


论文:Dynamic Contexts for Generating Suggestion Questions in RAGBased Conversational Systems
引言
RAG(检索增强生成)对话系统通过从知识库检索相关信息来增强生成能力,但在实际使用中,用户常常难以准确构建查询,导致问题模糊,系统需要进一步澄清以理解用户意图。为解决这一问题,论文提出了一种建议问题生成器,利用动态上下文来改善用户交互体验。
提出的解决方案
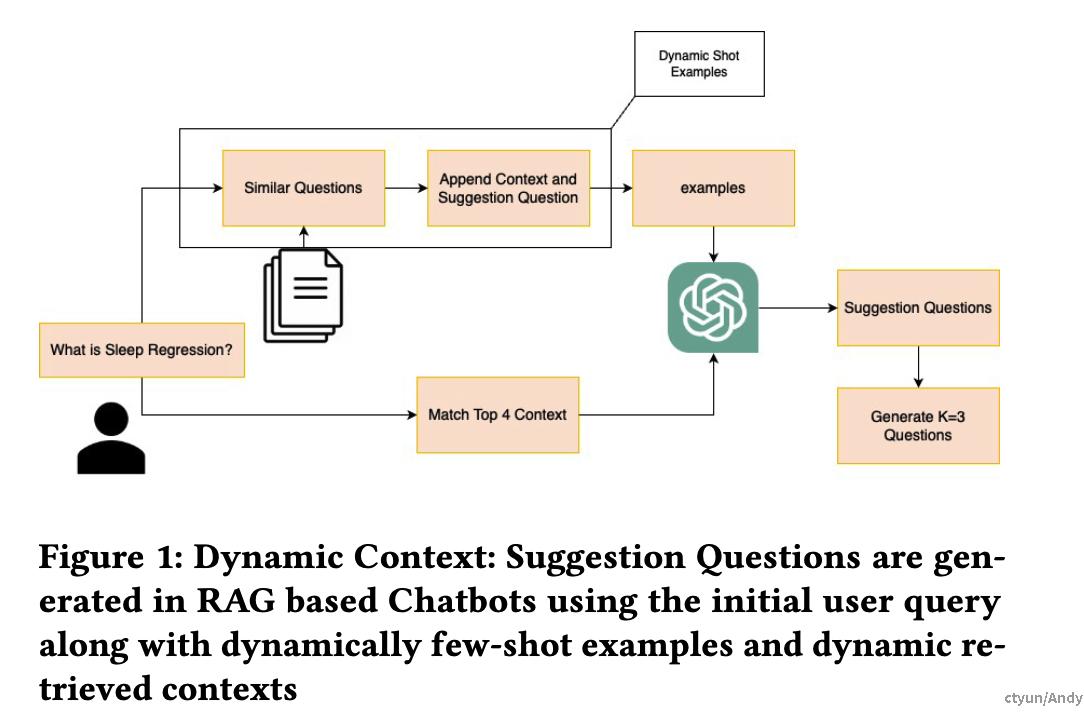
建议问题生成器的核心在于使用动态上下文,这一概念包括两部分:
- 动态少样本示例(Dynamic Few-Shot Examples):与传统少样本学习不同,动态少样本示例根据当前上下文或用户交互动态调整,而不是固定不变。
- 动态检索上下文(Dynamically Retrieved Contexts):根据当前对话或用户查询,从知识库实时检索相关信息。
通过结合这两者,生成器能够提供更相关、更有效的建议问题,帮助用户更好地构建查询。
方法论
数据集
研究使用的数据集来源于Pamper’s Baby Sleep Coach的228篇博客文章。由于缺乏公开的专门数据集,研究者手动标注了其中35篇,以生成建议问题。这些博客内容主要与婴儿睡眠相关,提供了一个实际的测试场景。
模型与评估
研究采用了三种大型语言模型(LLM):
- ChatGPT
- GPT-4
- Claude-2
评估分为多个部分:
-
手动评估:对48个问题-答案-建议(QAS)对进行评估,检查正确性、相关性和合理性。结果如下:
- ChatGPT:44个正确
- Claude-2:44个正确
- GPT-4:46个正确
-
比较分析:将动态上下文方法与零样本、少样本和动态少样本方法进行比较,评估48个样本的正确问题数,结果见下表:
方法 ChatGPT Claude2 GPT-4 零样本 35 30 43 少样本 42 35 40 动态少样本 42 35 43 动态上下文 44 44 46 -
偏好基准测试:通过盲测对48个样本进行人机偏好评估。人类评估结果显示:
- GPT-4:43%偏好
- Claude-2:33%偏好
- 无偏好:24% 此外,GPT-4在57%的情况下更倾向于Claude-2的输出,而Claude-2则显示无偏好。
-
消融研究:研究改变查询和上下文的顺序,评估对结果的影响。结果显示:
- GPT-4:原始顺序46个正确,改变顺序后46个正确
- Claude-2:原始顺序44个正确,改变顺序后44个正确 这表明顺序变化对结果影响不大,证明方法的鲁棒性。
结果与讨论
动态上下文方法在所有三种模型中表现优于其他方法,尤其是在生成正确建议问题方面。比较分析表明,动态上下文方法在ChatGPT和Claude-2上的提升尤为显著,而GPT-4在零样本和动态少样本方法上表现已较强,但动态上下文仍略胜一筹。
偏好基准测试揭示了一个有趣的现象:尽管人类更倾向于GPT-4,但GPT-4本身更倾向于Claude-2的输出(57%),这可能反映了模型间评估与人类判断的差异。这种现象值得进一步研究,特别是在模型偏好与用户体验的关系上。
消融研究的结果进一步验证了动态上下文方法的稳定性,表明查询和上下文顺序的变化不会显著影响生成质量,这为实际部署提供了信心。
结论与未来工作
论文总结道,动态上下文方法有效地解决了RAG对话系统中用户查询构建的难题,通过生成建议问题改善了交互体验。未来,作者计划探索基于用户历史的个性化建议问题生成,以进一步提升系统的适应性和用户满意度。
