


一、相关背景
大型语言模型 (LLM) 在各种任务中展现出惊人的能力,但它们也容易犯下逻辑和事实性错误,尤其是在需要严密推理的任务中,一个错误就可能导致整个解决方案失效。为了提高 LLM 的推理性能,通常使用验证器或奖励模型来评估 LLM 生成的多个候选解决方案,并选择最佳方案。
目前一种常见的应对策略是“最佳N解策略”(Best-of-N):LLM 为给定问题生成 N个候选解决方案,然后学习的奖励模型(验证器)对这些解决方案进行排名并选择最合适的一个。这种策略的有效性取决于验证器的准确性,因此训练出一个更好的验证器至关重要。
**另外,在推理领域中,基于LLM 的验证器通常作为判别式奖励模型进行训练,用于为候选的解决方案分配数字评分,然后将其分类为正确或错误。**然而,这种评分方法并没有利用LLMs 本质上设计的文本生成能力。因此,判别式 RMs无法利用生成式LLMS 的固有优势,如统一指令微调、CoT 推理以及在推理时使用额外的计算以提高性能。虽然简单地 prompt 现成的生成式LLMs的方法(LLM-as-a-Judge)也提供了上述优点,但它在推理任务上的表现通常不如专门训练的基于 LLM 的验证器。
本文提出了一种新的验证器训练方法——生成式验证器 (GenRM),它将验证过程转化为下一个词预测任务,充分利用了预训练 LLM 的文本生成能力。GenRM 不仅能够像传统验证器一样对解决方案进行评分,还能生成推理步骤或评论 (CoT) 来解释其决策,从而更准确地识别错误,并通过多数投票机制进一步提高验证准确性。
二、现有方法&模型
判别式验证器(Discriminative Verifiers)
在推理领域中训练验证器的主流方法是在正确和错误的解决方案的数据集上对 LLMs进行微调,使用二元交叉熵损失。这类验证器会直接为 LLMs生成的解决方案 y 分配一个数值评分 r_{\theta}(x,y)\in[0,1] ,用以估计该解决方案对于问题 x 的正确性。因此,这类验证器没有利用LLMs的文本生成能力。
