Flink作业如何进行性能调优
概念说明及监控查看
- 消费组积压
消费组积压可通过topic最新数据offset减去该消费组已提交最大offset计算得出,说明的是该消费组当前待消费的数据总量。
如果Flink作业对接的是kafka专享版,则可通过云监控服务(CES)进行查看。具体可选择“云服务监控 > 分布式消息服务 > kafka专享版” ,单击“kafka实例名称 > 消费组” ,选择具体的消费组名称,查看消费组的指标信息。
- 反压状态
反压状态是通过周期性对taskManager线程的栈信息采样,计算被阻塞在请求输出Buffer的线程比率来确定,默认情况下,比率在0.1以下为OK,0.1到0.5为LOW,超过0.5则为HIGH。
- 时延
Source端会周期性地发送带当前时间戳的LatencyMarker,下游算子接收到该标记后,通过当前时间减去标记中带的时间戳的方式,计算时延指标。算子的反压状态和时延可以通过Flink UI或者作业任务列表查看,一般情况下反压和高时延成对出现:
性能分析
由于Flink的反压机制,流作业在存在性能问题的情况下,会导致数据源消费速率跟不上生产速率,从而引起Kafka消费组的积压。在这种情况下,可以通过算子的反压和时延,确定算子的性能瓶颈点。
- 作业最后一个算子(Sink)反压正常(绿色),前面算子反压高(红色)

该场景说明性能瓶颈点在sink,此时需要根据具体数据源具体优化,比如对于JDBC数据源,可以通过调整写出批次(connector.write.flush.max-rows)、JDBC参数重写(rewriteBatchedStatements=true)等进行优化。
- 作业非倒数第二个算子反压高(红色)

