



时间:2024年11月1日
多专家Prompt: 让LLM拥有群体决策的智慧
一、背景痛点
大型语言模型(LLM)虽然在解决通用问题方面能力很强,但其可靠性、安全性以及有用性仍有待提高,主要体现在以下几个方面:
-
单一视角的局限性: 现有的ExpertPrompting方法虽然通过模拟专家来引导LLM生成答案,但其依赖于单一专家的视角,容易产生偏差和片面性。在面对开放问题时单一专家模型难以提供全面、多维度的答案,容易造成信息缺失和观点偏颇。例如“吃肉道德吗?”单一专家可能仅从伦理学视角出发,而忽略营养学、环境科学等其他重要因素,只能给出片面的结论。
-
对LLM潜在风险的忽视: 现有方法未能有效解决LLM可能产生的有害内容(如毒性、伤害性)以及事实错误等问题。
二、解决方案:多元化的决策流程
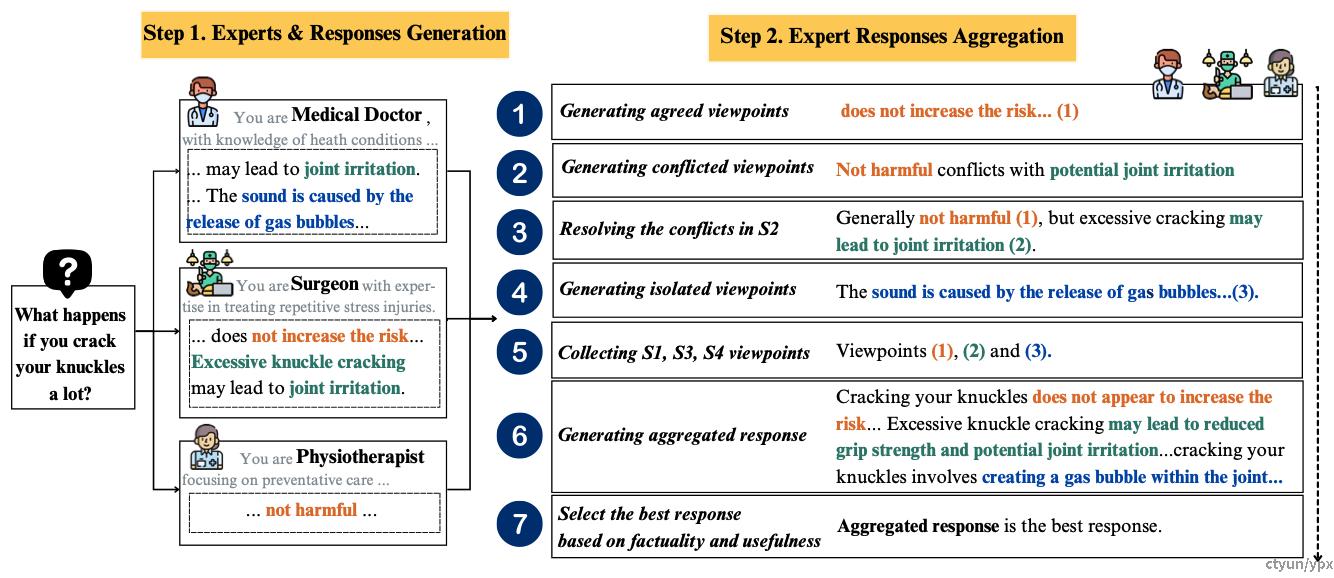
论文提出的解决方案是多专家提示法(Multi-expert Prompting),该方法扩展了ExpertPrompting,通过模拟多个专家来生成答案。多专家Prompt的核心思想是将复杂问题的解决过程多元化。为此,本文采用了一种基于NGT(名义群体技术,Nominal Group Technique)框架的方法来进行决策,该过程可以概括为两个关键步骤:
-
专家生成与回答阶段
-
自动生成专家身份:对于每个输入的问题,系统会自动生成三个最适合的专家身份,每个专家代表一种独特的知识领域或解决问题的方式。这些专家身份的生成是基于问题的特性和需求,确保对问题有多角度的理解。
-
独立作答:每个专家会独立对问题进行回答,给出其领域内的见解。独立作答的过程确保了每个专家不会受到其他观点的干扰,从而保留了答案的独立性。
-
简洁的角色描述:专家身份的描述采用简短的一句话,避免冗长的说明。这样的设计提高了生成专家身份的效率,并能更快速地引导模型进入适合的角色。
-
-
答案聚合阶段
-
识别共识观点:通过对各个专家的回答进行比较,识别出超过半数专家认同的共识观点,形成一个基本框架。
-
发现分歧点:系统明确记录专家间的分歧,并找出这些分歧的核心原因。这一阶段对于理解问题的多样性有着重要意义。
-
解决冲突:基于已经识别的共识框架,系统对分歧进行合理评判,尝试找到一个可以接受的折中方案,使回答更具包容性。
-
提取独特见解:保留每个专家提出的独特见解,确保系统在最终答案中涵盖不同的思考维度,而不仅仅是达成共识。
-
整合各方观点:将共识、折中解决的分歧和独特见解相结合,形成一个多维度的综合答案。
