背景信息
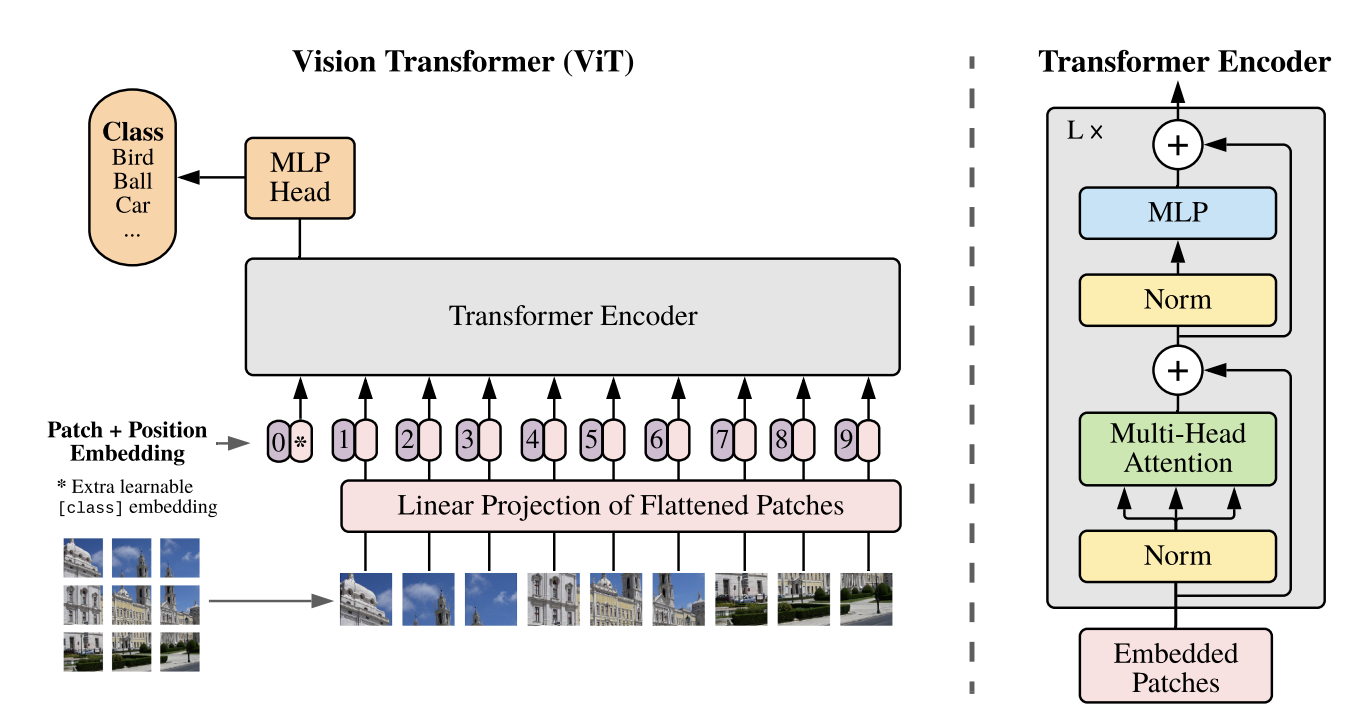
ViT全称Vision Transformer,该模型是在2020年由 Alexey Dosovitskiy 等人提出,将Transformer应用在图像分类的模型,虽然不是第一次将Transformer应用在视觉任务,但模型结构效果好,可扩展性强,成为了Transformer在CV领域应用的里程碑。模型示意图如下:

实例环境如下表所示。
| 实例类型 | pi2.2xlarge.4 |
|---|---|
| 所在地域 | 上海7 |
| 系统盘 | 40GB |
| 数据盘 | 10GB |
| 操作系统 | Ubuntu 18.04.5 LTS |
| 公网弹性IP带宽 | 5Mbps |
操作步骤
- 配置PyTorch开发环境。
a. 安装NVIDIA GPU驱动、CUDA和CUDNN组件。
执行以下命令,安装NVIDIA显卡驱动。
apt install tar gcc g++ make build-essential
chmod +x NVIDIA-Linux-x86_64-515.65.01.run
./NVIDIA-Linux-x86_64-515.65.01.run --no-opengl-files
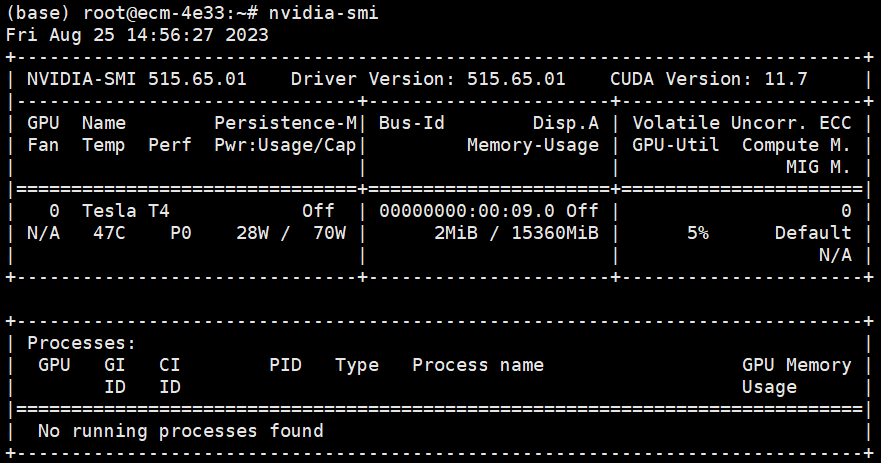
安装完成后执行nvidia-smi命令,查看是否安装成功。

./cuda_11.7.0_515.43.04_linux.run
tar xJvf cudnn-linux-x86_64-8.5.0.96_cuda11-archive.tar.xz
cd cudnn-linux-x86_64-8.5.0.96_cuda11-archive
sudo cp include/* /usr/local/cuda-11.7/include/
