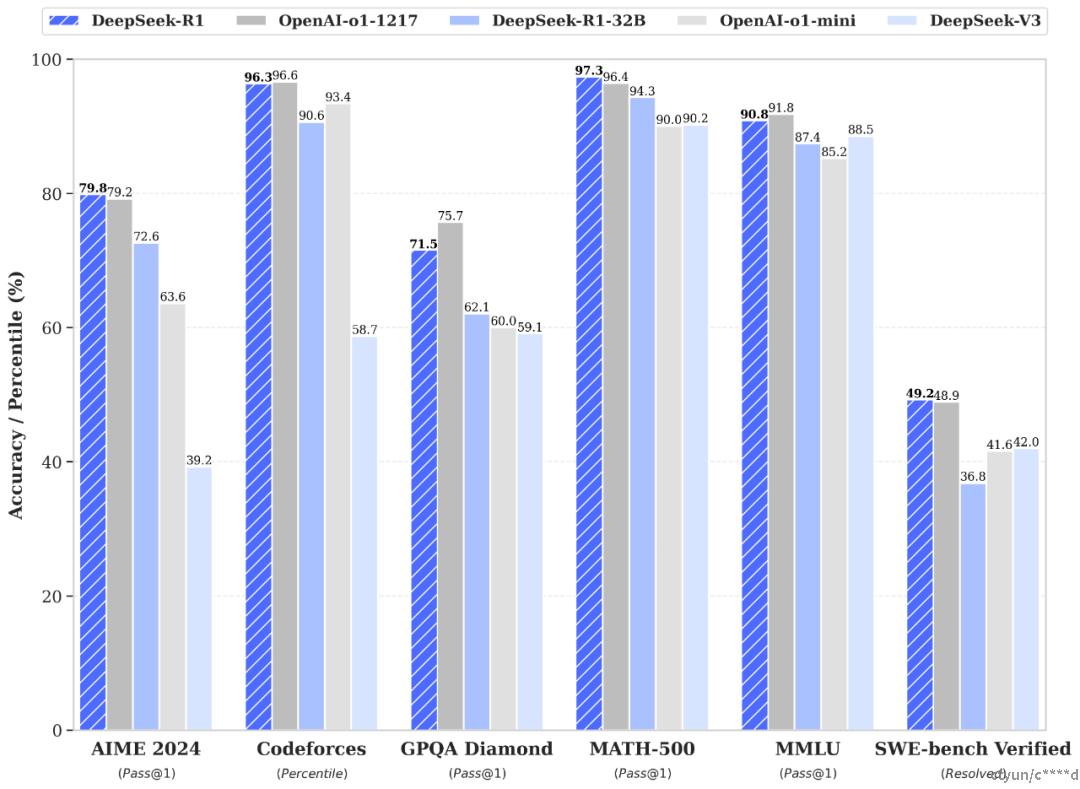
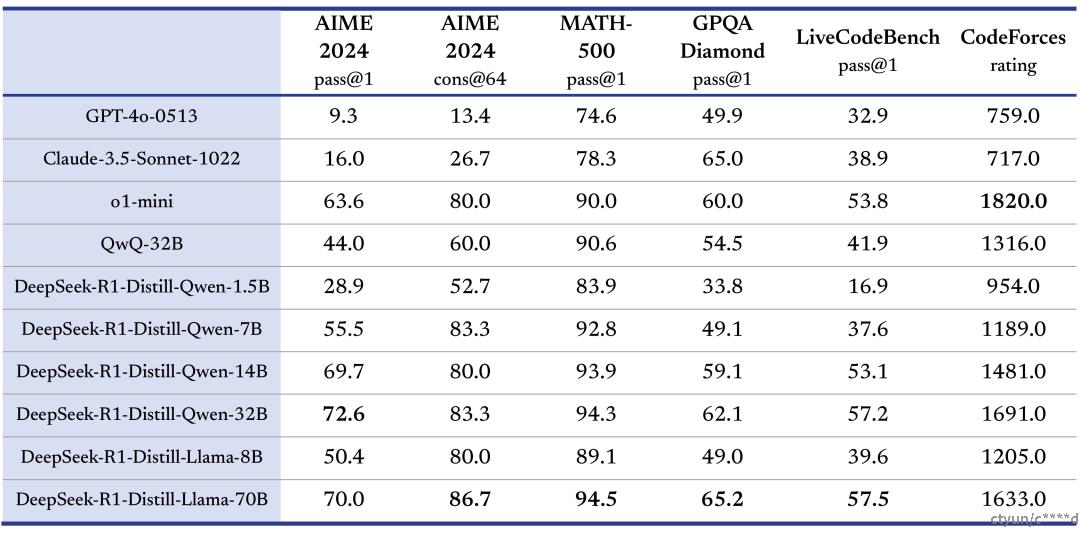
通过 DeepSeek-R1 的输出,蒸馏了 6 个小模型(DeepSeek-R1-Distill-Qwen-1.5B\7B\14B\32B、DeepSeek-R1-Distill-Llama-8B\70B)开源给社区,其中 32B 和 70B 模型在多项能力上实现了对标 OpenAI o1-mini 的效果。
1.2. 自研GPU虚拟化技术
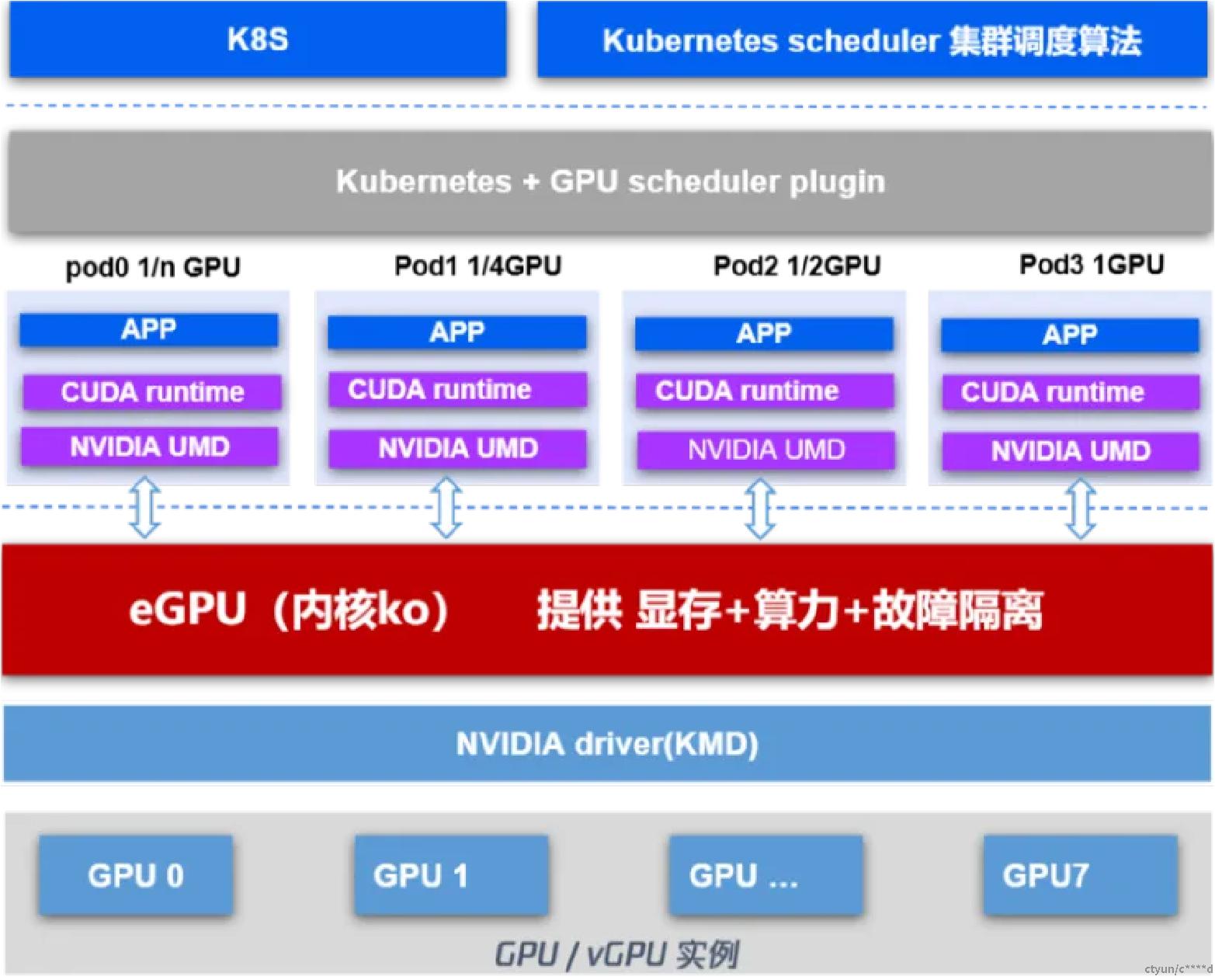
天翼云基于内核虚拟化技术并结合自研调度框架研发了容器GPU共享解决方案eGPU,实现GPU资源安全,灵活和高效的应用。该方案在确保性能和故障隔离的基础上,支持多个容器共享单张 GPU 显卡,并实现算力和显存的灵活调度与严格隔离。
1.2.1. eGPU 的主要功能
- 虚拟化与资源分配
a.eGPU 通过虚拟化技术,将物理 GPU 卡按需切分成多个虚拟 GPU,每个虚拟 GPU 可以分配给不同的容器,从而实现资源的最大化利用。