给定一个奖励建模(RMs)的数据集 D_{RM} = D_{incorrect}\bigcup D_{correct} ** ,按以下方式训练判别式 RMs:**
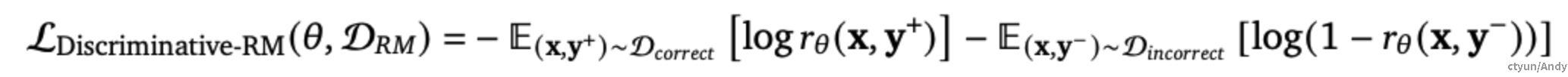
其中 r_{\theta}(x,y)=sigmoid(z_{cls}),z_{cls}=logit(cls|y,x) , y^+ 是正确的解决方案, y^- 是错误的解決方案, cls 对应一个特殊的词汇 token。
GenRM实现细节
基于判别式 LLMs的验证器未能利用预训练LLMs 的文本生成能力。为了解决该问题,作者提出了可以生成文本的验证器,称为 GenRM,使用标准的 next token 预测。GenRM 使用LLMs 对 token 的概率分布来表示解决方案的正确性,而不是预测一个单独的数值分数。GenRM 保持了完整的 LLMs的生成能力,因为验证決策只是另一个 token,同时也具有LLMs 本身的几个优势,如解决方案生成和验证的统一训练、CoT 推理和推理时计算。
直接验证器
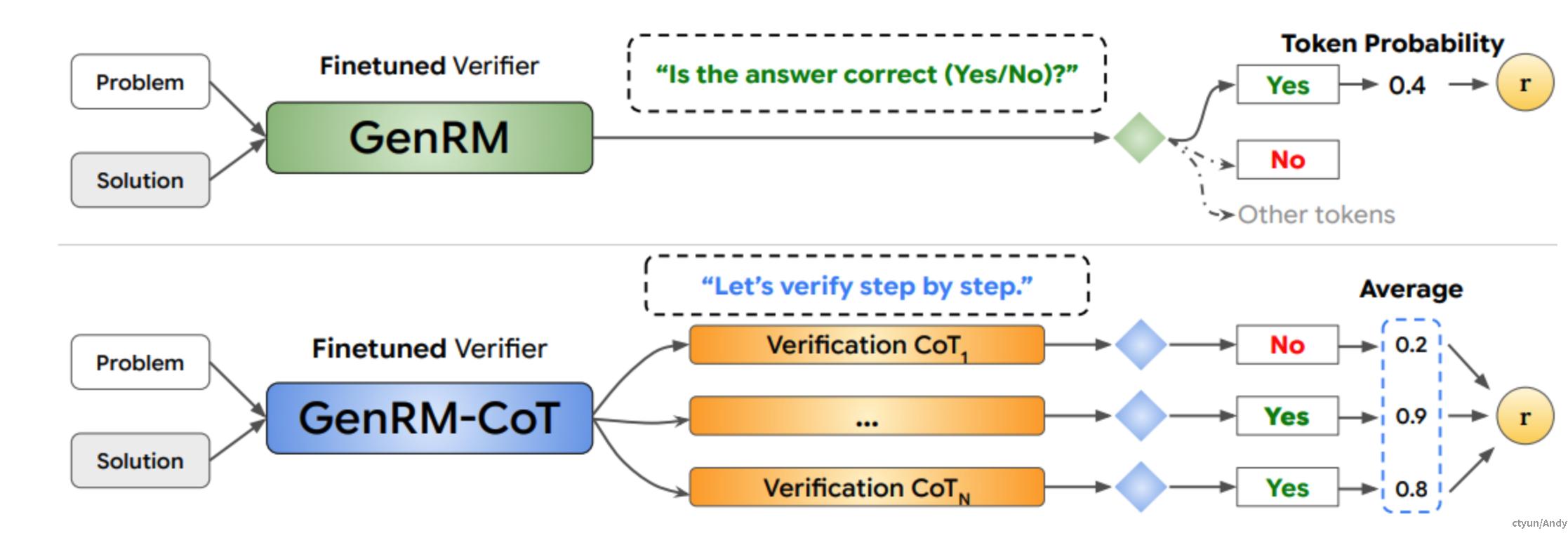
在其最简单的形式中,GenRM 使用单个的**“Yes” 或“No”的token 来预测解決方案是否正确(如下图所示)。这可以通过简单地最大化正确解決方案 y^{+} 的 log_{p_{\theta}('Yes'|(x,y^+,I))} 和错误解决方案 y^- 的 log_{p_{\theta}('No'|(x,y^-,I))} **来完成。

因此在包含<问题,解决方案>对作为输入和单个“Yes” 或“No" token 作为目标的数据集D_{Direct}上最小化以下的 SFT 损失:
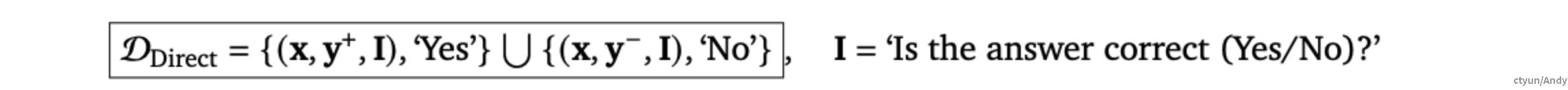