-
生成综合答案:基于整合后的观点撰写综合答案,保持逻辑的连贯性和结构的合理性。
-
选择最优方案:将每个专家的个体答案与综合答案进行对比,从中选择事实准确性和实用性最优的方案作为最终输出。
-
三、技术创新:七步聚合法则
Multi-expert prompting的核心方法是step 2,利用人类决策的经典框架NGT聚合multi-agent系统中的长回复。通过单轮zero-shot CoT实现,方法简洁有效,也提升了回复的可解释性。
-
提取共识观点 (S1)
通过对专家们的回答进行分析,识别出超过半数专家共同认可的观点。这些观点作为基础共识,构建回答的核心框架。
-
发现冲突观点 (S2)
针对专家之间存在的分歧进行详细分析,明确指出具体的争议点以及各自的立场。这一步的重点在于确保所有的观点和潜在的争议都得到了记录和理解。
-
解决冲突 (S3)
基于前面的共识框架,对每个分歧进行评估,寻找合理的折中方案。这个过程不仅有助于平衡各个专家的意见,还能通过妥协和融合得到更全面的视角。
-
提取独特见解 (S4)
提取每个专家的独特见解,尤其是那些没有被纳入共识和冲突中的部分。这些独特见解保证了回答的多样性,使模型不会因为过度妥协而失去创新性。
-
汇总关键观点 (S5)
将共识、解决后的分歧和独特见解汇总,形成一个较为完整且具有层次的观点体系,确保最终回答涵盖各个方面的重要信息。
-
生成综合答案 (S6)
基于汇总的结果撰写综合答案,确保答案具有逻辑上的连贯性和表达上的一致性。这一步的核心是通过语言生成技术将各部分信息有机地结合在一起。
-
最优答案选择 (S7)
最后,将综合答案与个体专家的答案进行对比,基于事实准确性、信息丰富性和实用性等标准选择最终的输出。这个选择过程有助于确保模型给出的答案是最优的。
四、实验验证:显著提升输出质量
-
真实性提升:
-
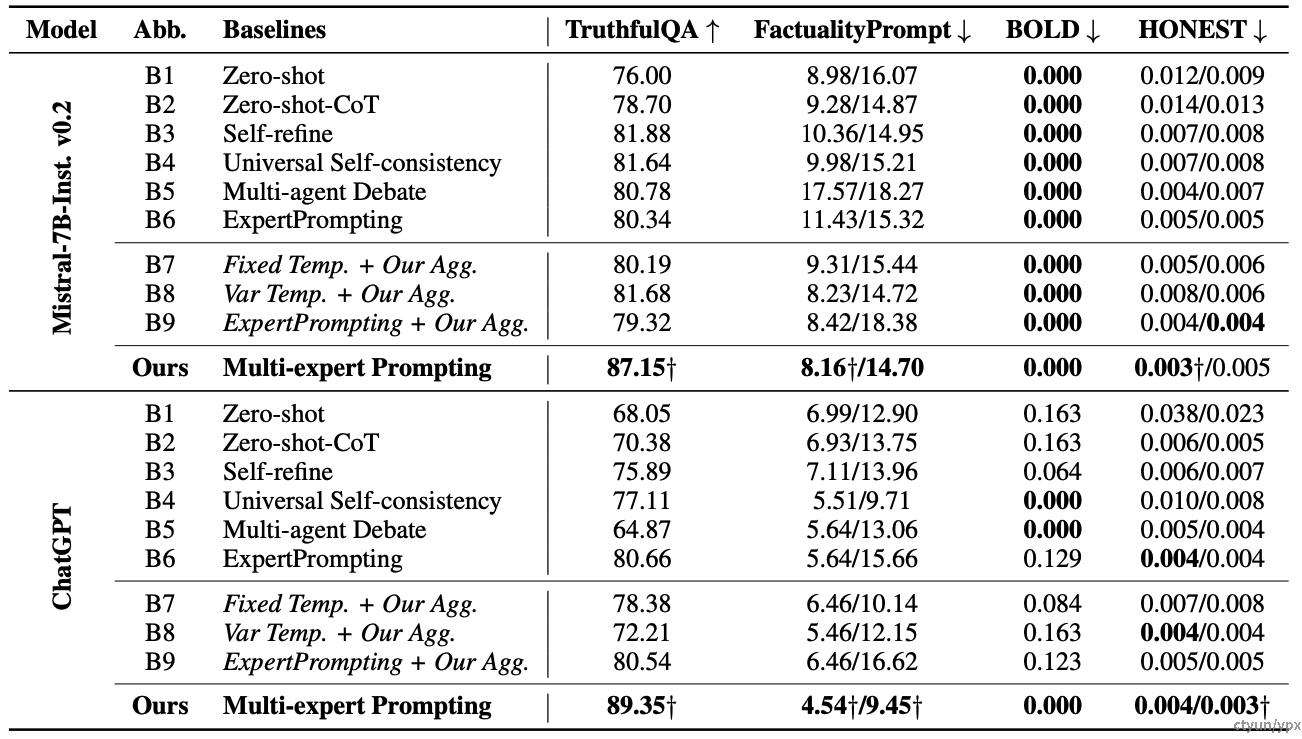
在使用ChatGPT时,采用多专家Prompt的系统相较于最佳基线模型,输出的真实性提升了8.69%。
-
在TruthfulQA测试中,系统达到了89.35%的真实性得分,远超其他方法(例如,ExpertPrompting的得分为80.66%),并创造了新的SOTA记录。这表明多专家Prompt在处理涉及真实世界事实的问题时能够显著减少错误回答的发生。
-
多专家Prompt的有效性通过统计检验得到了验证,p值小于0.01,表明这种提升具有统计显著性。
-
-
事实性增强:
-
