使用限制
- 当前通用处理节点仅支持写入内置Hive数据源,其他数据源敬请期待。
创建通用处理节点
在工作流开发页面,您可以通过拖拽“通用处理”节点进入画布完成节点新增。
配置通用处理节点
操作步骤
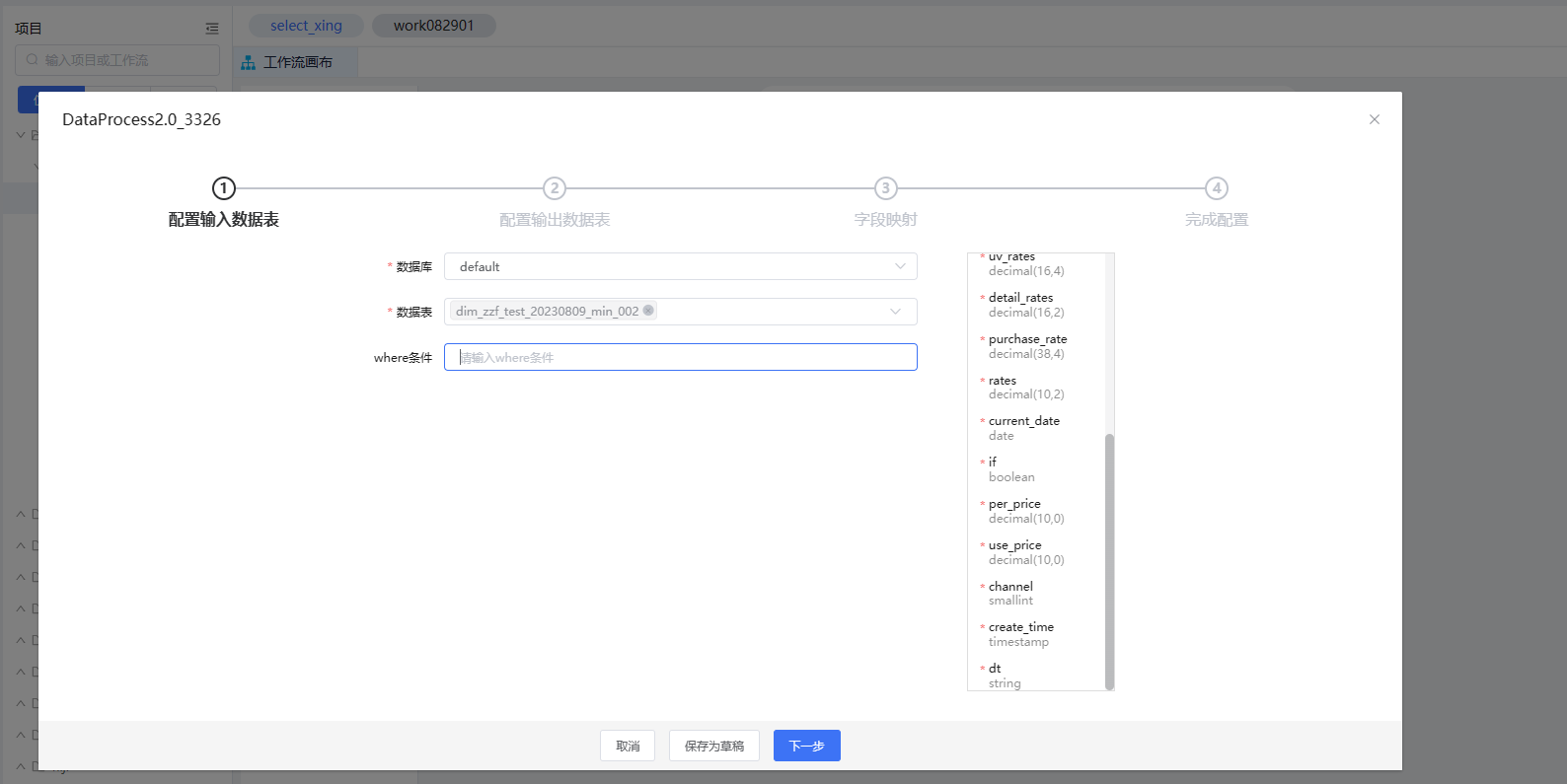
1、配置输入表。
| 参数 | 说明 |
|---|---|
| 数据库 | 选择当前工作流绑定引擎的内置Hive数据源下的数据库。 |
| 数据表 | 选择当前数据库下的数据表。 |
| where条件 | 支持输入where条件,对单表或多表组合后的数据信息进行进一步的筛选。 |
| 输入字段 | 展示所选表的字段信息。 |
| 保存为草稿 | 点击后,为节点保存当前填写的配置信息,返回工作流画布页。 |
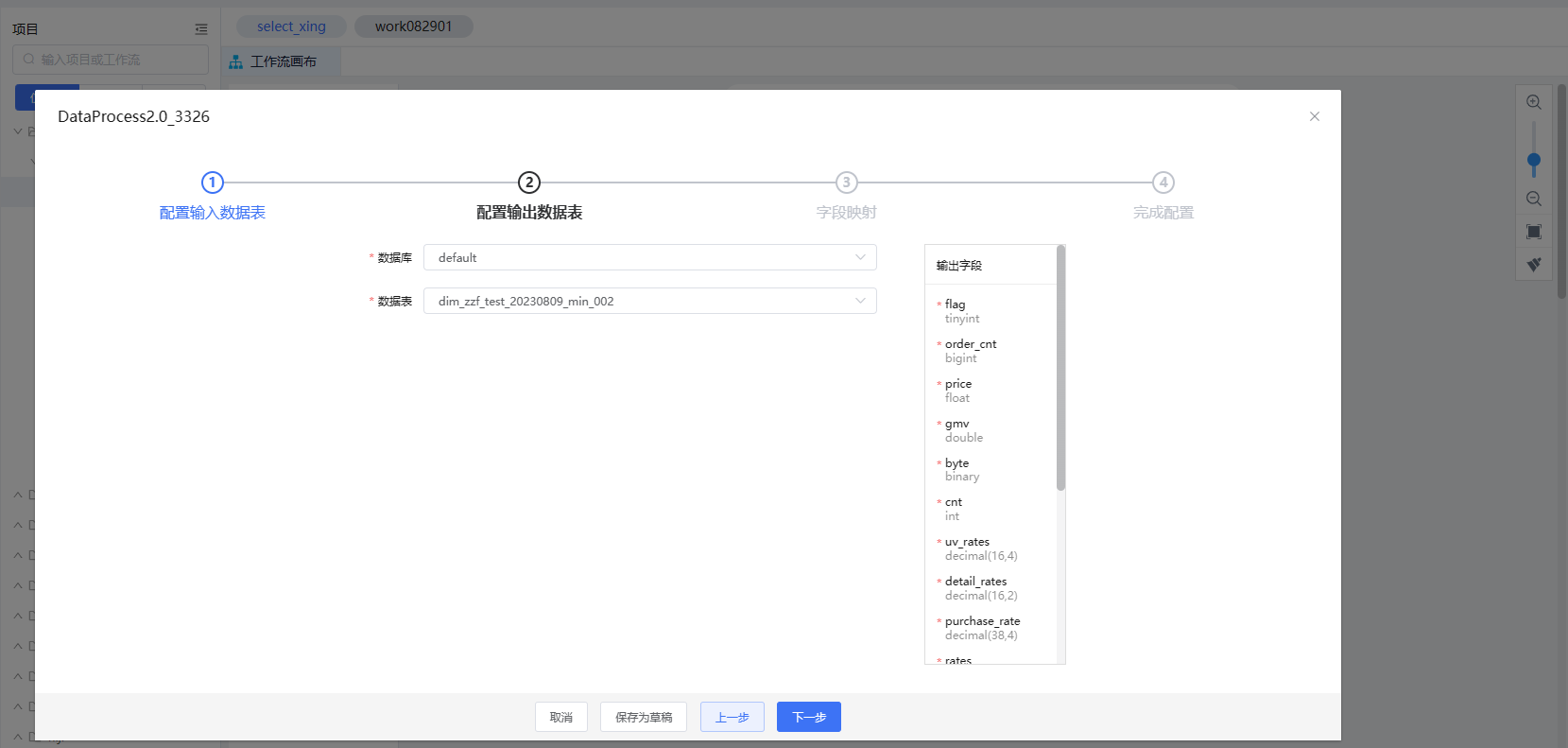
2、配置输出表。
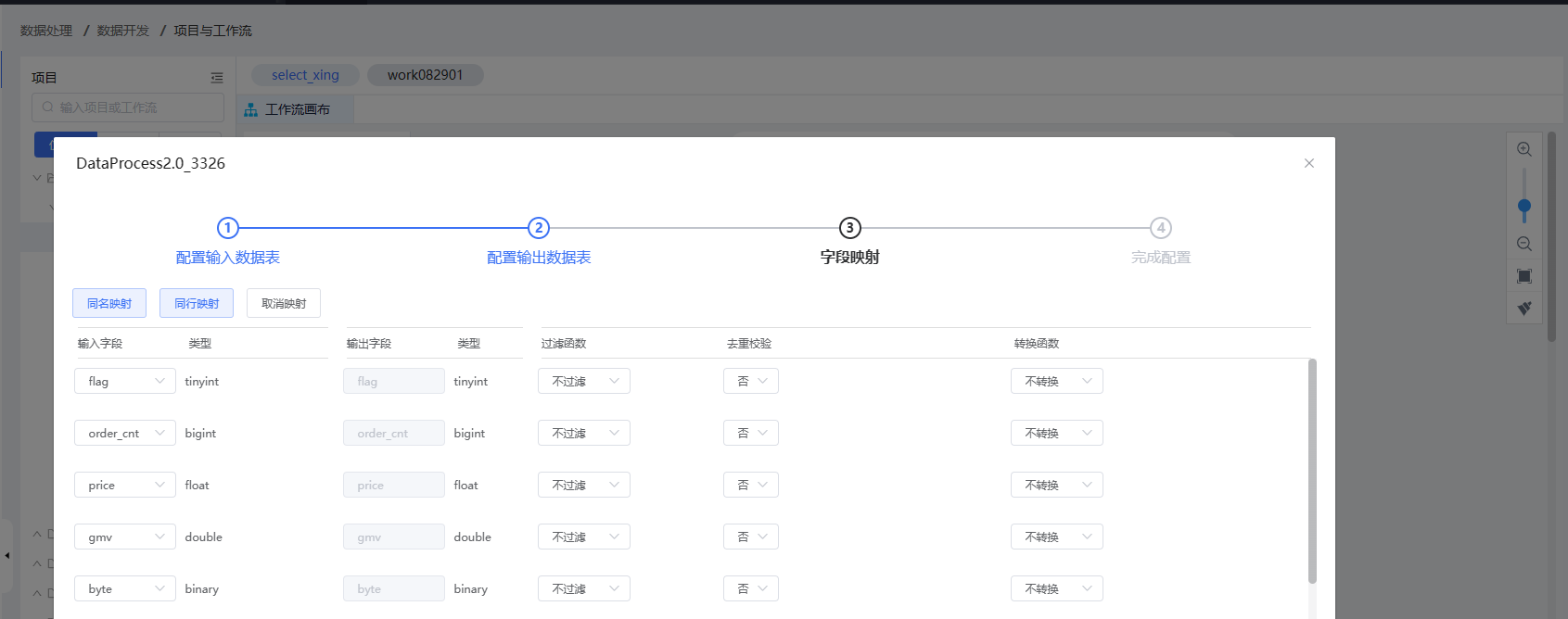
3、配置字段映射。
映射类型描述:
- 同名映射:根据输出字段名来匹配输入字段,进行映射。
- 同行映射:根据输入字段顺序,依次匹配输出字段进行映射。
- 取消映射:取消当前的映射规则。
| 字段 | 说明 |
|---|---|
| 输入字段 | 1)选择当前输入表的字段。 2)自定义输入:您可以输入常量和参数。 常量:可输入任意数字或者字符串。 参数:可输入基于${变量名}格式的参数。 |