在推理时,使用**“Yes”** token 的可能性作为验证器的分数来重排序解決方案:** r_{Direct}(x,y) = p_{\theta}(Yes,x,y,I) 。该分数考虑了验证器对其正确性预测的信心,减少了使用二元“Yes” 或“No”**预测时被误校准和错误的几率。
统一生成和验证
GenRM 无缝集成了用于区分正确和错误解决方案的奖励模型,以及与生成正确解決方案的监督式微调(SFT)。可以通过简单地改变 SFT 损失计算中的数据混合,以包括验证和生成任务来实现。
**给定一个验证数据集 ** D_{verify} ,可以是 ** D_{Direct} ** 或 ** D_{CoT} ** 的问题-解決方案对,带有正确性 tokens(同时可选CoT 推理),GenRM 最小化以下损失:
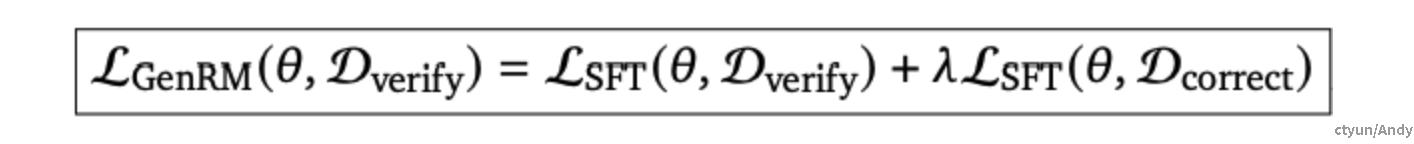
**其中入>0是一个超参数,用于控制数据混合比例,即解决方案验证 ** D_{verify} 和生成正确解決方案 D_{correct} 之间的比例。
这种统一训练可以通过这两个相关任务之间的正向传递来提高验证器和生成性能:如何生成一个正确的解决方案,以及解决方案是否正确。
思维链验证器(GenRM-CoT)
在做出关于解決方案正确性的决定之前,生成中间推理步骤的评价,这可能识别出直接验证器遗漏的推理错误(如下图所示)。

为了训练CoT验证器,将包含问题-解決方案对作为输入,相应的验证理由 v_{CoT} ,以及最终问题 I 和**“Yes” 或“No”** token 作为目标的数据集** D_{CoT} 上最小化SFT损失 L_{GenRM} **:
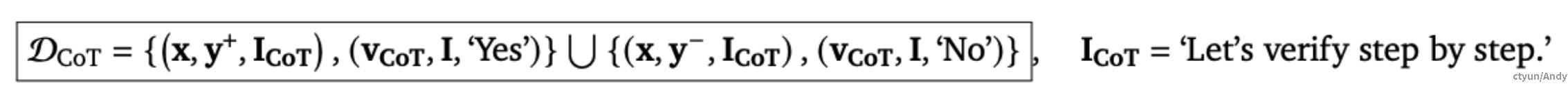
对于 CoT 验证器的推理时计算