b.支持多容器共享同一张物理 GPU 卡,同时保证各容器间的资源隔离和独立性。
- 细粒度控制
a.eGPU 提供对 GPU 算力和显存的精细调度,可以根据不同应用场景的需求,灵活调整分配给各个容器的算力和显存。
b.用户可以通过 /proc/egpu 下的接口监控和管理 GPU 资源的分配情况,查看当前使用情况、剩余资源以及运行的进程等信息。
- 灵活的资源管理
a.eGPU 内核接口提供了详细的文件和接口,用于监控和管理 eGPU 设备和容器,包括版本信息、日志信息、内存使用情况等。
b.通过 eGPU 的命令行实用程序 egpu-smi,可以方便地监控和管理 eGPU 容器,确保各容器的资源使用合理且高效。
1.2.2. 方案框架图
eGPU 方案框架图如下:
2.部署体验
在部署DeepSeek小模型推理任务时,可能不需要整块GPU卡资源,本章将聚焦小参数模型单卡部署体验。以V100 GPU云主机为例介绍eGPU插件安装,并在资源上部署DeepSeek 1.5B、7B、14B蒸馏模型的过程。
规格切分建议
案例采用Ollama 部署模型,默认使用 4-bit 量化,GPU显存占用可以相对减少,GPU算力按需求自行设置(算力分配影响推理速度)。
