SQL作业运行慢如何定位
作业运行慢可以通过以下步骤进行排查处理。
可能原因1:FullGC原因导致作业运行慢
判断当前作业运行慢是否是FullGC导致:
1.登录DLI控制台,单击“作业管理 > SQL作业”。
2.在SQL作业页面,在对应作业的“操作”列,单击“更多 > 归档日志”。
3.在OBS目录下,获取归档日志文件夹,详细如下。
−Spark SQL作业:
查看带有“driver”或者为“container_ xxx _000001”的日志文件夹则为需要查看的Driver日志目录。
−Spark Jar作业:
Spark Jar作业的归档日志文件夹以“batch”开头。
4.进入归档日志文件目录,在归档日志文件目录下,下载“gc.log.*”日志。
5.打开已下载的“gc.log.*”日志,搜索“Full GC”关键字,查看日志中是否有时间连续,并且频繁出现“Full GC”的日志信息。
FullGC问题原因定位和解决:
原因1 小文件过多 :当一个表中的小文件过多时,可能会造成Driver内存FullGC。
1.登录DLI控制台,选择SQL编辑器,在SQL编辑器页面选择问题作业的队列和数据库。
2.执行以下语句,查看作业中表的文件数量。“ 表名 ”替换为具体问题作业中的表名称。
select count(distinct fn) FROM
(select input_file_name() as fn from 表名) a
3.如果小文件过多,则可以参考SQL作业相关问题章节“作业开发-如何合并小文件”来进行处理。
原因2 广播表 :广播也可能会造成Driver内存的FullGC。
- 登录DLI控制台,单击“作业管理 > SQL作业”。
- 在SQL作业页面,在对应作业所在行,单击按钮,查看作业详情,获取作业ID。
- 在对应作业的“操作”列,单击“Spark UI”,进入“Spark UI”页面。
- 在“Spark UI”页面,在上方菜单栏选择“SQL”。参考下图,根据作业ID,单击Description中的超链接。
- 查看对应作业的DAG图,判断是否有BroadcastNestedLoopJoin节点。
作业的DAG图。
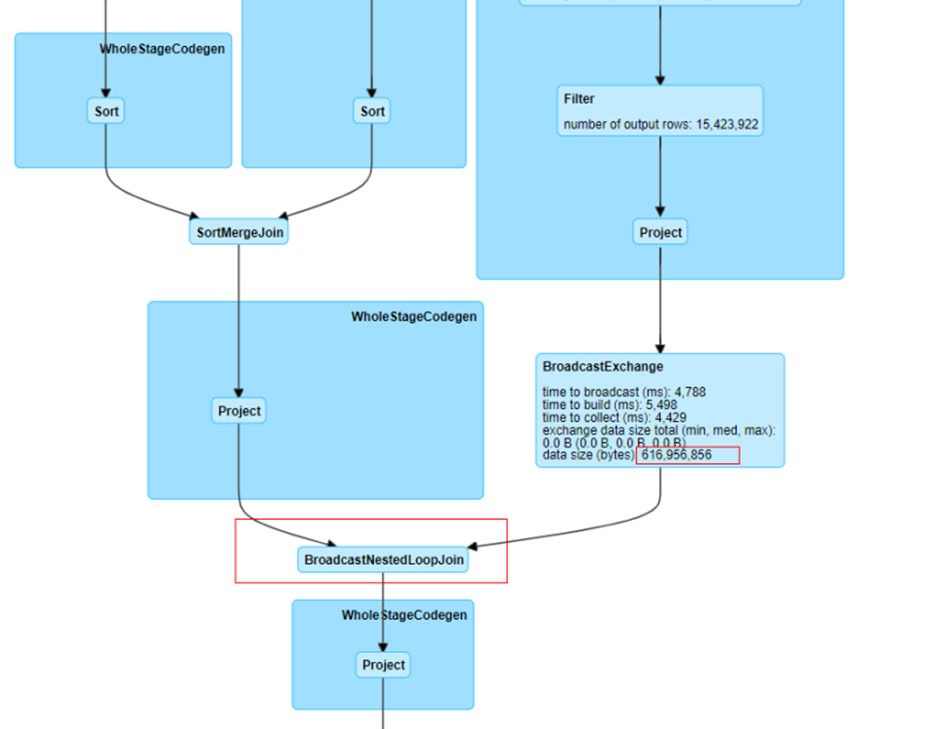
- 如果存在广播,则参考下方“SQL作业中存在join操作,因为自动广播导致内存不足,作业一直运行中”处理。
可能原因2:数据倾斜
判断当前作业运行慢是否是数据倾斜导致
1.登录DLI控制台,单击“作业管理 > SQL作业”。
2.在SQL作业页面,在对应作业所在行,单击按钮,查看作业详情信息,获取作业ID。
3.在对应作业的“操作”列,单击“Spark UI”,进入到Spark UI页面。
4.在“Spark UI”页面,在上方菜单栏选择“Jobs”。参考下图,根据作业ID,单击链接。
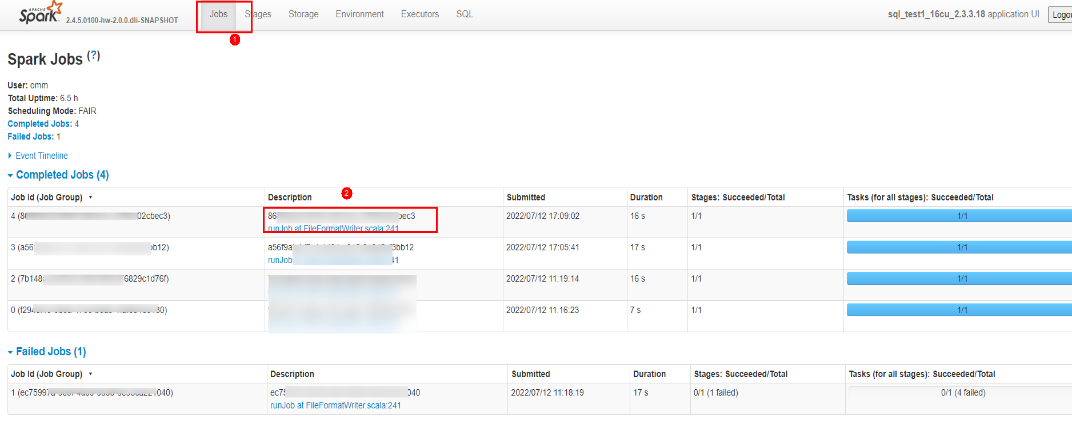
5.根据Active Stage可以看到当前正在运行的Stage运行情况,单击Description中的超链接。

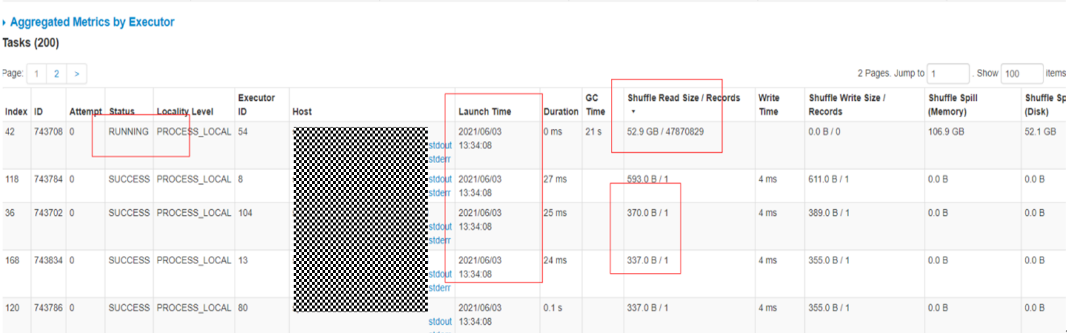
6.在Stage中,可以看到每一个Task开始运行时间“Launch Time”,以及Task运行耗时时间“Duration”。
7.单击“Duration”,可以根据耗时进行排序,排查是否存在单个Task耗时过长导致整体作业时间变长问题。
参考下图可以看到数据倾斜时,单个任务的shuffle数据远大于其他Task的数据,导致该任务耗时时间变长。
数据倾斜示例图
数据倾斜原因和解决
Shuffle的数据倾斜基本是由于join中的key值数量不均衡导致。