sudo cp lib/* /usr/local/cuda-11.7/lib64/
sudo chmod a+r /usr/local/cuda-11.7/include/cudnn*
sudo chmod a+r /usr/local/cuda-11.7/lib64/libcudnn*
b. 配置conda环境。
依次执行以下命令,配置conda 环境。
wget -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-py39_4.12.0-Linux-x86_64.sh
chmod +x Miniconda3-py39_4.12.0-Linux-x86_64.sh
./Miniconda3-py39_4.12.0-Linux-x86_64.sh
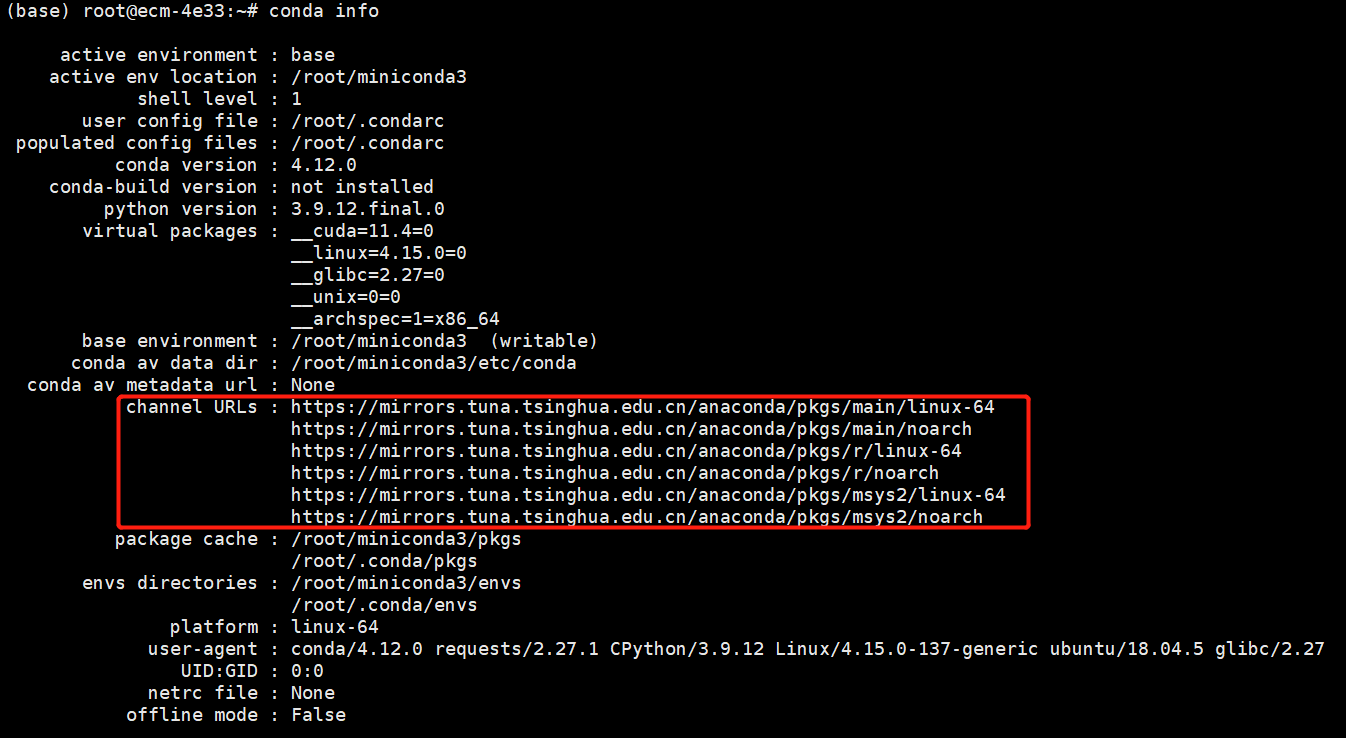
c. 编辑~/.condarc 文件,加入下图配置信息,将 conda 的软件源替换为清华源。
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
deepmodeling: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
详情请参见:清华大学开源软件镜像站
执行conda info,确认软件源已替换。

d. 执行以下命令替换pip源为清华源。
pip config set global.index-url
https://pypi.tuna.tsinghua.edu.cn/simple/
e. 安装Pytorch组件。
执行以下命令,安装 PyTorch。
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url
https://download.pytorch.org/whl/cu117