|
模型 |
GPU显存,GB 最小MB级别划分 |
GPU算力,% 最小1%粒度划分 |
CPU,核 |
内存,GB |
|
DeepSeek-R1-Distill-Qwen-1.5B |
>=5GB |
按需分配 |
>=4核 |
>=8GB |
|
DeepSeek-R1-Distill-Qwen-7B |
>=8GB |
按需分配 |
>=8核 |
>=16GB |
|
DeepSeek-R1-Distill-Qwen-14B |
>=16GB |
按需分配 |
>=16核 |
>=32GB |
|
DeepSeek-R1-Distill-Llama-8B |
>=8GB |
按需分配 |
>=8核 |
>=16GB |
步骤一:开通云主机
创建配备GPU驱动的GPU云主机(Linux)-GPU云主机-用户指南-创建GPU云主机 - 天翼云
步骤二:安装eGPU插件
1.安装nvidia-container-toolkit
在线安装 nvidia-container-toolkit: https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html#
nvidia-ctk --version

2.安装egpu
./egpu.run
注意:run包请联系客户经理沟通获取。
3.检查是否安装成功
lsmod | grep egpu


步骤三:手动部署DeepSeek
1.确保GPU云服务器中已安装ollama和已下载deepseek模型文件(安装和下载方法详见文章《在天翼云使用Ollama运行DeepSeek的最佳实践-7b版》)
ollama ls


2.准备两个文件:ollama.service和setup.sh,其作用是在容器中配置ollama的服务。
 a.ollama.service:
a.ollama.service:
将云主机中/etc/systemd/system/ollama.service复制粘贴至当前路径,并修改模型存储位置为容器中的模型路径:Environment="OLLAMA_MODELS=/home/models"。其中/home/models为容器中模型的保存路径。
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=root