1.对join连接条件进行group by 和count,统计每个连接条件的key值的数量。示例如下:
lefttbl表和righttbl表进行join关联,其中lefttbl表的num为连接条件的key值。则可以对lefttbl.num进行group by和count统计。
SELECT * FROM lefttbl a LEFT join righttbl b on a.num = b.int2;
SELECT count(1) as count,num from lefttbl group by lefttbl.num ORDER BY count desc;
2.考虑在对应key值上添加concat(cast(round(rand() *999999999)as string)随机数进行打散。
3.如果确实因为单个key值倾斜严重且不可对key值拼接随机值打散,则参考上方"配置AE参数解决数据倾斜"处理。
查看DLI SQL日志
场景概述
日常运维时需要查看DLI SQL日志。
操作步骤
1.在DataArts Studio控制台获取DataArts Studio执行DLI作业的job id。
查找job id

2.在DLI控制台,选择“作业管理”>“SQL作业”。
3.在SQL作业管理页面,输入对应的job id,找到对应的作业。
4.在“操作”列中,单击“更多”>“归档日志”>“下载日志到本地”。
5.在所下载的日志中搜索对应jobId,即可查看具体的执行日志。
查看DLI的执行SQL记录
场景概述
执行SQL作业过程中需要查看对应的记录。
操作步骤
1.登录DLI管理控制台。
2.在左侧导航栏单击“作业管理”>“SQL作业”进入SQL作业管理页面。
3.输入作业ID或者执行的语句可以筛选所要查看的作业。
配置AE参数解决数据倾斜
场景概述
如果观察到SQL执行时间较长,可进入SparkUI查看对应SQL的执行状态。
如果观察到一个stage运行时间超过20分钟且只剩余一个task在运行,即为数据倾斜的情况。
数据倾斜样例

操作步骤
1.登录数据湖探索管理控制台,选择“SQL作业”,在要修改的作业所在行的“操作”列,单击“编辑”进入SQL编辑器界面。
2.在SQL编辑器界面,单击“设置”,在“配置项”尝试添加以下几个Spark参数进行解决。
参数项如下,冒号前是配置项,冒号后是配置项的值。
spark.sql.enableToString:false
spark.sql.adaptive.join.enabled:true
spark.sql.adaptive.enabled:true
spark.sql.adaptive.skewedJoin.enabled:true
spark.sql.adaptive.enableToString:false
spark.sql.adaptive.skewedPartitionMaxSplits:10
说明spark.sql.adaptive.skewedPartitionMaxSplits表示倾斜拆分力度,可不加,默认为5,最大为10。
3.单击“执行”重新运行作业,查看优化效果。
DLI控制台中无法查询到对应表
问题现象
已知存在某DLI表,但在DLI页面查询不到该表。
问题根因
已有表但是查询不到时,大概率是因为当前登录的用户没有对该表的查询和操作权限。
解决措施
联系创建该表的用户,让该用户给需要操作该表的其他用户赋予查询和操作的权限。赋权操作如下:
1.使用创建表的用户账号登录到DLI管理控制台,选择“数据管理 > 库表管理”。
2.单击对应的数据库名称,进入到表管理界面。在对应表的“操作”列,单击“权限管理”,进入到表权限管理界面。
3.单击“授权”,授权对象选择“用户授权”,用户名选择需要授权的用户名,勾选对应需要操作的权限。如“查询表”、“插入”等根据需要勾选。