该场景说明性能瓶颈点在Vertex2算子,可以通过查看该算子描述,确认该算子具体功能,以进行下一步优化。
- 所有算子反压都正常(绿色),但存在数据堆积

该场景说明性能瓶颈点在Source,主要是受数据读取速度影响,此时可以通过增加Kafka分区数并增加source并发解决。
- 作业一个算子反压高(红色),而其后续的多个并行算子都不存在反压(绿色)
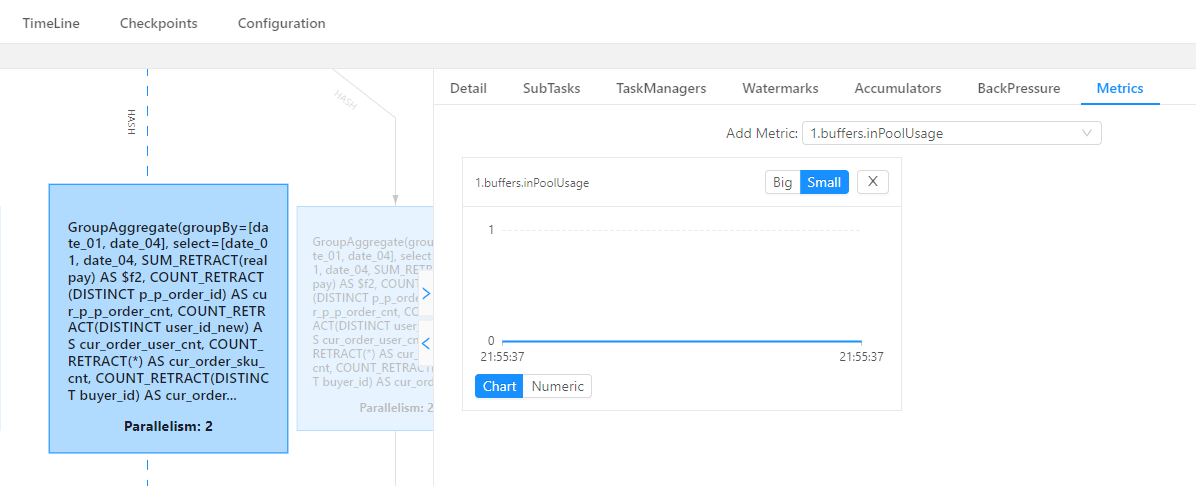
该场景说明性能瓶颈在Vertex2或者Vertex3,为了进一步确定具体瓶颈点算子,可以在FlinkUI页面开启inPoolUsage监控。如果某个算子并发对应的inPoolUsage长时间为100%,则该算子大概率为性能瓶颈点,需分析该算子以进行下一步优化。
inPoolUsage监控
性能调优
rocksdb状态调优
topN排序、窗口聚合计算以及流流join等都涉及大量的状态操作,因而如果发现这类算子存在性能瓶颈,可以尝试优化状态操作的性能。主要可以尝试通过如下方式优化:
1.增加状态操作内存,降低磁盘IO
- 增加单slot cu资源数
- 配置优化参数:
-taskmanager.memory.managed.fraction=xx
-state.backend.rocksdb.block.cache-size=xx
-state.backend.rocksdb.writebuffer.size=xx
2.开启微批模式,避免状态频繁操作
配置参数:
-
table.exec.mini-batch.enabled=true
-
table.exec.mini-batch.allow-latency=xx
-
table.exec.mini-batch.size=xx
3.使用超高IO本地盘规格机型,加速磁盘操作
group agg单点及数据倾斜调优
按天聚合计算或者group by key不均衡场景下,group聚合计算存在单点或者数据倾斜问题,此时,可以通过将聚合计算拆分成Local-Global进行优化。配置方式为设置调优参数: table.optimizer.aggphase-strategy=TWO_PHASE
count distinct优化
- 在count distinct关联key比较稀疏场景下,即使使用Local-Global,单点问题依然非常严重,此时可以通过配置以下调优参数进行分桶拆分优化:
table.optimizer.distinct-agg.split.enabled=true
table.optimizer.distinct-agg.split.bucket-num=xx
- 使用filter替换case when:
例如:
COUNT(DISTINCT CASE WHEN flag IN ('android', 'iphone')THEN user_id ELSE NULL END) AS app_uv
可调整为
COUNT(DISTINCT user_id) FILTER(WHERE flag IN ('android', 'iphone')) AS app_uv
维表join优化
维表join根据左表进入的每条记录join关联键,先在缓存中匹配,如果匹配不到,则从远程拉取。因而,可以通过如下方式优化:
- 增加JVM内存并增加缓存记录条数
- 维表设置索引,加快查询速度
如何在一个Flink作业中将数据写入到不同的Elasticsearch集群中?
在对应的Flink作业中添加如下SQL语句。
create source stream ssource(xx);
create sink stream es1(xx) with (xx);
create sink stream es2(xx) with (xx);
insert into es1 select * from ssource;
insert into es2 select * from ssource;
Flink作业重启后,如何保证不丢失数据?
DLI Flink提供了完整可靠的Checkpoint/Savepoint机制,您可以利用该机制,保证在手动重启或者作业异常重启场景下,不丢失数据。
- 为了避免系统故障导致作业异常自动重启后,丢失数据:
−对于Flink SQL作业,您可以勾选“开启Checkpoint”,并合理配置Checkpoint间隔(权衡执行Checkpoint对业务性能的影响以及异常恢复的时长),同时勾选“异常自动重启”,并勾选“从Checkpoint恢复”。配置后,作业异常重启,会从最新成功的Checkpoint文件恢复内部状态和消费位点,保证数据不丢失及聚合算子等内部状态的精确一致语义。同时,为了保证数据不重复,建议使用带主键数据库或者文件系统作为目标数据源,否则下游处理业务需要加上去重逻辑(最新成功Checkpoint记录位点到异常时间段内的数据会重复消费)。
−对于Flink Jar作业,在代码中开启Checkpoint,同时如果有自定义的状态需要保存,您还需要实现ListCheckpointed接口,并为每个算子设置唯一ID。然后在作业配置中,勾选“从Checkpoint恢复”,并准确配置Checkpoint路径。
说明Flink Checkpoint机制可以保证Flink平台可感知内部状态的精确一致,但对于自定义Source/Sink或者有状态算子,需要合理实现ListCheckpointed接口,来保证业务数据需要的可靠性。
- 为了避免因业务修改等需要,手动重启作业后,不丢失数据:
−对于无内部状态的作业,您可以配置kafka数据源的启动时间或者消费位点到作业停止之前。
−对于有内部状态的作业,您可以在停止作业时,勾选“触发保存点”。成功后,再次启动作业时,开启“恢复保存点”,作业将从选择的savepoint文件中恢复消费位点及状态。同时,由于Flink Checkpoint和Savepoint生成机制及格式一致,因而,也可以通过Flink作业列表“操作”列中的“更多”>“导入保存点”,导入OBS中最新成功的Checkpoint,并从中恢复。