依次执行以下命令,查看PyTorch 是否安装成功。

- 实验数据。
CIFAR-10(Canadian Institute for Advanced Research-10)是一个常用的计算机视觉数据集,用于图像分类任务。它由60000个32x32彩色图像组成,这些图像均来自于10个不同的类别,每个类别包含6000个图像。数据集被分为两个部分:训练集和测试集,其中训练集包含50000个图像,测试集包含10000个图像。CIFAR-10数据集中的图像涵盖了广泛的对象类别,包括飞机、汽车、鸟类、猫、鹿、狗、青蛙、马、船和卡车。每个图像都有一个标签,表示它所属的类别。这个数据集被广泛用于计算机视觉领域的算法开发、模型训练和性能评估。
- 使用ColossalAI-Examples模型训练。
本文在分布式训练框架 Colossal-AI 的基础上进行模型训练和开发。Colossal-AI 提供了一组便捷的接口,通过这组接口能方便地实现数据并行、模型并行、流水线并行或者混合并行。
a. 安装Colossal-AI和其他组件。
pip install colossalai timm titans
b. ViT示例模型训练。
git clone https://github.com/hpcaitech/ColossalAI-Examples.git
cd ColossalAI-Examples/image/vision_transformer/data_parallel
由于单卡T4显存有限,修改config.py文件,将BATCH_SIZE设置为32。执行以下命令启动训练:
colossalai run --nproc_per_node 1 train_with_cifar10.py --config config.py
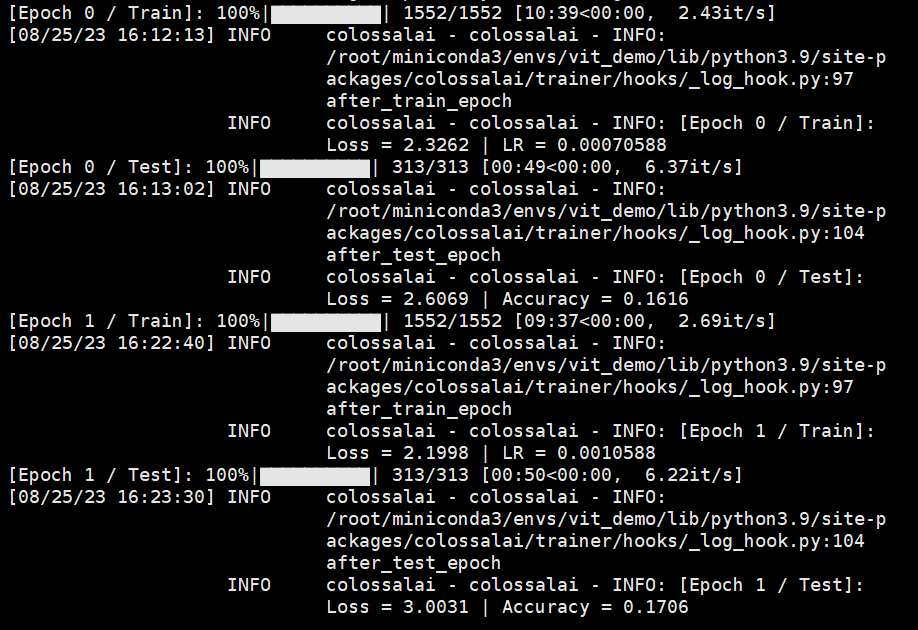
模型运行过程如下图所示: