


Queue
定义
queue是容纳一组podgroup的队列,也是该组podgroup获取集群资源的划分依据
样例
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
creationTimestamp: "2020-08-10T11:54:36Z"
generation: 1
name: default
resourceVersion: "559"
selfLink: /apis/scheduling.volcano.sh/v1beta1/queues/default
uid: 14082e4c-bef6-4248-a414-1e06d8352bf0
spec:
reclaimable: true
weight: 1
capability:
cpu: "4"
memory: "4096Mi"
status:
state: Open
关键字段
- weight
weight表示该queue在集群资源划分中所占的相对比重,该queue应得资源总量为 (weight/total-weight) * total-resource。其中, total-weight表示所有的queue的weight总和,total-resource表示集群的资源总量。weight是一个软约束,取值范围为[1, 2^31-1]
- capability
capability表示该queue内所有podgroup使用资源量之和的上限,它是一个硬约束
- reclaimable
reclaimable表示该queue在资源使用量超过该queue所应得的资源份额时,是否允许其他queue回收该queue使用超额的资源,默认值为true
资源状态
- Open
该queue当前处于可用状态,可接收新的podgroup
- Closed
该queue当前处于不可用状态,不可接收新的podgroup
- Closing
该Queue正在转化为不可用状态,不可接收新的podgroup
- Unknown
该queue当前处于不可知状态,可能是网络或其他原因导致queue的状态暂时无法感知
使用场景
weight的资源划分-1
背景:
- 集群CPU总量为4C
- 已默认创建名为default的queue,weight为1
- 集群中无任务运行
操作:
- 当前情况下,default queue可是使用全部集群资源,即4C
- 创建名为test的queue,weight为3。此时,default weight:test weight = 1:3,即default queue可使用1C,test queue可使用3C
- 创建名为p1和p2的podgroup,分别属于default queue和test queue
- 分别向p1和p2中投递job1和job2,资源申请量分别为1C和3C,2个job均能正常工作
weight的资源划分-2
背景:
- 集群CPU总量为4C
- 已默认创建名为default的queue,weight为1
- 集群中无任务运行
操作:
- 当前情况下,default queue可是使用全部集群资源,即4C
- 创建名为p1的podgroup,属于default queue。
- 分别创建名为job1和job2的job,属于p1,资源申请量分别为1C和3C,job1和job2均能正常工作
- 创建名为test的queue,weight为3。此时,default weight:test weight = 1:3,即default queue可使用1C,test queue可使用3C。但由于test queue内此时无任务,job1和job2仍可正常工作
- 创建名为p2的podgroup,属于test queue。
- 创建名为job3的job,属于p2,资源申请量为3C。此时,job2将被驱逐,将资源归还给job3,即default queue将3C资源归还给test queue。
capability的使用
背景:
- 集群CPU总量为4C
- 已默认创建名为default的queue,weight为1
- 集群中无任务运行
操作:
- 创建名为test的queue,capability设置cpu为2C,即test queue使用资源上限为2C
- 创建名为p1的podgroup,属于test queue
- 分别创建名为job1和job2的job,属于p1,资源申请量分别为1C和3C,依次下发。由于capability的限制,job1正常运行,job2处于pending状态
reclaimable的使用
背景:
- 集群CPU总量为4C
- 已默认创建名为default的queue,weight为1
- 集群中无任务运行
操作:
- 创建名为test的queue,reclaimable设置为false,weight为1。此时,default weight:test weight = 1:1,即default queue和test queue均可使用2C。
- 创建名为p1、p2的podgroup,分别属于test queue和default queue
- 创建名为job1的job,属于p1,资源申请量3C,job1可正常运行。此时,由于default queue中尚无任务,test queue多占用1C
- 创建名为job2的job,属于p2,资源申请量2C,任务下发后处于pending状态,即test queue的reclaimable为false导致该queue不归还多占的资源
说明事项
default queue
volcano启动后,会默认创建名为default的queue,weight为1。后续下发的job,若未指定queue,默认属于default queue
weight的软约束
weight的软约束是指weight决定的queue应得资源的份额并不是不能超出使用的。当其他queue的资源未充分利用时,需要超出使用资源的queue可临时多占。但其 他queue后续若有任务下发需要用到这部分资源,将驱逐该queue多占资源的任务以达到weight规定的份额(前提是queue的reclaimable为true)。这种设计可以 保证集群资源的最大化利用。
PodGroup
定义
podgroup是一组强关联pod的集合,主要用于批处理工作负载场景,比如Tensorflow中的一组ps和worker。它是volcano自定义资源类型。
样例
apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
metadata:
creationTimestamp: "2020-08-11T12:28:55Z"
generation: 5
name: test
namespace: default
ownerReferences:
- apiVersion: batch.volcano.sh/v1alpha1
blockOwnerDeletion: true
controller: true
kind: Job
name: test
uid: 028ecfe8-0ff9-477d-836c-ac5676491a38
resourceVersion: "109074"
selfLink: /apis/scheduling.volcano.sh/v1beta1/namespaces/default/podgroups/job-1
uid: eb2508f5-3349-439c-b94d-4ac23afd71ff
spec:
minMember: 1
minResources:
cpu: "3"
memory: "2048Mi"
priorityClassName: high-prority
queue: default
status:
conditions:
- lastTransitionTime: "2020-08-11T12:28:57Z"
message: '1/0 tasks in gang unschedulable: pod group is not ready, 1 minAvailable.'