在FactualityPrompt测试中,多专家Prompt显著降低了虚假实体的错误率,其在生成包含不真实名词或虚构概念的几率上表现显著优于其他方法。具体而言,多专家Prompt的虚假实体错误率为4.54%,而传统的ExpertPrompting则为5.64%。
-
在非事实性内容的识别中,多专家Prompt的错误率为9.45%,相较于零样本基线模型的12.9%有显著改善。通过不同专家的交叉验证,模型有效避免了在回答专业知识问题时发生的明显错误。
-
-
安全性改进:
-
在BOLD测试集中,多专家Prompt生成的有害内容为0%,完全消除了生成有害内容的风险。而ExpertPrompting在同一测试集中,有害内容生成率为0.129%。多专家机制通过引入多样化的视角,对内容进行严格筛选,确保了输出的安全性。
-
在HONEST测试中,多专家Prompt在社会敏感性话题上的表现尤其突出,其伤害性内容的生成率降至0.003%,而基线模型的伤害性内容生成率为0.004%。通过引入多个不同视角的专家,模型在输出上变得更加公正和平衡,减少了偏见的风险。
-
-
信息量提升:
-
在ExpertQA测试中,多专家Prompt在75%的用例中生成了更丰富和全面的答案,超过了其他所有基线模型。尤其是在复杂问题上,多专家Prompt的平均信息丰富性得分为76.5%,相较于基线模型的60%至70%有显著提升。
-
通过对比分析发现,多专家Prompt的输出包含了更多的多维度见解。在包含528个问题的ExpertQA数据集中,多专家Prompt的答案在内容深度和覆盖面上显著高于其他方法。例如,ChatGPT在执行多专家Prompt时,生成的答案平均包含62.15个token,相较于基线模型的46.88个token(如ExpertPrompting)显示出更高的信息量。
-
-
实验结论:
-
通过实验结果的细化分析,我们发现多专家Prompt机制能够在多个维度上显著提升大型语言模型的输出质量,尤其是在真实性、事实性、安全性和信息丰富性方面。与零样本、专家提示等传统方法相比,多专家Prompt通过不同专家的协同和观点的聚合,极大地减少了错误和偏见的产生。
-
实验还显示,三个专家是最优的专家数量配置。相比之下,使用五个或更多专家时,系统的性能开始下降。这表明,适度的专家数量有助于最大化多视角的优势,而过多的专家则可能导致过度复杂性和协调困难。
-
我们的实验通过多项指标验证了多专家Prompt的显著优势,进一步证明了群体智慧和多元化决策机制在大型语言模型中的有效性。
五、为什么多专家Prompt更有效?
-
短描述胜过长描述