| 过滤函数 | 您可以选择多种过滤规则,包括isnull,isnotnull,filterInt,逻辑运算符,模糊匹配,正则匹配等。 |
| 去重校验 | 选择去重后,您可以配置“字段选择”和“保留方式”。 字段选择:用于判定数据记录是否重复的依据。 保留方式:保留规则用于判定该保留哪个数据记录,可保留较大值/保留较小值。 |
| 转换函数 | SQL内置函数:包括LOWER、UPPER、SUBSTRING、LENGTH、ROUND等。 |
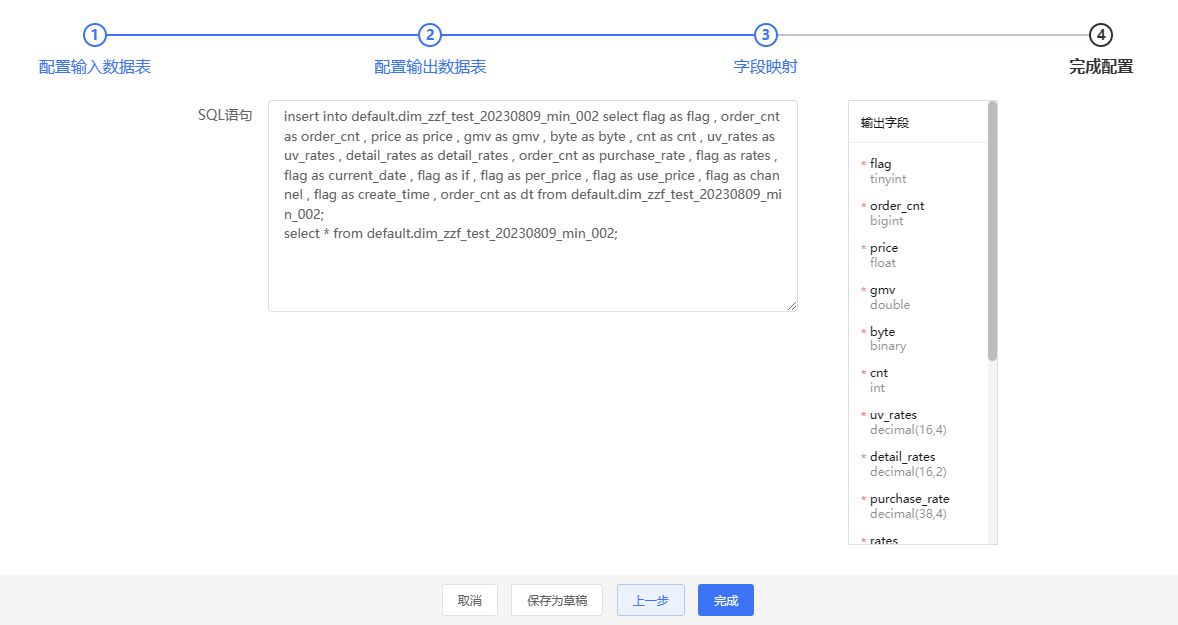
4、预览SQL。
完成前述步骤后,您可以预览和校验自动生成的SQL。