reason: NotEnoughResources
status: "True"
transitionID: 77d5be3f-6169-4f86-8e65-0bdc621ce983
type: Unschedulable
- lastTransitionTime: "2020-08-11T12:29:02Z"
reason: tasks in gang are ready to be scheduled
status: "True"
transitionID: 54514401-5c90-4b11-840d-90c1cda93096
type: Scheduled
phase: Running
running: 1
关键字段
- minMember
minMember表示该podgroup下最少需要运行的pod或任务数量。如果集群资源不满足miniMember数量任务的运行需求,调度器将不会调度任何一个该podgroup 内的任务。
- queue
queue表示该podgroup所属的queue。queue必须提前已创建且状态为open。
- priorityClassName
priorityClassName表示该podgroup的优先级,用于调度器为该queue中所有podgroup进行调度时进行排序。system-node-critical和system-cluster-critical 是2个预留的值,表示最高优先级。不特别指定时,默认使用default优先级或zero优先级。
- minResources
minResources表示运行该podgroup所需要的最少资源。当集群可分配资源不满足minResources时,调度器将不会调度任何一个该podgroup内的任务。
- phase
phase表示该podgroup当前的状态。
- conditions
conditions表示该podgroup的具体状态日志,包含了podgroup生命周期中的关键事件。
- running
running表示该podgroup中当前处于running状态的pod或任务的数量。
- succeed
succeed表示该podgroup中当前处于succeed状态的pod或任务的数量。
- failed
failed表示该podgroup中当前处于failed状态的pod或任务的数量。
资源状态
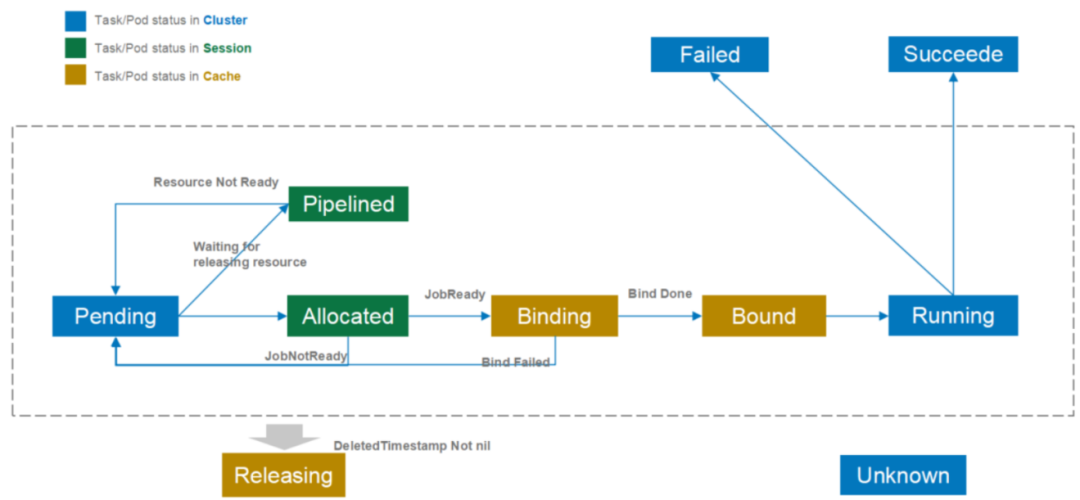
status-DAG
- pending
pending表示该podgroup已经被volcano接纳,但是集群资源暂时不能满足它的需求。一旦资源满足,该podgroup将转变为running状态。
- running
running表示该podgroup至少有minMember个pod或任务处于running状态。
- unknown
unknown表示该podgroup中minMember数量的pod或任务分为2种状态,部分处于running状态,部分没有被调度。没有被调度的原因可能是资源不够等。调度 器将等待controller重新拉起这些pod或任务。
- inqueue
inqueue表示该podgroup已经通过了调度器的校验并入队,即将为它分配资源。inqueue是一种处于pending和running之间的中间状态。
使用场景
- minMember的使用
在某些场景下,可能会只需要某个任务的子任务运行达到一定的数量,即可认为本次任务可以运行,如机器学习训练。这种情况下适合使用minMember字段。
- priorityClassName的使用
priorityClassName用于podgroup的优先级排序,可用于任务抢占调度场景。它本身也是一种资源。
- minResources的使用
在某些场景下,任务的运行必须满足最小资源要求,不满足则不能运行该任务,如某些大数据分析场景。这种情况下适合使用minResources字段。
说明事项
- 自动创建podgroup
当创建vcjob(Volcano Job的简称)时,若没有指定该vcjob所属的podgroup,默认会为该vcjob创建同名的podgroup。
VolcanoJob
定义
Volcano Job,简称vcjob,是Volcano自定义的Job资源类型。区别于Kubernetes Job,vcjob提供了更多高级功能,如可指定调度器、支持最小运行pod数、 支持task、支持生命周期管理、支持指定队列、支持优先级调度等。Volcano Job更加适用于机器学习、大数据、科学计算等高性能计算场景。
样例
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: test-job
spec:
minAvailable: 3
schedulerName: volcano
priorityClassName: high-priority
policies:
- event: PodEvicted
action: RestartJob
plugins:
ssh: []
env: []
svc: []
maxRetry: 5
queue: default
volumes:
- mountPath: "/myinput"
- mountPath: "/myoutput"
volumeClaimName: "testvolumeclaimname"
volumeClaim:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 1Gi
tasks:
- replicas: 6
name: "default-nginx"
template:
metadata:
name: web
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx
resources:
requests:
cpu: "1"
restartPolicy: OnFailure
关键字段
- schedulerName
schedulerName表示该job的pod所使用的调度器,默认值为volcano,也可指定为default-scheduler。它也是tasks.template.spec.schedulerName的默认值。
- minAvailable
minAvailable表示运行该job所要运行的最少pod数量。只有当job中处于running状态的pod数量不小于minAvailable时,才认为该job运行正常。
- volumes
volumes表示该job的挂卷配置。volumes配置遵从kubernetes volumes配置要求。
- tasks.replicas
tasks.replicas表示某个task pod的副本数。
- tasks.template
tasks.template表示某个task pod的具体配置定义。
- tasks.policies
tasks.policies表示某个task的生命周期策略。
- policies
policies表示job中所有task的默认生命周期策略,在tasks.policies不配置时使用该策略。
- plugins
plugins表示该job在调度过程中使用的插件。
- queue
queue表示该job所属的队列。
- priorityClassName
priorityClassName表示该job优先级,在抢占调度和优先级排序中生效。
- maxRetry
maxRetry表示当该job可以进行的最大重启次数。
资源状态
- pending
pending表示job还在等待调度中,处于排队的状态。
- aborting
aborting表示job因为某种外界原因正处于中止状态,即将进入aborted状态。
- aborted
aborted表示job因为某种外界原因已处于中止状态。
- running
running表示job中至少有minAvailable个pod正在运行状态。
- restarting
restarting表示job正处于重启状态,正在中止当前的job实例并重新创建新的实例。
- completing
completing表示job中至少有minAvailable个数的task已经完成,该job正在进行最后的清理工作。
- completed
completing表示job中至少有minAvailable个数的task已经完成,该job已经完成了最后的清理工作。
- terminating
terminating表示job因为某种内部原因正处于终止状态,正在等到pod或task释放资源。
- terminated
terminated表示job因为某种内部原因已经处于终止状态,job没有达到预期就结束了。
- failed
failed表示job经过了maxRetry次重启,依然没有正常启动。
使用场景
- TensorFlow workload
以tensorflow为例,创建一个具有1个ps和2个worker的工作负载。
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: tensorflow-dist-mnist
spec:
minAvailable: 3 // 该job的3个pod必须都可用
schedulerName: volcano // 指定volcano为调度器
plugins:
env: []
svc: []
policies:
- event: PodEvicted // 当pod被驱逐时,重启该job
action: RestartJob
tasks:
- replicas: 1 // 指定1个ps pod
name: ps
template: // ps pod的具体定义
spec:
containers:
- command:
- sh
- -c
- |
PS_HOST=`cat /etc/volcano/ps.host | sed 's/$/&:2222/g' | sed 's/^/"/;s/$/"/' | tr "\n" ","`;
WORKER_HOST=`cat /etc/volcano/worker.host | sed 's/$/&:2222/g' | sed 's/^/"/;s/$/"/' | tr "\n" ","`;
export TF_CONFIG={\"cluster\":{\"ps\":[${PS_HOST}],\"worker\":[${WORKER_HOST}]},\"task\":{\"type\":\"ps\",\"index\":${VK_TASK_INDEX}},\"environment\":\"cloud\"};
python /var/tf_dist_mnist/dist_mnist.py
image: volcanosh/dist-mnist-tf-example:0.0.1
name: tensorflow
ports:
- containerPort: 2222
name: tfjob-port
resources: {}
restartPolicy: Never
- replicas: 2 // 指定2个worker pod
name: worker
policies:
- event: TaskCompleted // 2个worker完成任务时认为该job完成任务
action: CompleteJob
template: // worker pod的具体定义
spec:
containers:
- command:
- sh
- -c
- |
PS_HOST=`cat /etc/volcano/ps.host | sed 's/$/&:2222/g' | sed 's/^/"/;s/$/"/' | tr "\n" ","`;
WORKER_HOST=`cat /etc/volcano/worker.host | sed 's/$/&:2222/g' | sed 's/^/"/;s/$/"/' | tr "\n" ","`;