Group=root
Restart=always
RestartSec=3
Environment="PATH=$PATH"
# 指定模型存储位置(容器内部模型的路径)
Environment="OLLAMA_MODELS=/home/models"
[Install]
WantedBy=default.targetb.setup.sh:
#!/bin/bash
systemctl daemon-reload
systemctl enable ollama
systemctl start ollama
systemctl status ollama
systemctl stop ollama
systemctl restart ollama
ollama ls
exec /bin/bashc.启动egpu容器
docker run -it --rm -e EGPU="POLICY=000,ONLINE=0,TYPE=DOCKER:PGPU=0,MEM=5120,WEIGHT=30"\
--ipc=host \
--ulimit memlock=-1 \
--ulimit stack=67108864 \
--env NVIDIA_VISIBLE_DEVICES=0 \
--runtime=nvidia \
-v /usr/bin/ollama:/usr/bin/ollama \
-v /usr/lib/ollama:/usr/lib/ollama \
-v /home/egpu-deepseek/models:/home/models \
-v /home/egpu-deepseek/setup.sh:/home/setup.sh \
-v /home/egpu-deepseek/ollama.service:/etc/systemd/system/ollama.service \
<image> \
/bin/bash /home/setup.sh关键参数说明:
PGPU=0,MEM=3276,WEIGHT=30是指在物理GPU(编号为0)上,分配给eGPU容器的显存为3.2G,算力为30%;--env NVIDIA_VISIBLE_DEVICES=0表示容器中能够访问宿主机的第一个 NVIDIA GPU(编号为0);--runtime=nvidia指定 Docker 使用 NVIDIA 的容器运行时(runtime)来运行容器;-v用于将宿主机目录或文件挂载到容器内。