在抽样验证 CoT 时,生成式验证器可能会使用不同的推理路径,并为同一个问题-解决方案对提供不同的正确性概率。
因此,作者希望消除中间推理路径,以选择最一致的正确答案。作者使用了多数投票方法,首先生成K个验证CoT 理由,并平均这些理由的CoT 验证器分数:
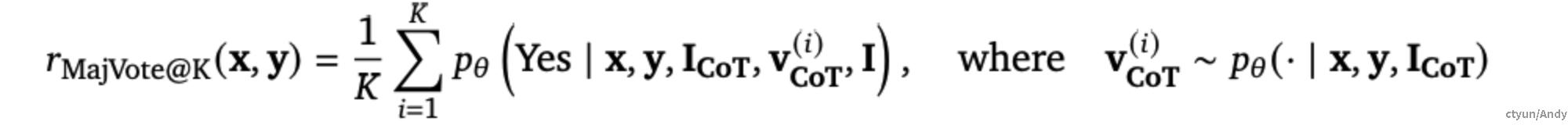
由于单个 CoT 验证理由可能存在推理错误,多数投票可以通过平均多个理由的正确性分数来减轻此类错误的影响。同时这意味着 GenRM-CoT 可以利用额外的推理时计算来提高其准确性,这是判别式验证器无法实现的。默认情况下,作者使用基于32票的多数投票报告 GenRM-CoT的性能,即K=32。
CoT 验证器的合成验证理由
使用人工生成的理由验证解决方案可能会变得越来越昂贵和具有挑战性。为了应对这一挑战,作者在GSM8K 上探索了使用合成生成的理由。
一种简单的方法是使用针对问题-解决方案对的 “Let's verify step by step” prompt,并根据生成的理由是否正确验证解决方案的正确性进行过滤。然而,这样生成的理由常常因为随机猜测的50% 准确率而质量较差。
作者使用参考引导评分来提高合成理由的质量。具体地,除了提供问题和待验证的解决方案外,还提供一个参考解决方案,这使得LLM 更容易指出提供的解决方案中的任何推理错误。这里的参考解決方案定义为任何能够得出正确最终答案的模型生成的解決方案,参考引导评分只能在训练期间使用,在测试问题中并没有参考解决方案。
三、实验结果分析
任务和数据生成
- 最后一个字母连接(Last Letter Concatenation ):给定一个单词列表,任务是连接每个单词的最后一个字母(例如,“Noah Paul Elisha Rebecca”-“hlaa”)。在长度为2~4的单词列表上训练验证器,并在长度为6的超出分布范围外(OOD)设置上评估验证器。