4.单击“确定”完成权限授权。
5.授权完成后,再使用已授权的用户登录DLI控制台,查看是否能正常查询到对应表。
OBS表压缩率较高
当Parquet/Orc格式的OBS表对应的文件压缩率较高时(跟文本相比,超过5倍压缩率),建议在提交导入数据到DLI表作业时,在submit-job请求体conf字段中配置“dli.sql.files.maxPartitionBytes=33554432”,该配置项默认值为128MB,将其配置成32MB,可以减少单个任务读取的数据量,避免因过高的压缩比,导致解压后单个任务处理的数据量过大。
如何避免字符码不一致导致的乱码
DLI只支持UTF-8文本格式。
执行创建表和导入操作时,用户的数据需要是以UTF-8编码。
删除表后再重新创建同名的表,需要对操作该表的用户和项目重新赋权
问题场景
A用户通过SQL作业在某数据库下创建了表testTable,并且授权testTable给B用户插入和删除表数据的权限。后续A用户删除了表testTable,并重新创建了同名的表testTable,如果希望B用户继续保留插入和删除表testTable数据的权限,则需要重新对该表进行权限赋予。
问题根因
删除表后再重建同名的表,该场景下表权限不会自动继承,需要重新对需要操作该该表的用户或项目进行赋权操作。
解决方案
表删除再创建后,需要重新对需要操作该表的用户或项目进行赋权操作。具体操作如下:
1.在管理控制台左侧,单击“数据管理”>“库表管理”。
2.单击需要设置权限的表所在的数据库名,进入该数据库的“表管理”页面。
3.单击所选表“操作”栏中的“权限管理”,将显示该表对应的权限信息。
4.单击表权限管理页面右上角的“授权”按钮。
5.在弹出的“授权”对话框中选择相应的权限。
6.单击“确定”,完成表权限设置。
DLI分区内表导入的文件不包含分区列的数据,导致数据导入完成后查询表数据失败
问题现象
DLI分区内表导入了CSV文件数据,导入的文件数据没有包含对应分区列的字段数据。分区表查询时需要指定分区字段,导致查询不到表数据。
问题根因
DLI分区内表在导入数据时,如果文件数据没有包含分区字段,则系统会默认指定分区值“ HIVE_DEFAULT_PARTITION ”,当前Spark判断分区为空时,则会直接返回null,不返回具体的数据。
解决方案
1.登录DLI管理控制台,在“SQL编辑器”中,单击“设置”。
2.在参数设置中,添加参数“spark.sql.forcePartitionPredicatesOnPartitionedTable.enabled”,值设置为“false”。
3.上述步骤参数设置完成后,则可以进行全表查询,不用查询表的时候要包含分区字段。
创建OBS外表,因为OBS文件中的某字段存在回车换行符导致表字段数据错误
问题现象
创建OBS外表,因为指定的OBS文件内容中某字段包含回车换行符导致表字段数据错误。
例如,当前创建的OBS外表语句为:
CREATE TABLE test06 (name string, id int, no string) USING csv OPTIONS (path "obs://dli-test-001/test.csv");
test.csv文件内容如下:
Jordon,88,"aa
bb"
因为最后一个字段的aa和bb之间存在回车换行。创建OBS外表后,查询test06表数据内容显示如下:
name id classno
Jordon 88 aa
bb" null null
解决方案
创建OBS外表时,通过multiLine=true来指定列数据包含回车换行符。针对举例的建表语句,可以通过如下示例解决:
CREATE TABLE test06 (name string, id int, no string) USING csv OPTIONS (path "obs://dli-test-001/test.csv",multiLine=true);
SQL作业中存在join操作,因为自动广播导致内存不足,作业一直运行中
问题现象
SQL作业中存在join操作,作业提交后状态一直是运行中,没有结果返回。
问题根因
Spark SQL作业存在join小表操作时,会触发自动广播所有executor,使得join快速完成。但同时该操作会增加executor的内存消耗,如果executor内存不够时,导致作业运行失败。
解决措施
1.排查执行的SQL中是否有使用“/*+ BROADCAST(u) */”强制做broadcastjoin。如果有,则需要去掉该标识。
2.设置spark.sql.autoBroadcastJoinThreshold=-1,具体操作如下:
a.登录DLI管理控制台,单击“作业管理 > SQL作业”,在对应报错作业的“操作”列,单击“编辑”进入到SQL编辑器页面。
b.单击“设置”,在参数设置中选择“spark.sql.autoBroadcastJoinThreshold”参数,其值设置为“-1”。
c.重新单击“执行”,运行该作业,观察作业运行结果。
join表时没有添加on条件,造成笛卡尔积查询,导致队列资源爆满,作业运行失败
问题现象
运行的SQL语句中存在join表,但是join没有添加on条件,多表关联造成笛卡尔积查询,最终导致队列资源占满,该队列上的作业运行失败。
例如,如下问题SQL语句,存在三个表的left join,并且没有指定on条件,造成笛卡尔积查询。
select
case
when to_char(from_unixtime(fs.special_start_time), 'yyyy-mm-dd') < '2018-10-12' and row_number() over(partition by fg.goods_no order by fs.special_start_time asc) = 1 then 1
when to_char(from_unixtime(fs.special_start_time), 'yyyy-mm-dd') >= '2018-10-12' and fge.is_new = 1 then 1
else 0 end as is_new
from testdb.table1 fg
left join testdb.table2 fs
left join testdb.table3 fge
where to_char(from_unixtime(fs.special_start_time), 'yyyymmdd') = substr('20220601',1,8)
解决措施
在使用join进行多表关联查询时,不管表数据量大小,join时都需要指定on条件来减少多表关联的数据量,从而减轻队列的负荷,提升查询效率。
例如,问题现象中的问题语句可以根据业务场景,在join时通过指定on条件来进行优化,这样会极大减少关联查询的结果集,提升查询效率。
select
case
when to_char(from_unixtime(fs.special_start_time), 'yyyy-mm-dd') < '2018-10-12' and row_number() over(partition by fg.goods_no order by fs.special_start_time asc) = 1 then 1
when to_char(from_unixtime(fs.special_start_time), 'yyyy-mm-dd') >= '2018-10-12' and fge.is_new = 1 then 1
