


3. MPI on Volcano
HPC简介
高性能计算(High Performance Computing,缩写HPC)指利用聚集起来的计算能力来处理标准工作站无法完成的数据密集型的计算任务。
HPC = PBS + Maui + OpenMPI
- PBS:资源管理器,负责管理Cluster中所有节点的资源。
- Maui:第三方任务调度器,支持资源预留,支持各种复杂的优先级策略,支持抢占等。
- OpenMPI:上层通信环境,兼顾通信库、编译、分布式启动任务的功能。
openMPI简介
openMPI项目是一个开源消息传递接口实现,由学术,研究和行业合作伙伴联盟开发和维护。通过它我们来进行并行化的程序设计。
opensMPI如何执行
下面是一个简单的4线程mpi程序例子。
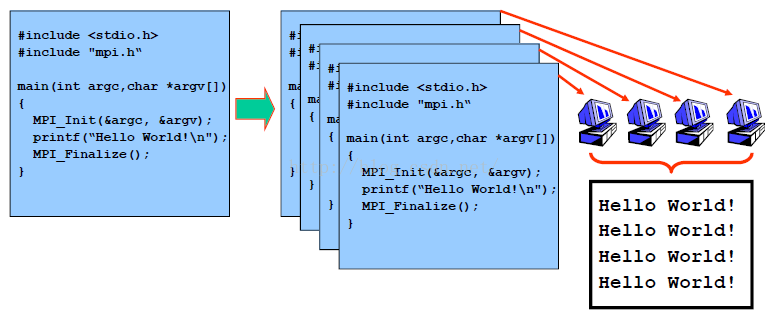
mpi工作原理
MPI on Volcano
(1) 创建mpi-example.yaml
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: lm-mpi-job
spec:
minAvailable: 3
schedulerName: volcano
plugins:
ssh: []
svc: []
tasks:
- replicas: 1
name: mpimaster
policies:
- event: TaskCompleted
action: CompleteJob
template:
spec:
containers:
- command:
- /bin/sh
- -c
- |
MPI_HOST=`cat /etc/volcano/mpiworker.host | tr "\n" ","`;
mkdir -p /var/run/sshd; /usr/sbin/sshd;
mpiexec --allow-run-as-root --host ${MPI_HOST} -np 2 mpi_hello_world > /home/re;
image: volcanosh/example-mpi:0.0.1
name: mpimaster
ports:
- containerPort: 22
name: mpijob-port
workingDir: /home
restartPolicy: OnFailure
- replicas: 2
name: mpiworker
template:
spec:
containers:
- command:
- /bin/sh
- -c
- |
mkdir -p /var/run/sshd; /usr/sbin/sshd -D;
image: volcanosh/example-mpi:0.0.1
name: mpiworker
ports:
- containerPort: 22
name: mpijob-port
workingDir: /home
restartPolicy: OnFailure
---(2) 部署mpi-example.yaml
$ kubectl apply -f mpi-example.yaml(3) 查看作业执行情况
$ kubectl get pod4. TensorFlow on Volcano
TensorFlow简介
TensorFlow是一个基于数据流编程的符号数学系统,被广泛应用于各类机器学习算法的编程实现,其前身是谷歌的神经网络算法库DistBelief。
TensorFlow on Volcano
PS-worker模型:Parameter Server执行模型相关业务,Work Server训练相关业务,推理计算、梯度计算等[1]。
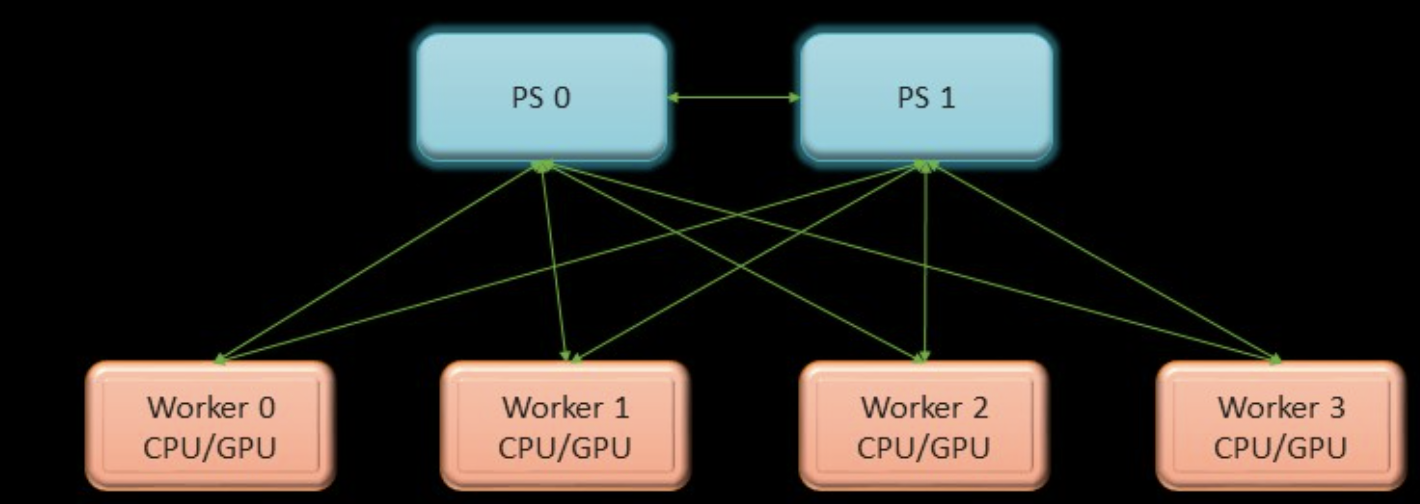
ps-worker
TensorFlow on Kubernates存在诸多的问题
- 资源隔离
- 缺乏GPU调度、Gang schduler。
- 进程遗留问题
- 训练日志保存不方便
(1) 创建tftest.yaml
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: tensorflow-dist-mnist
spec:
minAvailable: 3
schedulerName: volcano
plugins:
env: []
svc: []
policies:
- event: PodEvicted
action: RestartJob
queue: default
tasks:
- replicas: 1
name: ps
template:
spec:
containers:
- command:
- sh
- -c
- |
PS_HOST=`cat /etc/volcano/ps.host | sed 's/$/&:2222/g' | sed 's/^/"/;s/$/"/' | tr "\n" ","`;
WORKER_HOST=`cat /etc/volcano/worker.host | sed 's/$/&:2222/g' | sed 's/^/"/;s/$/"/' | tr "\n" ","`;
export TF_CONFIG={\"cluster\":{\"ps\":[${PS_HOST}],\"worker\":[${WORKER_HOST}]},\"task\":{\"type\":\"ps\",\"index\":${VK_TASK_INDEX}},\"environment\":\"cloud\"};
python /var/tf_dist_mnist/dist_mnist.py
image: volcanosh/dist-mnist-tf-example:0.0.1
name: tensorflow
ports:
- containerPort: 2222
name: tfjob-port
resources: {}
restartPolicy: Never
- replicas: 2
name: worker
policies:
- event: TaskCompleted
action: CompleteJob
template:
spec:
containers:
- command:
- sh
- -c
- |
PS_HOST=`cat /etc/volcano/ps.host | sed 's/$/&:2222/g' | sed 's/^/"/;s/$/"/' | tr "\n" ","`;
WORKER_HOST=`cat /etc/volcano/worker.host | sed 's/$/&:2222/g' | sed 's/^/"/;s/$/"/' | tr "\n" ","`;
export TF_CONFIG={\"cluster\":{\"ps\":[${PS_HOST}],\"worker\":[${WORKER_HOST}]},\"task\":{\"type\":\"worker\",\"index\":${VK_TASK_INDEX}},\"environment\":\"cloud\"};
python /var/tf_dist_mnist/dist_mnist.py
image: volcanosh/dist-mnist-tf-example:0.0.1
name: tensorflow
ports:
- containerPort: 2222
name: tfjob-port
resources: {}
restartPolicy: Never(2) 部署tftest.yaml
$ kubectl apply -f tftest.yaml(3) 查看作业运行情况
$ kubectl get pod
5. Spark on Volcano
Spark简介
Spark是一款快速通用的大数据Cluster计算系统。它提供了Scala、Java、Python和R的高级api,以及一个支持用于数据分析的通用计算图的优化引擎。它还支持一组丰富的高级工具,包括用于SQL和DataFrames的Spark SQL、用于机器学习的MLlib、用于图形处理的GraphX和用于流处理的Spark Streaming。
Spark on Volcano
当前,有两种方式可以支持Spark和Volcano集成: - Spark on Kubernetes native支持: 由Apache Spark社区和Volcano社区共同维护。 - Spark Operator支持: 由GoogleCloudPlatform community和Volcano社区共同维护。
Spark on Kubernetes native支持 (spark-submit)
从Apache Spark v3.3.0版本及Volcano v1.5.1版本开始,Spark支持Volcano作为自定义调度。Spark on Kubernetes 允许使用 Volcano 作为自定义调度程序。 用户可以使用Volcano支持更高级的资源调度:队列调度、资源预留、优先级调度等等。
要将 Volcano 用作自定义调度程序,用户需要指定以下配置选项:
# Specify volcano scheduler and PodGroup template
--conf spark.kubernetes.scheduler.name=volcano
--conf spark.kubernetes.scheduler.volcano.podGroupTemplateFile=/path/to/podgroup-template.yaml
# Specify driver/executor VolcanoFeatureStep
--conf spark.kubernetes.driver.pod.featureSteps=org.apache.spark.deploy.k8s.features.VolcanoFeatureStep
--conf spark.kubernetes.executor.pod.featureSteps=org.apache.spark.deploy.k8s.features.VolcanoFeatureStepSpark Operator支持 (spark-operator)
(1) 通过helm安装spark-operator。
$ helm repo add spark-operator <address pointing to spark operator repo>
$ helm install my-release spark-operator/spark-operator --namespace spark-operator --create-namespace(2) 为确保spark-operator已经正常运行,通过如下指令查看。
$ kubectl get po -nspark-operator(3) 这里是用官方提供的spark-pi.yaml.
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: spark-pi
namespace: default
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v3.0.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.12-3.0.0.jar"
sparkVersion: "3.0.0"
batchScheduler: "volcano" #Note: the batch scheduler name must be specified with `volcano`
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 1
coreLimit: "1200m"
memory: "512m"
labels:
version: 3.0.0
serviceAccount: spark
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 3.0.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"(4) 部署spark应用并查看状态。
$ kubectl apply -f spark-pi.yaml
$ kubectl get SparkApplication