- 单词排序(Word sorting):给定一个单词列表,按字母顺序进行排序。在最多4个单词的列表上训练验证器,并在5个单词的列表上评估泛化性能。
- GSM8K:一个广泛用于评估 LLMs在小学数学推理能力的数据集。在训练中,每个问题最多使用16个正确和16个错误的解决方案;在测试中,在每个问题的16个解决方案上评估验证器的性能。
Baselines
- 判别式 RM(ORM):一种常用的训练验证器的方法,用于推理任务测试时的重新排序,作为主要基线。
- **Self-consistency **:一种在没有验证器的情况下使用测试时计算的简单方法:从 LLM 生成器中抽取多个解决方案,并选择最常见的答案。
- LLM-as-a-Judge:使用现成的LLM 进行验证。使用CoT prompt产生32个验证理由,用于正确性预测,并选择多数票的正确答案。
模型
对于训练判别式 RM和 GenRM,使用开放权重的Gemma 模型,对算法任务使用Gemma-2B,对GSM8K 使用 Gemma 2B、7B 和 9B;对于解決方案生成以及 LLM-as-a-Judge,对算法任务使用 Gemma 2B,对GSM8K 使用 Gemini 1.0 Pro。
结果对比
baselines vs GenRM
GenRM 通过直接预测 Yes/No token 进行验证,在所有三个任务上都能匹配甚至超越判别式 RM和其他方法(如下图所示)。
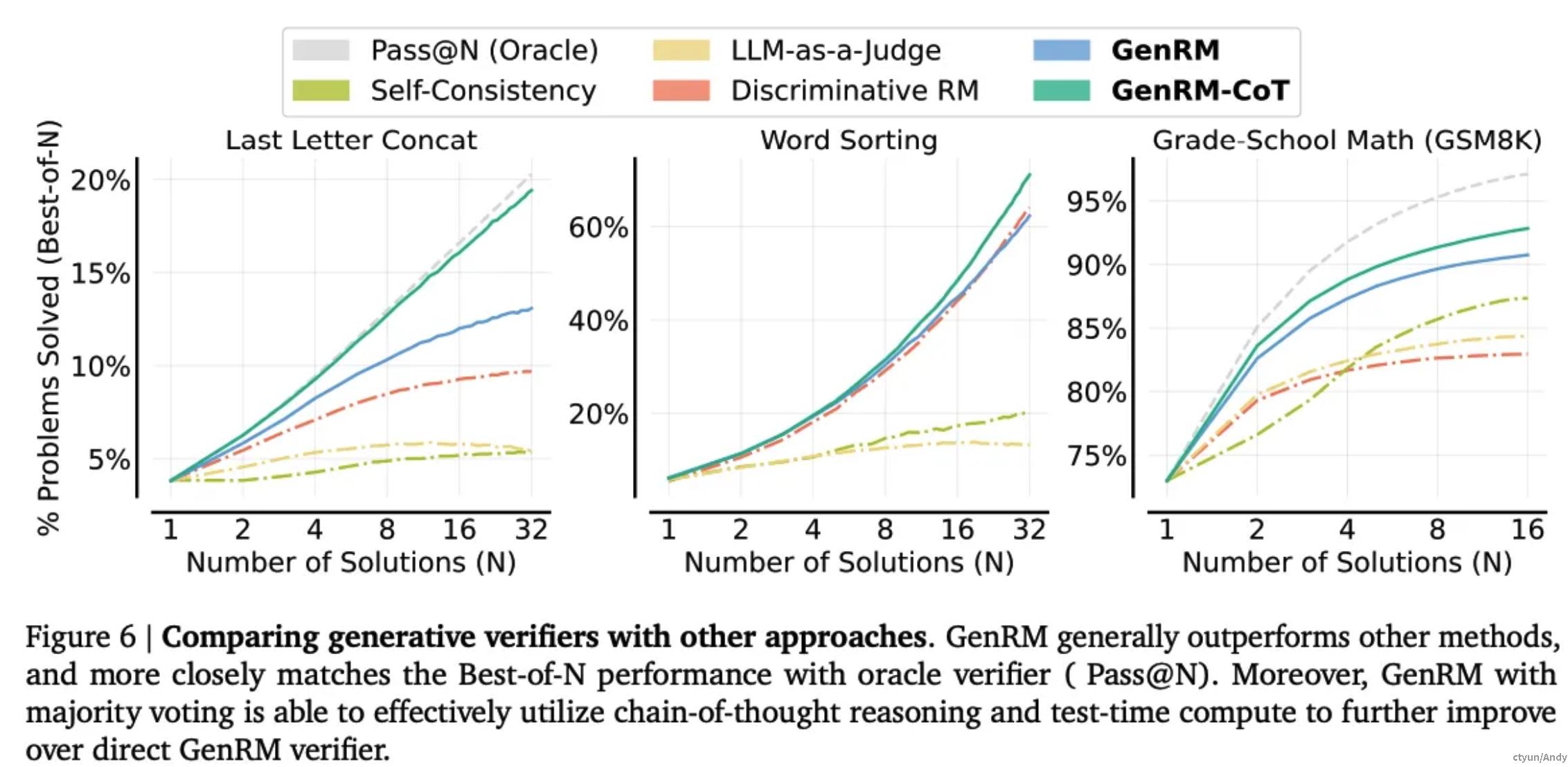
结果表明,next token 预测损失使 GenRM 能够更有效地利用预训练的 Gemma 模型的能力。GenRM-CoT 将 CoT 与多数投票相结合,进一步提高了 GenRM 的性能。特别是在前两个算法任务上,GenRM-CoT 紧密匹配了 Pass@N (Oracle)的性能。在GSM8K上,即使用于训练的CoT 理由(使用 Gemini 1.0 Pro生成)可能包含错误,GenRM-CoT 也始终要优于所有其他方法。