包括ollama的相关文件,ollama的模型等。注意使用正确的挂载路径,保证将相关文件完整地挂载到容器内;<image>为要运行的 Docker 镜像名称,必须替换为具体的镜像名称;/bin/bash /home/setup.sh容器启动后,运行挂载到容器内的setup.sh脚本,以配置ollama服务。
4.单eGPU容器运行deepseek模型
a.根据第3步启动egpu容器,并在容器检查是否正确安装了ollama。
ollama ls


b.运行deepseek模型。
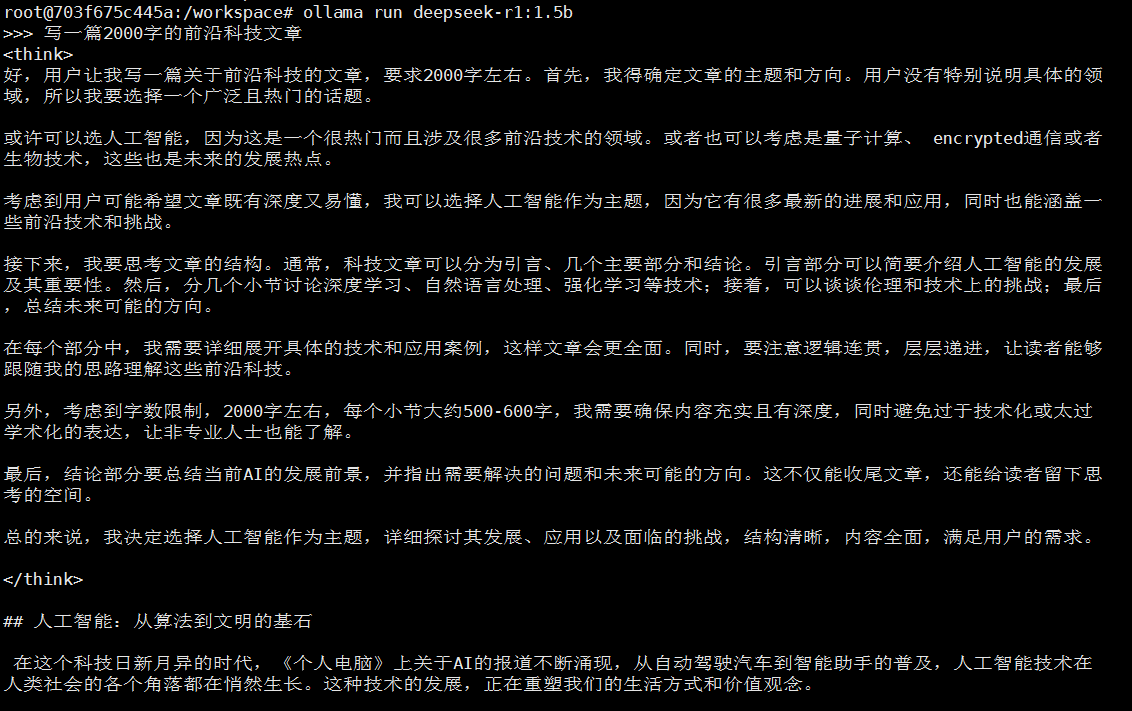
ollama run deepseek-r1:1.5b

![]()
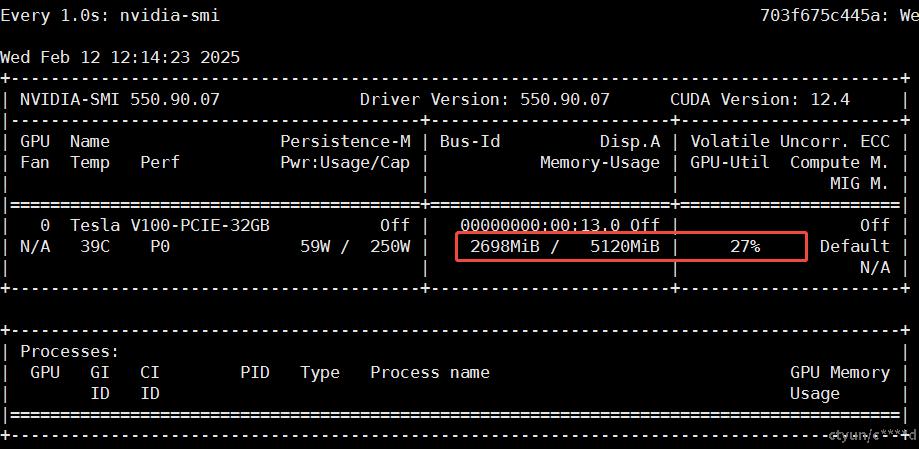
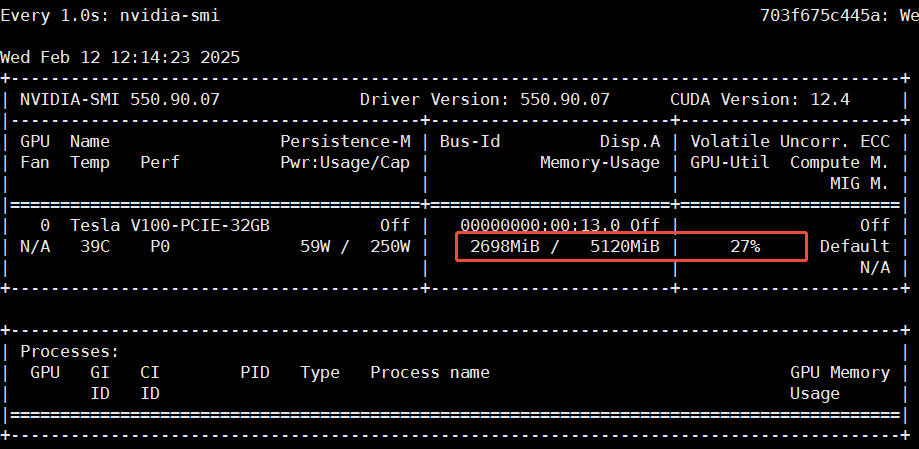
c.根据显存和算力先后启动eGPU容器,发送对话请求,记录模型的运行效果、显存和算力的占用情况。