export TF_CONFIG={\"cluster\":{\"ps\":[${PS_HOST}],\"worker\":[${WORKER_HOST}]},\"task\":{\"type\":\"worker\",\"index\":${VK_TASK_INDEX}},\"environment\":\"cloud\"};
python /var/tf_dist_mnist/dist_mnist.py
image: volcanosh/dist-mnist-tf-example:0.0.1
name: tensorflow
ports:
- containerPort: 2222
name: tfjob-port
resources: {}
restartPolicy: Never- argo workload
以argo为例,创建一个具有2个pod副本的工作负载,要求1个可用即可。
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: volcano-step-job-
spec:
entrypoint: volcano-step-job
serviceAccountName: argo
templates:
- name: volcano-step-job
steps:
- - name: hello-1
template: hello-tmpl
arguments:
parameters: [{name: message, value: hello1}, {name: task, value: hello1}]
- - name: hello-2a
template: hello-tmpl
arguments:
parameters: [{name: message, value: hello2a}, {name: task, value: hello2a}]
- name: hello-2b
template: hello-tmpl
arguments:
parameters: [{name: message, value: hello2b}, {name: task, value: hello2b}]
- name: hello-tmpl
inputs:
parameters:
- name: message
- name: task
resource:
action: create
successCondition: status.state.phase = Completed
failureCondition: status.state.phase = Failed
manifest: | // Volcano Job的具体定义
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
generateName: step-job-{{inputs.parameters.task}}-
ownerReferences:
- apiVersion: argoproj.io/v1alpha1
blockOwnerDeletion: true
kind: Workflow
name: "{{workflow.name}}"
uid: "{{workflow.uid}}"
spec:
minAvailable: 1
schedulerName: volcano
policies:
- event: PodEvicted
action: RestartJob
plugins:
ssh: []
env: []
svc: []
maxRetry: 1
queue: default
tasks:
- replicas: 2
name: "default-hello"
template:
metadata:
name: helloworld
spec:
containers:
- image: docker/whalesay
imagePullPolicy: IfNotPresent
command: [cowsay]
args: ["{{inputs.parameters.message}}"]
name: hello
resources:
requests:
cpu: "100m"
restartPolicy: OnFailure- MindSpore
以MindSpore为例,创建一个具有8个pod副本的工作负载,要求1个可用即可。
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: mindspore-cpu
spec:
minAvailable: 1
schedulerName: volcano
policies:
- event: PodEvicted
action: RestartJob
plugins:
ssh: []
env: []
svc: []
maxRetry: 5
queue: default
tasks:
- replicas: 8
name: "pod"
template:
spec:
containers:
- command: ["/bin/bash", "-c", "python /tmp/lenet.py"]
image: lyd911/mindspore-cpu-example:0.2.0
imagePullPolicy: IfNotPresent
name: mindspore-cpu-job
resources:
limits:
cpu: "1"
requests:
cpu: "1"
restartPolicy: OnFailure说明事项
Volcano支持的计算框架
Volcano对当前主流的计算框架均能很好的支持,具体如下:
- Spark
- TensorFlow
- PyTorch
- Flink
- Argo
- MindSpore
- PaddlePaddle
- Open MPI
- Horovod
- MXNet
- Kubeflow
- KubeGene
- Cromwell
volcano和default-scheduler的选择
与default-scheduler相比,volcano在批处理方面进行了增强。它更适用于高性能计算场景,如机器学习、大数据应用和科学计算。