else 0 end as is_new
from testdb.table1 fg
left join testdb.table2 fs on fg.col1 = fs.col2
left join testdb.table3 fge on fg.col3 = fge.col4
where to_char(from_unixtime(fs.special_start_time), 'yyyymmdd') = substr('20220601',1,8)
手动在OBS表的分区目录下添加了数据,但是无法查询到该部分数据
问题现象
手动在OBS表的分区目录下上传了分区数据,但是在SQL编辑器中查询该表新增的分区数据时却查询不到。
解决方案
手动添加分区数据后,需要刷新OBS表的元数据信息。具体操作如下:
MSCK REPAIR TABLE table_name ;
执行完上述命令后,再执行对应OBS分区表的数据查询即可。
为什么insert overwrite覆盖分区表数据的时候,覆盖了全量数据?
如果需要动态覆盖DataSource表指定分区数据,需要先配置参数:dli.sql.dynamicPartitionOverwrite.enabled=true,再通过“insert overwrite”语句实现,“dli.sql.dynamicPartitionOverwrite.enabled”默认值为“false”。
为什么SQL作业一直处于“提交中”?
SQL作业一直在提交中,有以下几种可能:
- 刚购买DLI队列后,第一次进行SQL作业的提交。需要等待5~10分钟,待后台拉起集群后,即可提交成功。
- 若刚刚对队列进行网段修改,立即进行SQL作业的提交。需要等待5~10分钟,待后台重建集群后,即可提交成功。
- 按需队列,已空闲状态(超过1个小时)。后台资源已经释放。此时进行SQL作业的提交。需要等待5~10分钟,待后台重新拉起集群后,即可提交成功。
跨源连接RDS表中create_date字段类型是datetime,为什么dli中查出来的是时间戳呢?
Spark中没有datetime数据类型,其使用的是TIMESTAMP类型。
您可以通过函数进行转换。
例如:
select cast(create_date as string), * from
table where create_date>'2221-12-01 00:00:00';
SQL作业执行完成后,修改表名导致datasize修改失败怎么办?
如果执行SQL后立即修改了表名,可能会导致表的数据大小结果不正确。
如需修改表名,建议在SQL作业执行完成后,间隔5分钟再修改表名。
从DLI导入数据到OBS,为什么数据量出现差异?
问题现象
使用DLI插入数据到OBS临时表文件,数据量有差异。
根因分析
出现该问题可能原因如下:
- 作业执行过程中,读取数据量错误。
- 验证数据量的方式不正确。
通常在执行插入数据操作后,如需确认插入数据量是否正确,建议通过查询语句进行查询。
如果OBS对存入的文件数量有要求,可以在插入语句后加入“DISTRIBUTE BY number”。例如,在插入语句后添加“DISTRIBUTE BY 1”,可以将多个task生成的多个文件汇总为一个文件。
操作步骤
1.在管理控制台检查对应SQL作业详情中的“结果条数”是否正确。 检查发现读取的数据量是正确的。
2.确认客户验证数据量的方式是否正确。客户验证的方式如下:
a.通过OBS下载数据文件。
b.通过文本编辑器打开数据文件,发现数据量缺失。
根据该验证方式,初步定位是因为文件数据量较大,文本编辑器无法全部读取。
通过执行查询语句,查询OBS数据进一步进行确认,查询结果确认数据量正确。
因此,该问题为验证方式不正确造成。