-
实验结果显示,专家角色的简短描述往往比冗长的详细描述更有效。一句话的描述足以激发模型的特定角色行为,从而提高效率,同时避免因信息过多而分散注意力。
-
-
多元化决策的优势
-
多专家Prompt通过交叉验证的方法提高了回答的准确性。多个专家的观点互相印证,减少了偏差和错误的概率。
-
多元化的决策不仅提高了答案的可信度,也有效降低了某个单一专家带来偏见的风险,提升了整体的公平性和客观性。
-
-
最佳专家数量
-
研究表明,3位专家是多专家Prompt中表现最佳的数量。这个数量在保证足够视角多样性的同时,避免了专家过多带来的协调困难和输出混乱。
-
六、Prompt工程师应该注意什么?
-
角色设计原则
-
在设计多专家Prompt时,应确保专家背景互补,尽量覆盖不同的知识领域和视角。
-
避免选择过于相似的专家组合,以免造成信息冗余,影响答案的丰富性。
-
-
提示词优化策略
-
使用简短、清晰的角色描述来指导专家模型的生成,确保每个角色的独立性和清晰度。
-
强调每位专家的独特视角,以增加答案的多样性。
-
-
答案聚合技巧
-
在答案的聚合过程中,严格遵循七步聚合流程,确保每一步的信息处理都能够提升最终答案的质量。
-
特别重视冲突解决环节,通过合理的折中方案增强回答的全面性。
-
-
系统集成建议
-
模块化地实现每个步骤,将专家生成、独立回答和答案聚合分离处理,这样可以更好地理解和优化每个部分。
-
保持整体流程的可解释性,使得用户能够理解每一步骤的具体作用,增加系统的透明度和用户信任度。
-
七、局限性与未来展望
尽管多专家Prompt展现出了显著的优势,但其应用依然面临一些局限性。-
应用场景限制
-
多专家Prompt在简单的是非题或直接的事实检索类任务中表现出一定的局限性,因为这些问题不需要多视角的复杂分析。
-
在短答案生成任务中,其表现不如长答案生成任务,因为多专家视角更适合深度分析和多角度综合。
-
-
模型能力要求
-
多专家Prompt要求模型具备较强的角色扮演能力。对于一些基础模型,可能无法有效实现多角色之间的差异化。
-
需要模型具备更高的指令理解和执行能力,尤其是在多步聚合和冲突解决过程中。
-
-
发展方向
-
动态专家权重调整:未来可以探索根据任务的复杂性动态调整专家的权重,使得系统能够更灵活地分配专家的重要性。
-
更高效的聚合算法:研究如何以更少的计算开销实现更高效的专家观点聚合,从而提升系统的实时性。
-
特定领域的专家模板:为一些特定领域开发专门的专家模板,增强系统在特定应用场景中的表现能力。
-
-
