


1. Flink on Volcano
Flink简介
Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。此外,Flink的运行时本身也支持迭代算法的执行。
前提条件
需要已经部署创建好CCE集群,集群下至少有一个可用节点,集群内节点已经绑定了弹性公网IP、kubectl命令行工具。
部署流程
(1) Download
为了运行Flink,需要java8或11的环境,使用如下的指令确定java的版本。
$ java version下载软件包flink-1.12.2-src.tgz,解压并且进入目录下。
$ cd flink-1.12.2(2) Start a Cluster
运行脚本完成flink在集群上的部署。
$ ./bin/start-cluster.sh(3) Submit a job
随后可以使用如下的指令提交作业。
$ ./bin/flink run examples/streaming/WordCount.jar
$ tail log/flink-*-taskexecutor-*.outFlink on Volcano
(1) 部署组件
Flink cluster的部署需要创建两个deploy、一个service和一个configmap。调度策略采用volcano。flink-configuration-configmap.yaml内容如下
apiVersion: v1
kind: ConfigMap
metadata:
name: flink-config
labels:
app: flink
data:
flink-conf.yaml: |+
jobmanager.rpc.address: flink-jobmanager
taskmanager.numberOfTaskSlots: 2
blob.server.port: 6124
jobmanager.rpc.port: 6123
taskmanager.rpc.port: 6122
queryable-state.proxy.ports: 6125
jobmanager.memory.process.size: 1600m
taskmanager.memory.process.size: 1728m
parallelism.default: 2
log4j-console.properties: |+
# This affects logging for both user code and Flink
rootLogger.level = INFO
rootLogger.appenderRef.console.ref = ConsoleAppender
rootLogger.appenderRef.rolling.ref = RollingFileAppender
# Uncomment this if you want to _only_ change Flink's logging
#logger.flink.name = org.apache.flink
#logger.flink.level = INFO
# The following lines keep the log level of common libraries/connectors on
# log level INFO. The root logger does not override this. You have to manually
# change the log levels here.
logger.akka.name = akka
logger.akka.level = INFO
logger.kafka.name= org.apache.kafka
logger.kafka.level = INFO
logger.hadoop.name = org.apache.hadoop
logger.hadoop.level = INFO
logger.zookeeper.name = org.apache.zookeeper
logger.zookeeper.level = INFO
# Log all infos to the console
appender.console.name = ConsoleAppender
appender.console.type = CONSOLE
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
# Log all infos in the given rolling file
appender.rolling.name = RollingFileAppender
appender.rolling.type = RollingFile
appender.rolling.append = false
appender.rolling.fileName = ${sys:log.file}
appender.rolling.filePattern = ${sys:log.file}.%i
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
appender.rolling.policies.type = Policies
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling.policies.size.size=100MB
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.max = 10
# Suppress the irrelevant (wrong) warnings from the Netty channel handler
logger.netty.name = org.apache.flink.shaded.akka.org.jboss.netty.channel.DefaultChannelPipeline
logger.netty.level = OFFservice用来提供JobManager的REST和UI端口的服务,jobmanager-service.yaml内容如下
apiVersion: v1
kind: Service
metadata:
name: flink-jobmanager
spec:
type: ClusterIP
ports:
- name: rpc
port: 6123
- name: blob-server
port: 6124
- name: webui
port: 8081
selector:
app: flink
component: jobmanagerjobmanager-session-deployment.yaml内容如下
apiVersion: apps/v1
kind: Deployment
metadata:
name: flink-jobmanager
spec:
replicas: 1
selector:
matchLabels:
app: flink
component: jobmanager
template:
metadata:
labels:
app: flink
component: jobmanager
spec:
containers:
- name: jobmanager
image: flink:1.11.0-scala_2.11
args: ["jobmanager"]
ports:
- containerPort: 6123
name: rpc
- containerPort: 6124
name: blob-server
- containerPort: 8081
name: webui
livenessProbe:
tcpSocket:
port: 6123
initialDelaySeconds: 30
periodSeconds: 60
volumeMounts:
- name: flink-config-volume
mountPath: /opt/flink/conf
securityContext:
runAsUser: 9999 # refers to user _flink_ from official flink image, change if necessary
volumes:
- name: flink-config-volume
configMap:
name: flink-config
items:
- key: flink-conf.yaml
path: flink-conf.yaml
- key: log4j-console.properties
path: log4j-console.propertiestaskmanager-session-deployment.yaml内容如下
apiVersion: apps/v1
kind: Deployment
metadata:
name: flink-taskmanager
spec:
replicas: 2
selector:
matchLabels:
app: flink
component: taskmanager
template:
metadata:
labels:
app: flink
component: taskmanager
spec:
containers:
- name: taskmanager
image: flink:1.11.0-scala_2.11
args: ["taskmanager"]
ports:
- containerPort: 6122
name: rpc
- containerPort: 6125
name: query-state
livenessProbe:
tcpSocket:
port: 6122
initialDelaySeconds: 30
periodSeconds: 60
volumeMounts:
- name: flink-config-volume
mountPath: /opt/flink/conf/
securityContext:
runAsUser: 9999 # refers to user _flink_ from official flink image, change if necessary
volumes:
- name: flink-config-volume
configMap:
name: flink-config
items:
- key: flink-conf.yaml
path: flink-conf.yaml
- key: log4j-console.properties
path: log4j-console.properties在集群节点创建好上面四个yaml配置文件,使用如下指令进行部署。
$ kubectl create -f flink-configuration-configmap.yaml
$ kubectl create -f jobmanager-service.yaml
$ kubectl create -f jobmanager-session-deployment.yaml
$ kubectl create -f taskmanager-session-deployment.yaml创建成功后查询:
$ kubectl get cm| grep flink
$ kubectl get svc | grep flink
$ kubectl get pod -owide | grep Flink2. Kubeflow on Volcano
Kubeflow简介
Kubernetes已经成为云原生应用编排、管理的事实标准, 越来越多的应用选择向Kubernetes迁移。人工智能和机器学习领域天然的包含大量的计算密集型任务,开发者非常愿意基于Kubernetes构建AI平台,充分利用Kubernetes提供的资源管理、应用编排、运维监控能力。然而基于Kubernetes构建一个端到端的AI计算平台是非常复杂和繁琐的过程,它需要处理很多个环节。除了我们熟知的模型训练环节之外还包括数据收集、预处理、资源管理、特性提取、数据验证、模型的管理、模型发布、监控等环节。对于一个AI算法工程师来讲,他要做模型训练,就不得不搭建一套AI计算平台,这个过程耗时费力,而且需要很多的知识积累[1]。
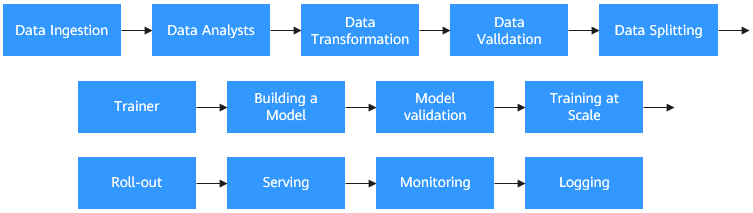
模型训练工作流
Kubeflow诞生于2017年,Kubeflow项目是基于容器和Kubernetes构建,旨在为数据科学家、机器学习工程师、系统运维人员提供面向机器学习业务的敏捷部署、开发、训练、发布和管理平台。它利用了云原生技术的优势,让用户更快速、方便的部署、使用和管理当前最流行的机器学习软件。
什么场景我们可以使用kubeflow:
- 希望训练tensorflow模型且可以使用模型接口发布应用服务在k8s环境中(eg.local,prem,cloud)
- 希望使用Jupyter notebooks来调试代码,多用户的notebook server
- 在训练的Job中,需要对的CPU或者GPU资源进行调度编排
- 希望Tensorflow和其他组件进行组合来发布服务
Kubeflow on volcano
Volcano是一款构建于Kubernetes之上的增强型高性能计算任务批量处理系统。作为一个面向高性能计算场景的平台,它弥补了kubernetes在机器学习、深度学习、HPC、大数据计算等场景下的基本能力缺失,其中包括gang-schedule的调度能力、计算任务队列管理、task-topology和GPU亲和性调度。另外,Volcano在原生kubernetes能力基础上对计算任务的批量创建及生命周期管理、fair-share、binpack调度等方面做了增强。Volcano充分解决了上文提到的Kubeflow分布式训练面临的问题。
下载kfctl
首先需要下载kfctl,可以根据系统来选择合适的压缩包文件。
$ tar -xvf kfctl_v1.0.2-0-ga476281_linux.tar.gz
$ sudo mv ./kfctl /usr/local/bin/kfctl配置环境变量
$ export PATH= $PATH:"<path-to-kfctl>"
$ export KF_NAME=<your choice of name for the Kubeflow deployment>
$ export BASE_DIR=<path to a base directory>
$ export KF_DIR=${BASE_DIR}/${KF_NAME}
$ export CONFIG_URI="url pointing to kfctl_k8s_istio.v1.0.2.yaml"安装kubeflow
$ mkdir -p ${KF_DIR}
$ cd ${KF_DIR}
$ Kfctl apply -V -f ${CONFIG_URI}通过如下指令确认安装结果
$ kubectl -n kubeflow get all 部署Mnist示例
首先下载kubuflow官方提供的测试集。
$ git clone <url pointing to kubeflow examples>$ pip3 install jupyter notebook
$ jupyter notebook --allow-root ##启动jupyter启动使用notebook
提供对外接口服务,这里需要将集群下的节点绑定公网IP。如果没有安装notebook请先使用pip3安装。
$ pip3 install jupyter notebook
$ jupyter notebook --allow-root访问公网IP:30200,输入配置密码即可进入notebook。
在notebook上运行官方实例
(1) 打开notebook进行TFJob的部署。Open the notebook mnist/mnist_vanilla_k8s.ipynb ,根据指引来进行分布式Tf Job的部署。
(2) 添加调度器字段:在mnist/mnist_vanilla_k8s.ipynb 的Tarining job parameters代码块下的TFJob的配置如下所示,添加schedulerName: volcano字段,确保使用volcano进行调度。
train_spec = f"""apiVersion: kubeflow.org/v1
kind: TFJob
metadata:
name: {train_name}
spec:
schedulerName: volcano
tfReplicaSpecs:
Ps:
replicas: {num_ps}
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
spec:
serviceAccount: default-editor
containers:
- name: tensorflow
command:
- python
- /opt/model.py
- --tf-model-dir={model_dir}
- --tf-export-dir={export_path}
- --tf-train-steps={train_steps}
- --tf-batch-size={batch_size}
- --tf-learning-rate={learning_rate}
env:
- name: S3_ENDPOINT
value: {s3_endpoint}
- name: AWS_ENDPOINT_URL
value: {minio_endpoint}
- name: AWS_REGION
value: {minio_region}
- name: BUCKET_NAME
value: {mnist_bucket}
- name: S3_USE_HTTPS
value: "0"
- name: S3_VERIFY_SSL
value: "0"
- name: AWS_ACCESS_KEY_ID
value: {minio_username}
- name: AWS_SECRET_ACCESS_KEY
value: {minio_key}
image: {image}
workingDir: /opt
restartPolicy: OnFailure
Chief:
replicas: 1
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
spec:
serviceAccount: default-editor
containers:
- name: tensorflow
command:
- python
- /opt/model.py
- --tf-model-dir={model_dir}
- --tf-export-dir={export_path}
- --tf-train-steps={train_steps}
- --tf-batch-size={batch_size}
- --tf-learning-rate={learning_rate}
env:
- name: S3_ENDPOINT
value: {s3_endpoint}
- name: AWS_ENDPOINT_URL
value: {minio_endpoint}
- name: AWS_REGION
value: {minio_region}
- name: BUCKET_NAME
value: {mnist_bucket}
- name: S3_USE_HTTPS
value: "0"
- name: S3_VERIFY_SSL
value: "0"
- name: AWS_ACCESS_KEY_ID
value: {minio_username}
- name: AWS_SECRET_ACCESS_KEY
value: {minio_key}
image: {image}
workingDir: /opt
restartPolicy: OnFailure
Worker:
replicas: 1
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
spec:
serviceAccount: default-editor
containers:
- name: tensorflow
command:
- python
- /opt/model.py
- --tf-model-dir={model_dir}
- --tf-export-dir={export_path}
- --tf-train-steps={train_steps}
- --tf-batch-size={batch_size}
- --tf-learning-rate={learning_rate}
env:
- name: S3_ENDPOINT
value: {s3_endpoint}
- name: AWS_ENDPOINT_URL
value: {minio_endpoint}
- name: AWS_REGION
value: {minio_region}
- name: BUCKET_NAME
value: {mnist_bucket}
- name: S3_USE_HTTPS
value: "0"
- name: S3_VERIFY_SSL
value: "0"
- name: AWS_ACCESS_KEY_ID
value: {minio_username}
- name: AWS_SECRET_ACCESS_KEY
value: {minio_key}
image: {image}
workingDir: /opt
restartPolicy: OnFailure
"""(3) 提交作业
$ kubectl apply -f mnist.yaml