从质量上看,GenRM-CoT 能够检测出判别式验证器遗漏的微妙推理错误(如下图所示)。
b5.png)

统一生成和验证
GenRM 通过 next token预测,将解决方案生成与验证统一化,一致性地提高了所有任务中的验证性能,如下图所示。
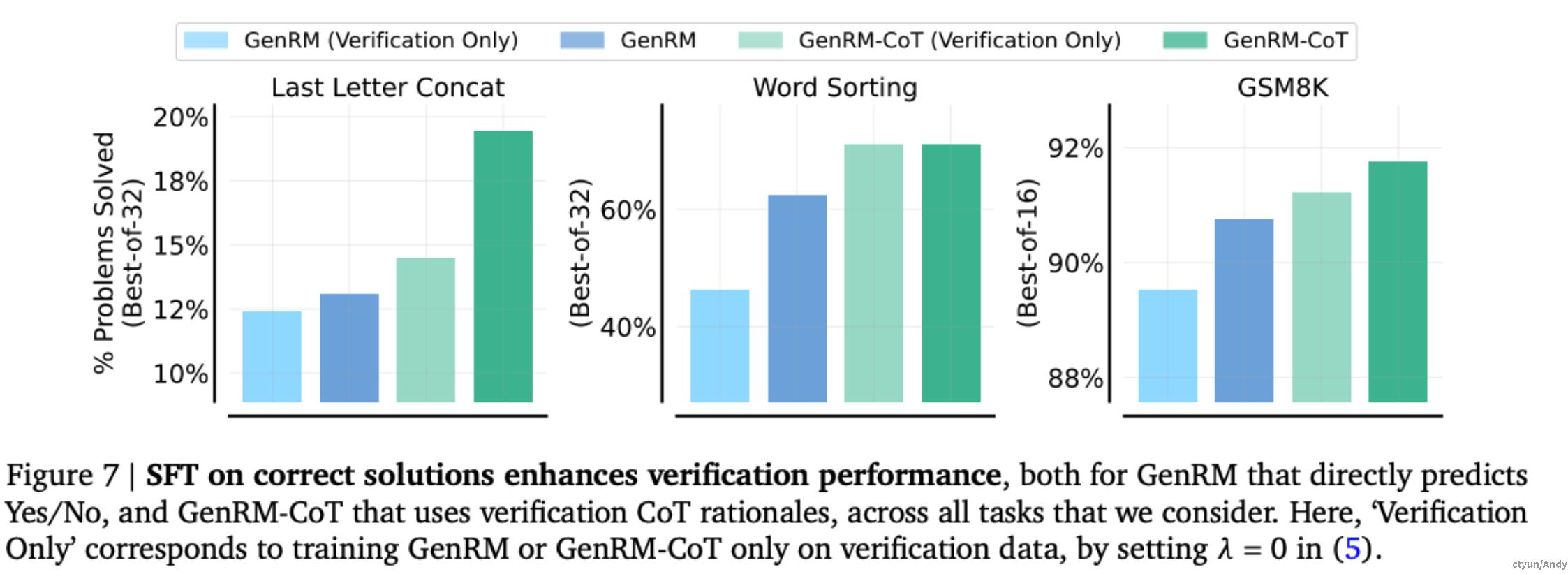
将 CoT 验证数据纳入到生成器的训练混合中,导致GenRM-CoT 验证器本身的解決方案生成性能得到了提高,如下图所示。这表明教导一个生成器基于 next token 预测进行验证可以加深其对生成过程的理解。
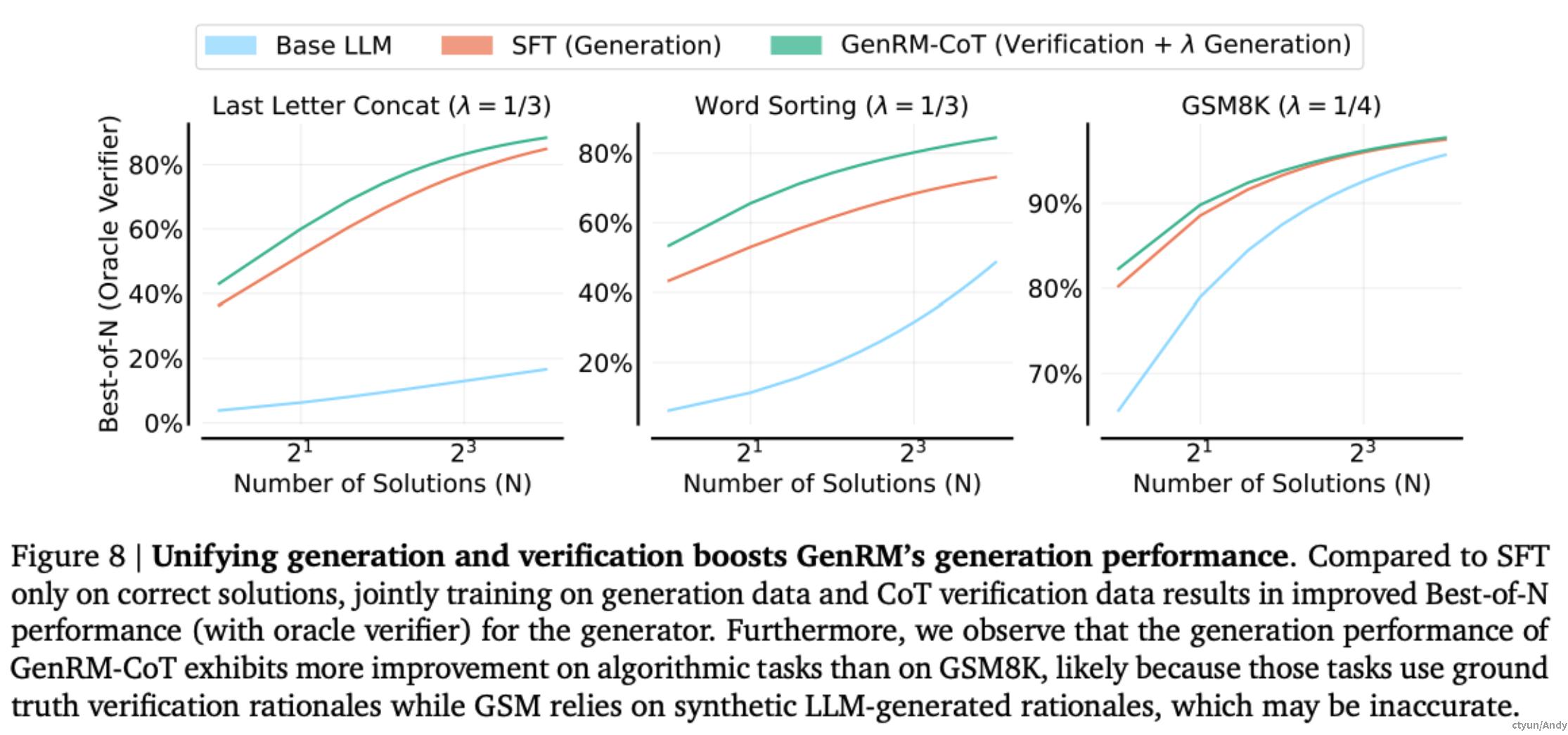
总体来说,解决方案的生成和验证的统一化是相互有益的。
四、总结
GenRM相关优势
GenRM 的核心思想是将验证任务转化为下一个词预测任务,即训练 LLM 在给定问题和候选解决方案的情况下,预测“Yes”或“No”的单个文本词元token来表示解决方案的正确性。这种方法有以下几个关键优势:
(1)与指令微调无缝集成:
GenRM 可以直接应用于指令微调后的 LLM,无需额外的适配。这是因为 GenRM 的训练目标与 LLM 的预训练目标 (下一个词预测) 一致,并且验证任务可以自然地融入指令微调的框架中。例如,我们可以将验证指令 “答案是否正确?” 作为 LLM 的输入,并将其对应的“是”或“否”作为目标输出。
(2)支持思维链推理:
GenRM 可以生成推理步骤或评论(思维链)来解释其验证决策,从而识别出直接验证器可能遗漏的细微推理错误。具体来说,GenRM-CoT 模型会在预测“是”或“否”之前,先生成一段 CoT 文本,例如:
<font style="color:rgb(235, 87, 87);">Let's verify step by step. </font><font style="color:rgb(235, 87, 87);">Step 1: ... (验证步骤 1) </font><font style="color:rgb(235, 87, 87);">Step 2: ... (验证步骤 2) </font><font style="color:rgb(235, 87, 87);">... </font><font style="color:rgb(235, 87, 87);">Verification: Is the answer correct (Yes/No)? Yes/No </font>
这些 CoT 文本可以帮助 GenRM-CoT 模型更全面地理解解决方案的推理过程,并发现潜在的错误。
(3)可利用额外的推理时间计算:
通过多数投票机制,GenRM 可以利用更多的推理时间计算来提高验证准确性。具体来说,GenRM-CoT 模型可以生成多个 CoT 样本,并根据每个样本预测的**“Yes” 或“No”**词元的概率进行多数投票,最终得到一个更可靠的验证结果。这种方法类似于集成学习,可以有效降低单个 CoT 样本可能存在的错误带来的影响。
局限性与未来方向
- 尽管 GenRM 取得了 promising 的结果,但它仍然存在一些局限性:
- 对训练数据的依赖: GenRM 的性能很大程度上取决于训练数据的质量和数量。
- 推理时间成本: 使用 CoT 推理和多数投票机制会较大程度增加 GenRM 的推理时间成本。
- 未来的研究方向包括:
- 探索更有效的数据生成方法: 例如,使用弱监督学习或数据增强技术来减少对高质量标注数据的需求。
- 优化推理效率: 例如,使用模型压缩或知识蒸馏技术来减少 CoT 推理和多数投票带来的计算开销。
- 扩展到更广泛的任务: 例如,将 GenRM 应用于代码生成、文本摘要和机器翻译等任务,并探索如何利用其生成能力来提高这些任务的性能。