- deepseek-r1:1.5b (显存5120MiB,算力30%)

- deepseek-r1:7b(显存8192MiB,算力30%)
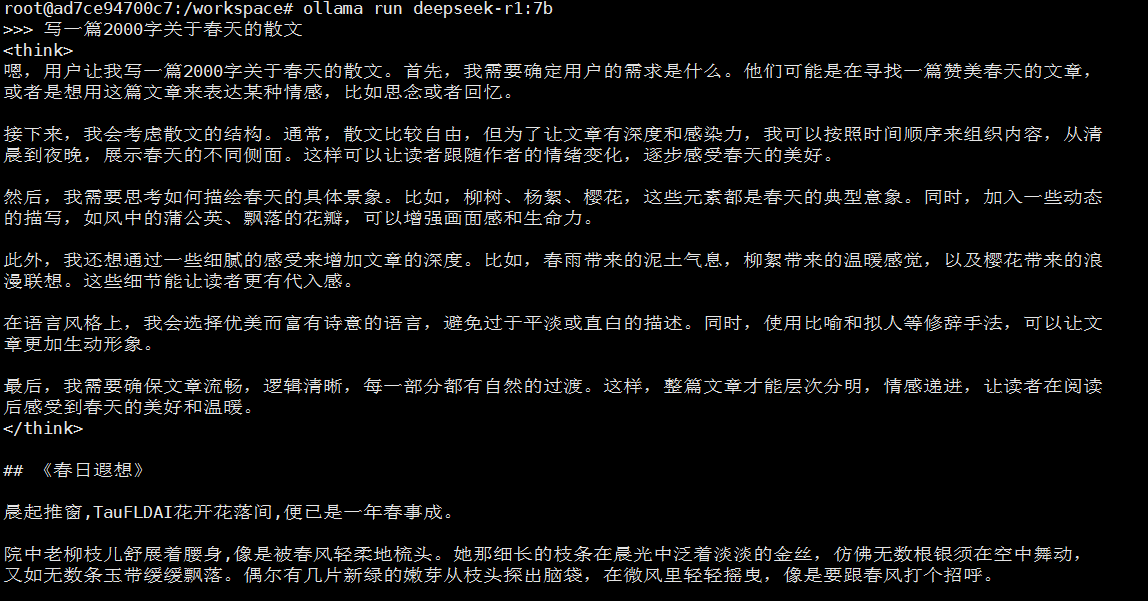

- deepseek-r1:14b(显存16384MiB,算力30%)
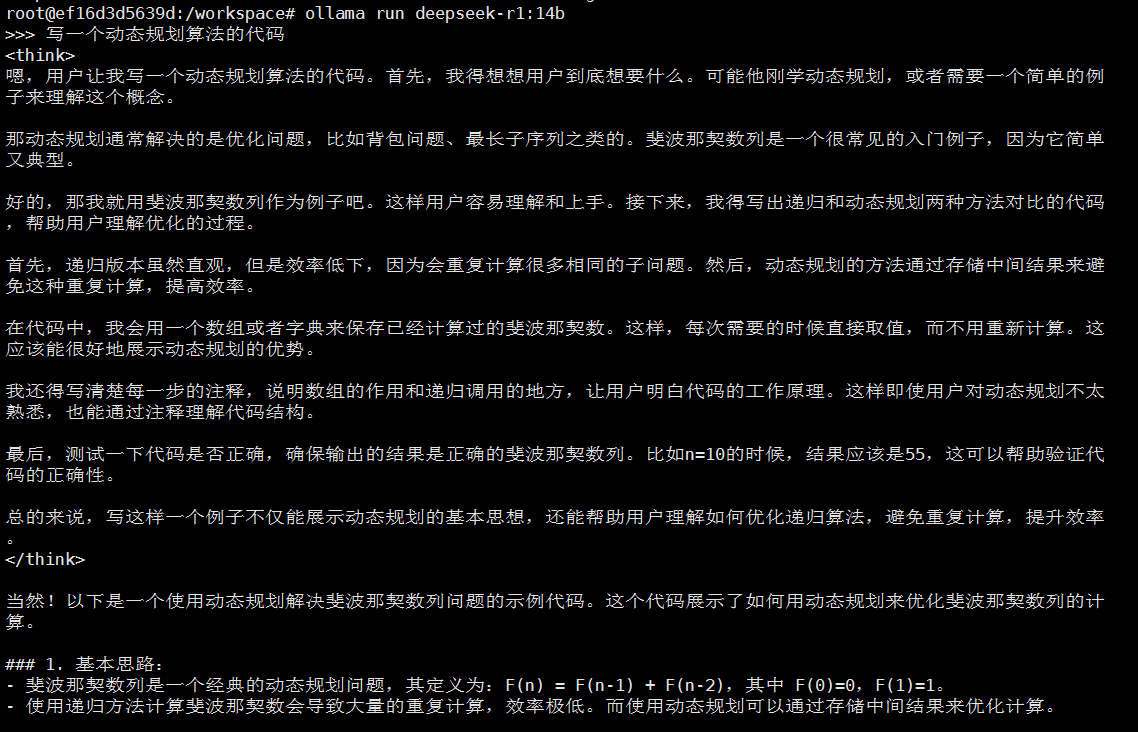
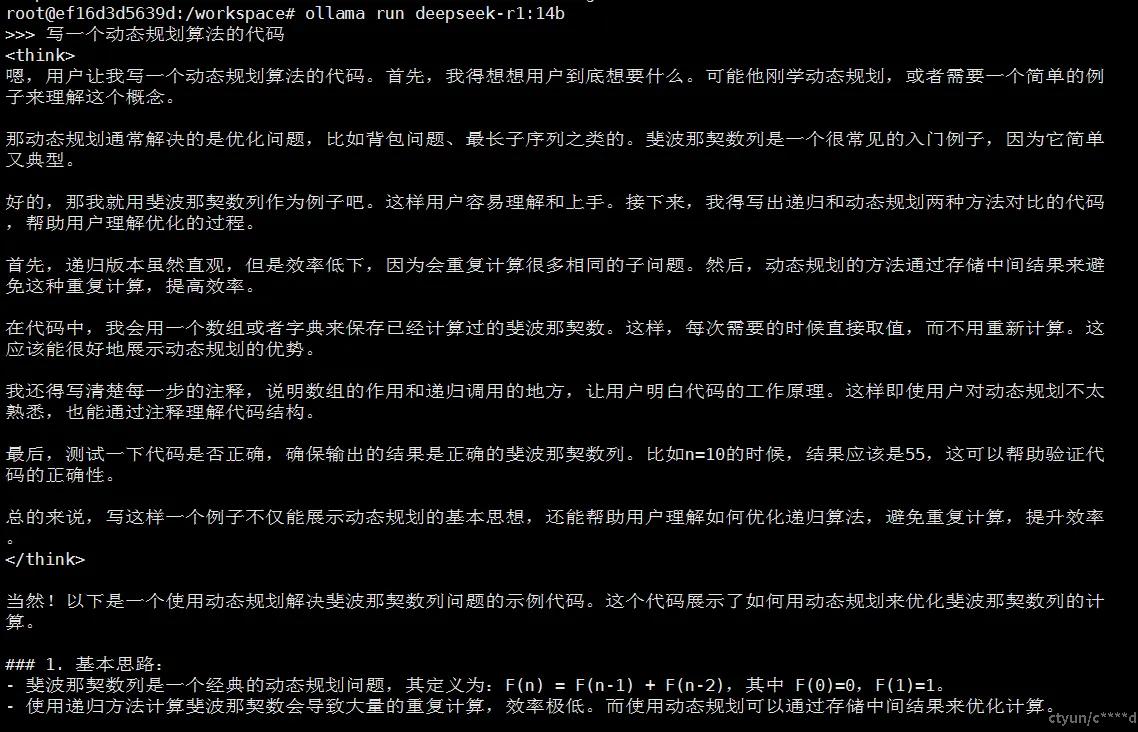
5.多eGPU容器运行deepseek模型
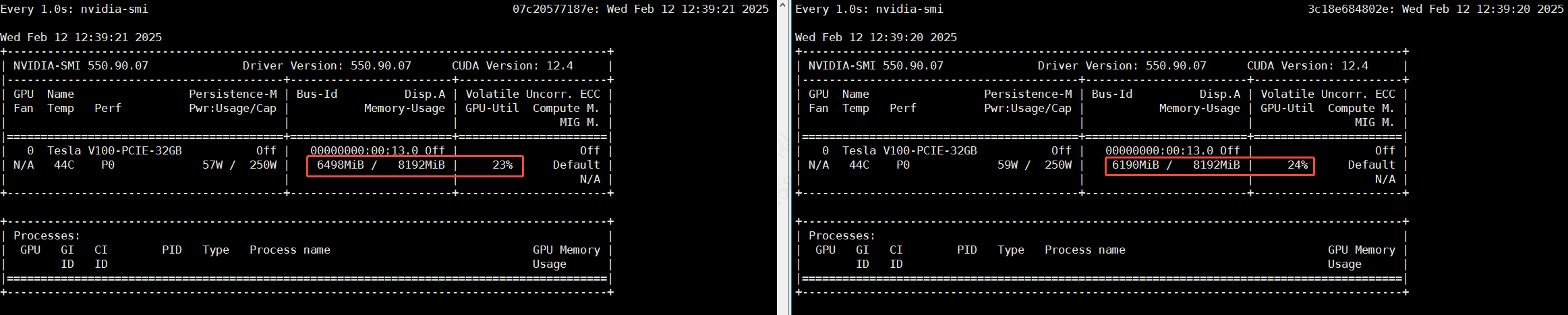
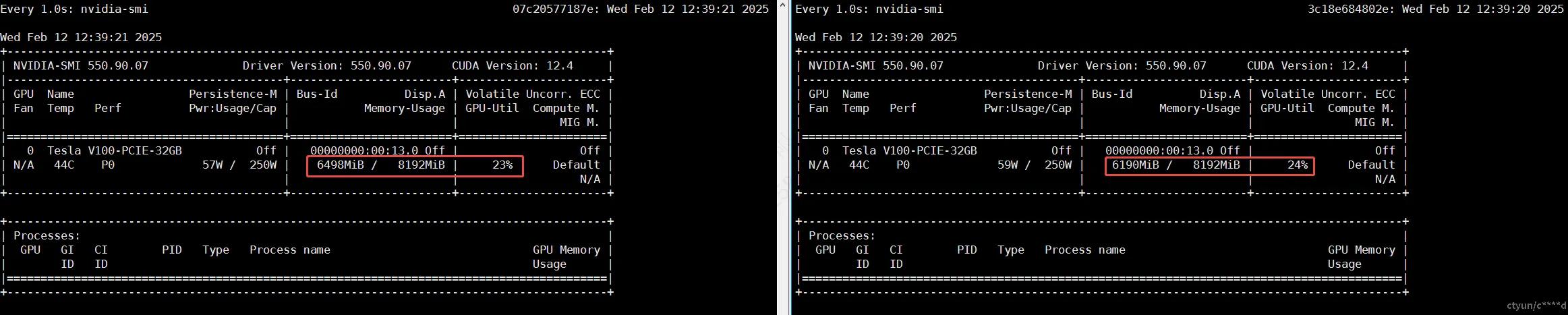
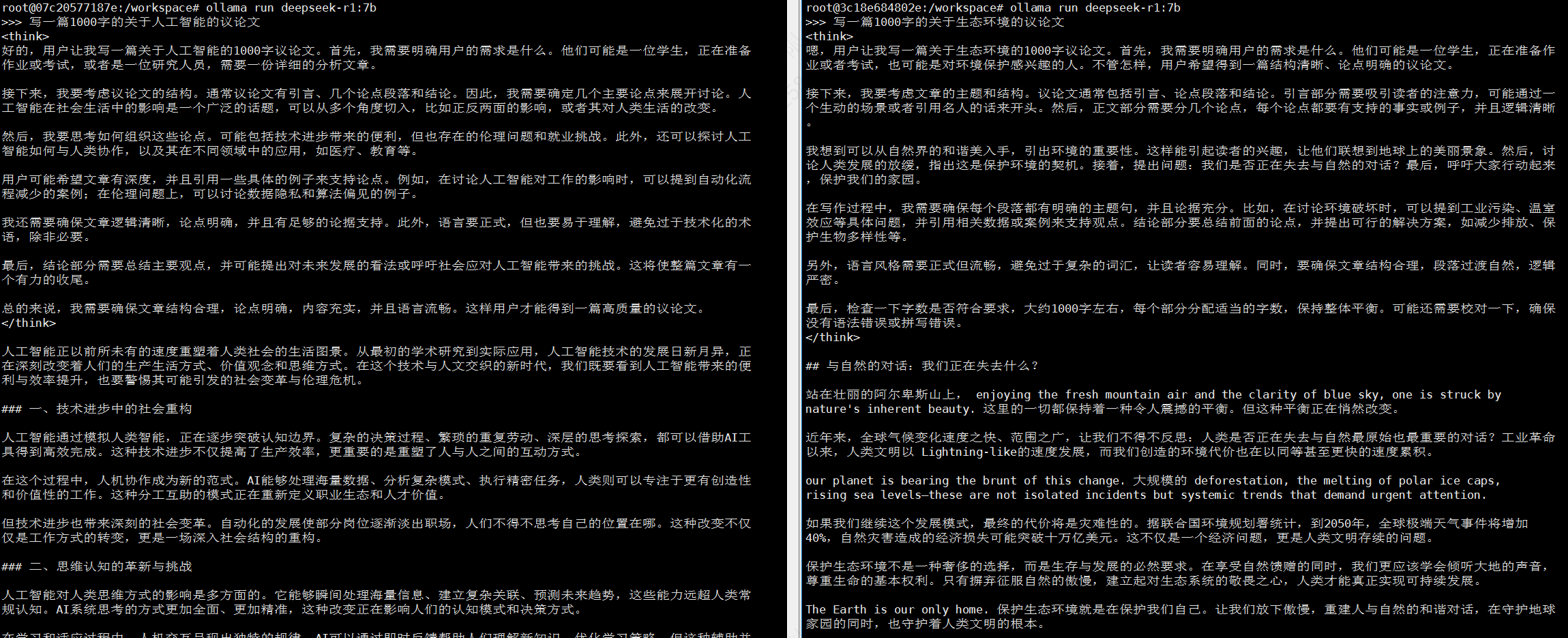
以DeepSeek-R1(7B)模型为例展示多个eGPU同时运行的情况:
- 参数设置:容器A(显存8192MiB,算力30%);容器B(显存8192MiB,算力30%)。
- 两个eGPU容器的的模型运行情况:



- 两个eGPU容器的显存和算力占用情况: