


2024年9月19日,阿里巴巴发布了最新一代大语言模型——通义千问2.5。这一升级不仅全面超越了其前身QWen2,更在多个关键指标上直面甚至超越了GPT-4和Claude等顶尖闭源模型,开源AI开始向闭源霸主发起挑战。本文将介绍千问2.5的核心特性,和其背后的技术创新。
本文整体结构如下:
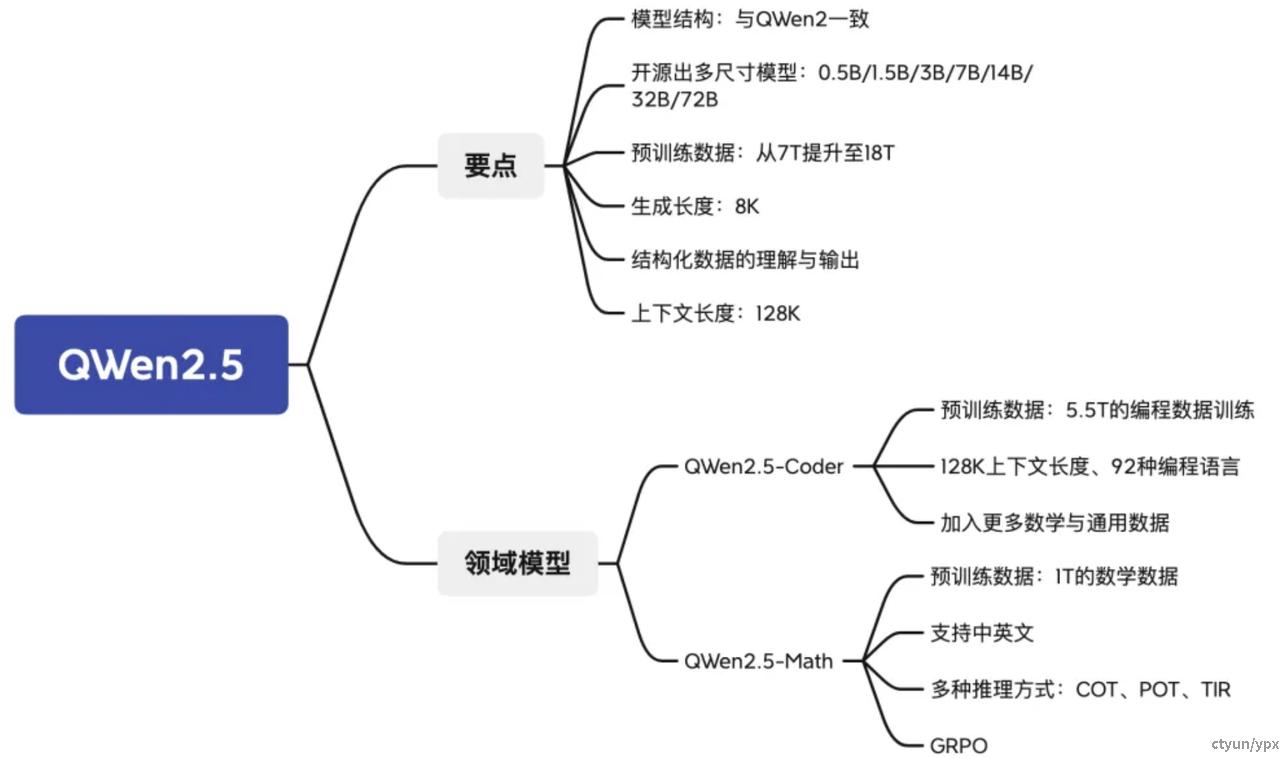
-
Qwen2.5:0.5B、1.5B、3B、7B、14B、32B和72B
-
Qwen2.5-Coder:专为编程设计的1.5B和7B模型
-
Qwen2.5-Math:专攻数学的1.5B、7B和72B模型
Qwen2.5
亮点
-
更大规模、更高质量的预数据训练集:预训练数据集规模从 7T tokens 扩展到了 18T tokens。
-
知识储备升级:Qwen2.5的知识涵盖更广。
-
代码能力增强:得益于Qwen2.5-Coder的突破,Qwen2.5在代码生成能力上也大幅提升。
-
数学能力提升:引入了Qwen2.5-math的技术后,Qwen2.5的数学推理表现也有了快速提升。
-
更符合人类偏好:Qwen2.5生成的内容更加贴近人类的偏好。
-
其他核心能力提升:Qwen2.5在 指令跟随、生成长文本(从1K升级到 8K tokens)、理解结构化数据(如表格),以及生成结构化输出(尤其是JSON)上都有非常明显的进步。此外,Qwen2.5能够更好响应多样化的系统提示,用户可以给模型设置 特定角色 或 自定义条件。
-
工具调用能力:全系列都很好的支持工具调用,如vllm / Ollama / transformers 这些推理框架。
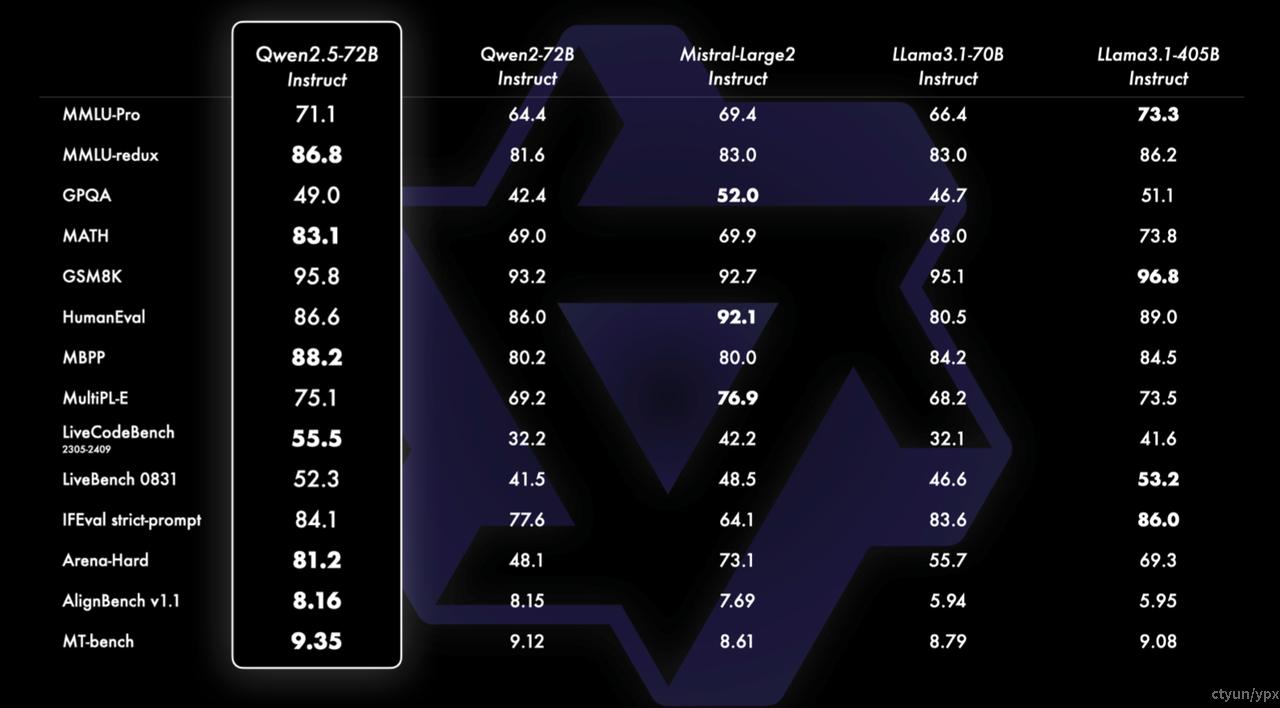
技术报告中展示了非常多 不同尺寸模型 的对比评测结果,我拿了其中一张图作为一个例子来在这展示一下
主要发现:
-
Qwen2.5-72B在多数任务上表现优于或接近Llama-3-405B,尽管参数量只有后者的1/5
-
Qwen2.5系列各规模模型(如32B, 14B, 7B)在多数任务上优于同等规模的竞争对手
-
在数学(MATH)和代码(LiveCodeBench)任务上,Qwen2.5系列表现尤为突出
-
在多语言任务中,Qwen2.5系列也展现出强劲的性能
-
较小规模的模型(如3B, 1.5B, 0.5B)相比前代也有显著提升,适合资源受限场景
根据QWen博客上晒出的榜单数据,本文将相同能力维度的评测集取平均,评测模型在不同能力上的表现:
-
专业知识:MMLU-Pro、MMLU-redux
-
逻辑推理:GPQA
-
数学能力:MATH、GSM8K
-
代码能力:HumanEval、MBPP、Multiple-E、LiveCodeBench
-
指令遵循:LiveBench、IFEval、AlignBench
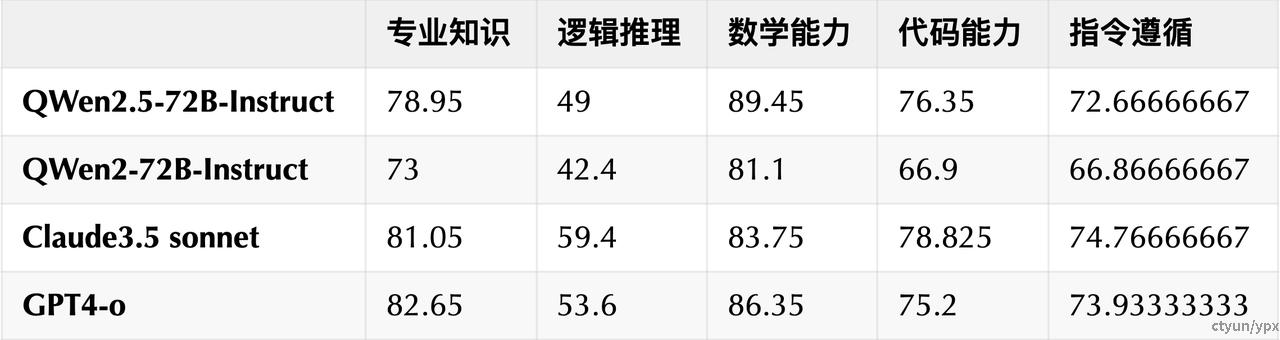
整体来说,Qwen2.5相较Qwen2在各项能力上均有显著提升。与业内领先模型相比,Qwen2.5在数学能力上超越GPT-4和Claude,在代码能力、指令遵循和专业知识方面差距缩小,但复杂逻辑推理仍有较大差距。
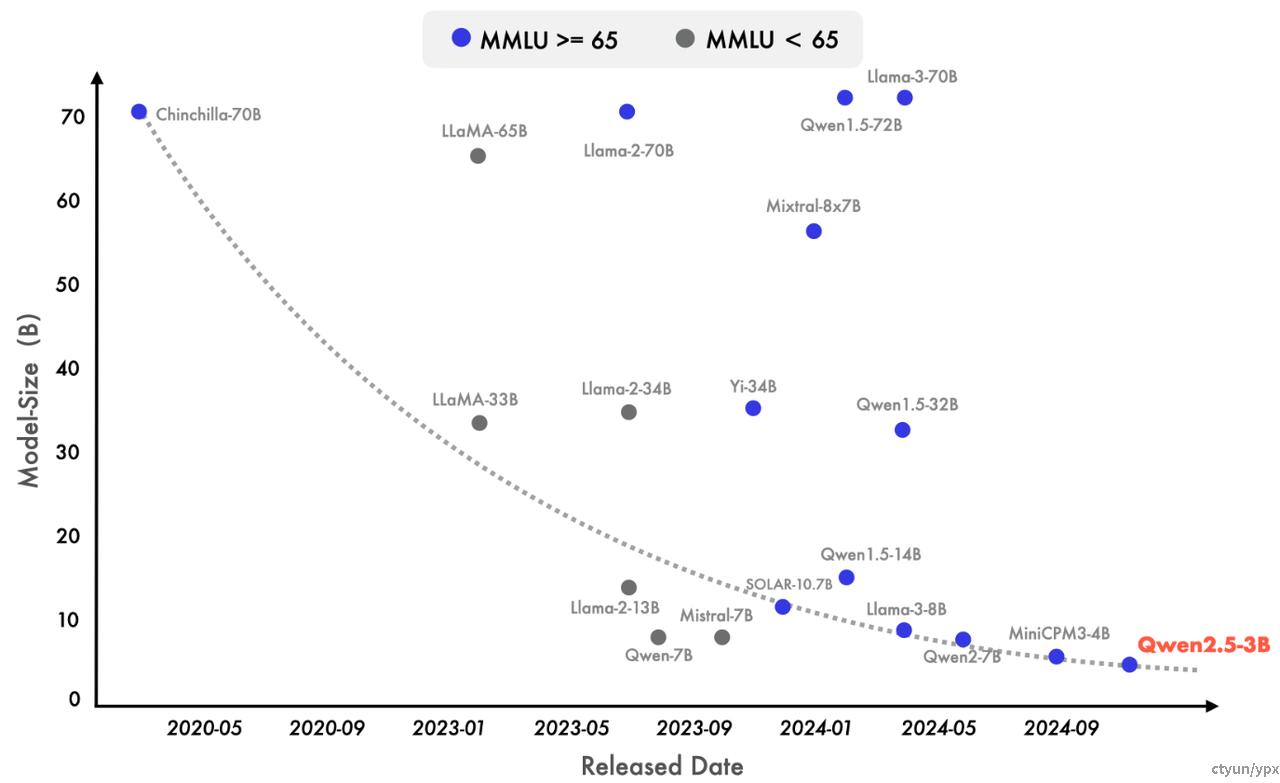
近来也出现了明显的转向小型语言模型(SLMs)的趋势。尽管历史上小型语言模型(SLMs)的表现一直落后于大型语言模型(LLMs),但二者之间的性能差距正在迅速缩小。值得注意的是,即使是只有大约 30 亿参数的模型现在也能取得高度竞争力的结果。附图显示了一个重要的趋势:在 MMLU 中得分超过 65 的新型模型参数规模正变得越来越小,这凸显了语言模型的知识密度增长速度加快。特别值得一提的是,我们的 Qwen2.5-3B 成为这一趋势的一个典型例子,它仅凭约 30 亿参数就实现了优越的性能。
下面我们再来看一下QWen2.5的模型结构与模型特色,以及这些特色的实现方式。
模型结构
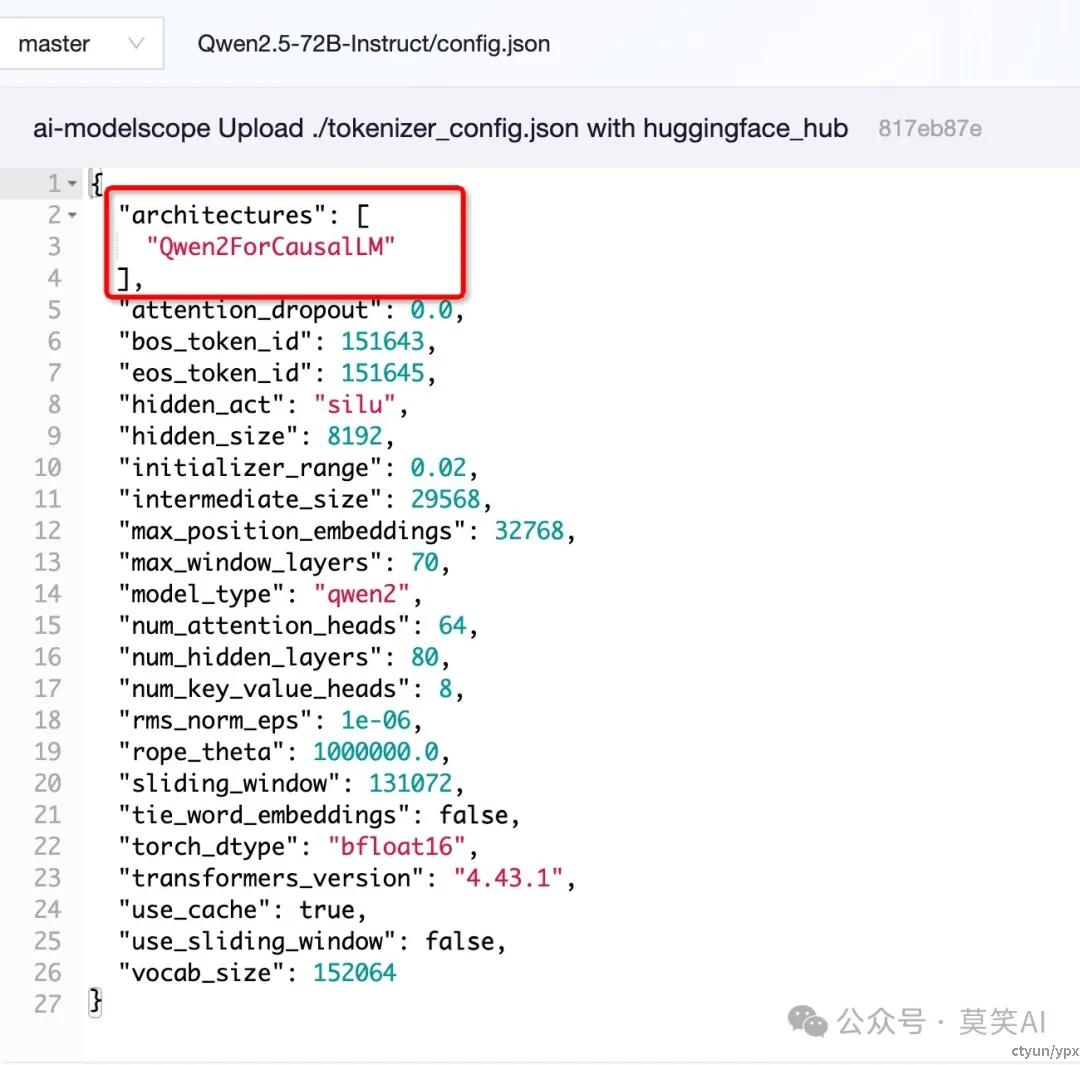
从开放出的模型config文件可以看到,QWen2.5的结构与QWen2的结构是保持一致的:
长文本生成
QWen2.5支持长达8K的文本生成,那么这项技术是如何实现的呢?这就需要关联到GLM团队放出的LongWriter论文:《LongWriter: Unleashing 10,000+ Word Generation from Long Context LLMs》
该论文发现当前最先进的大模型在面对长文本输出的指令要求时,输出长度均不超过2K:
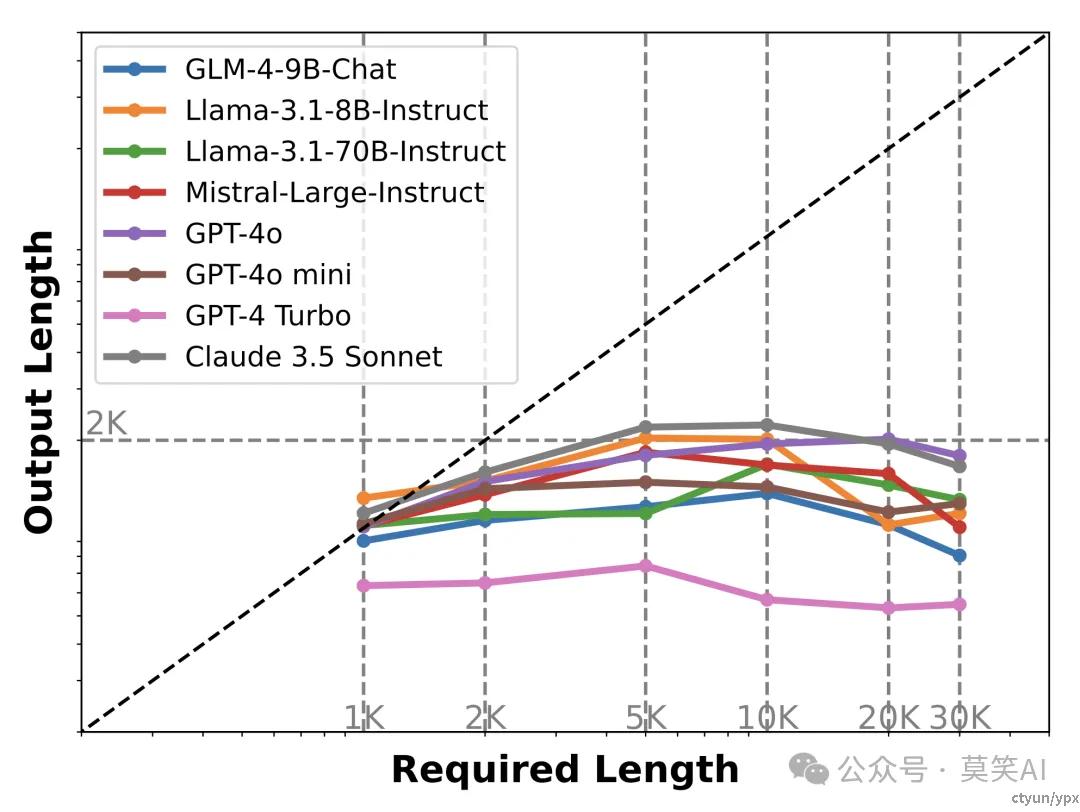
论文中关于该现象的结论是:尽管长文本模型在预训练阶段接触了更长的文本序列,但其最大生成长度实际上被 SFT 数据集中输出长度的上限所限制。换句话说,模型“读”到的内容决定了它能“写”多长。
GLM团队因此设计了一个名为AgentWrite的 pipeline,通过分解长生成任务,让现有模型来生成更长的 具备连贯性的输出。具体来说,以下图为例:
-
首先,会根据用户的输入生成一个详细的写作计划,包括每段内容的结构和目标字数
-
其次,模型依次完成每个子任务,并将生成的段落串联起来,最终形成完整的长文本输出。
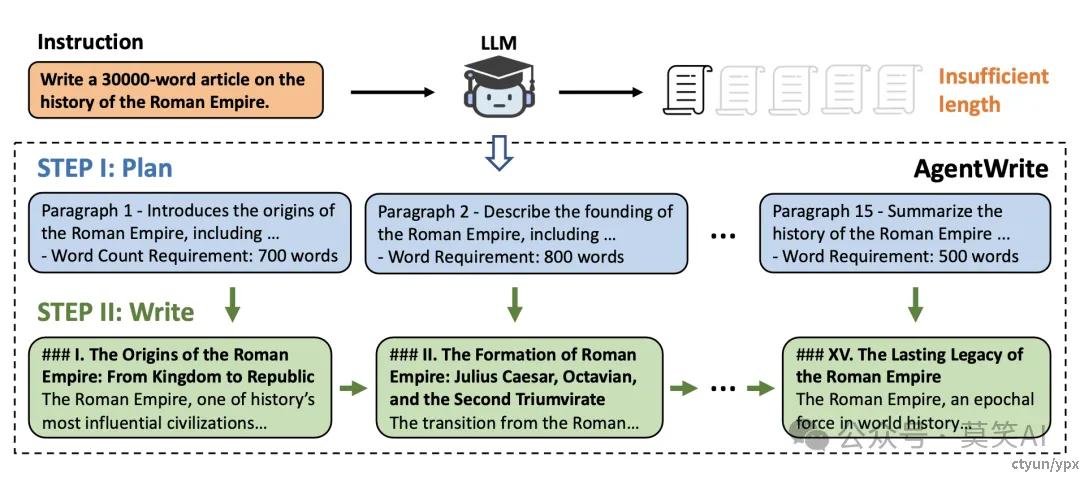
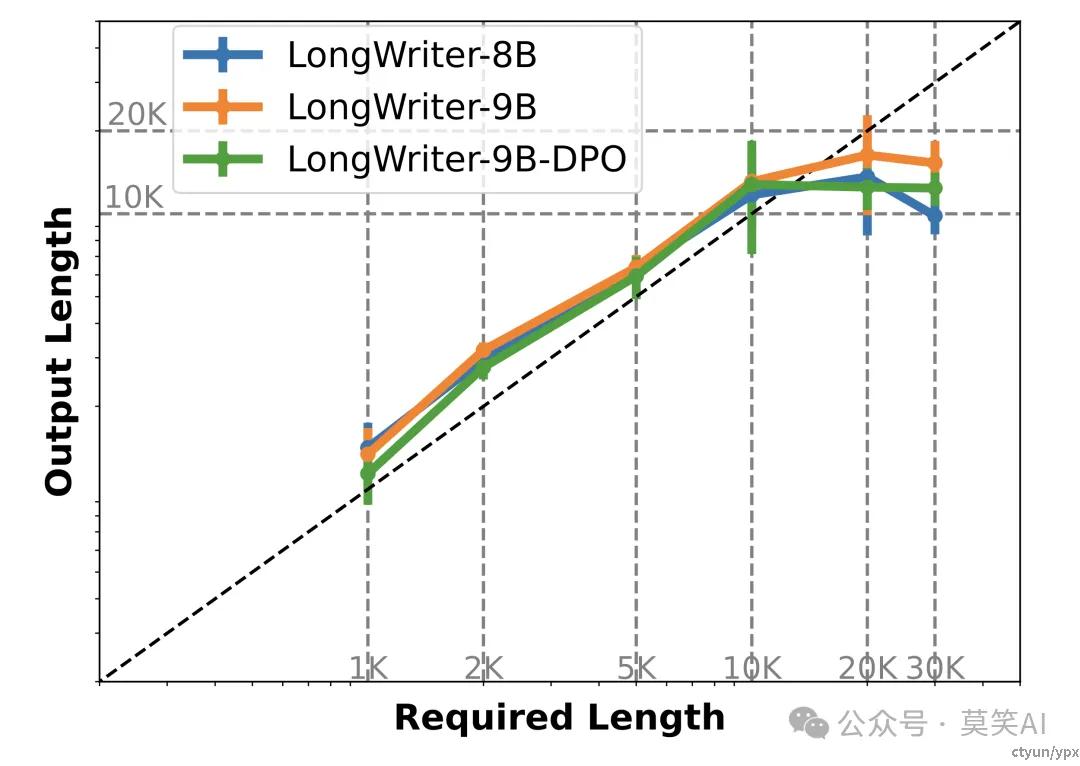
如下图所示,通过这种方法,AgentWrite 能够生成超过 20,000 字的高质量文本。
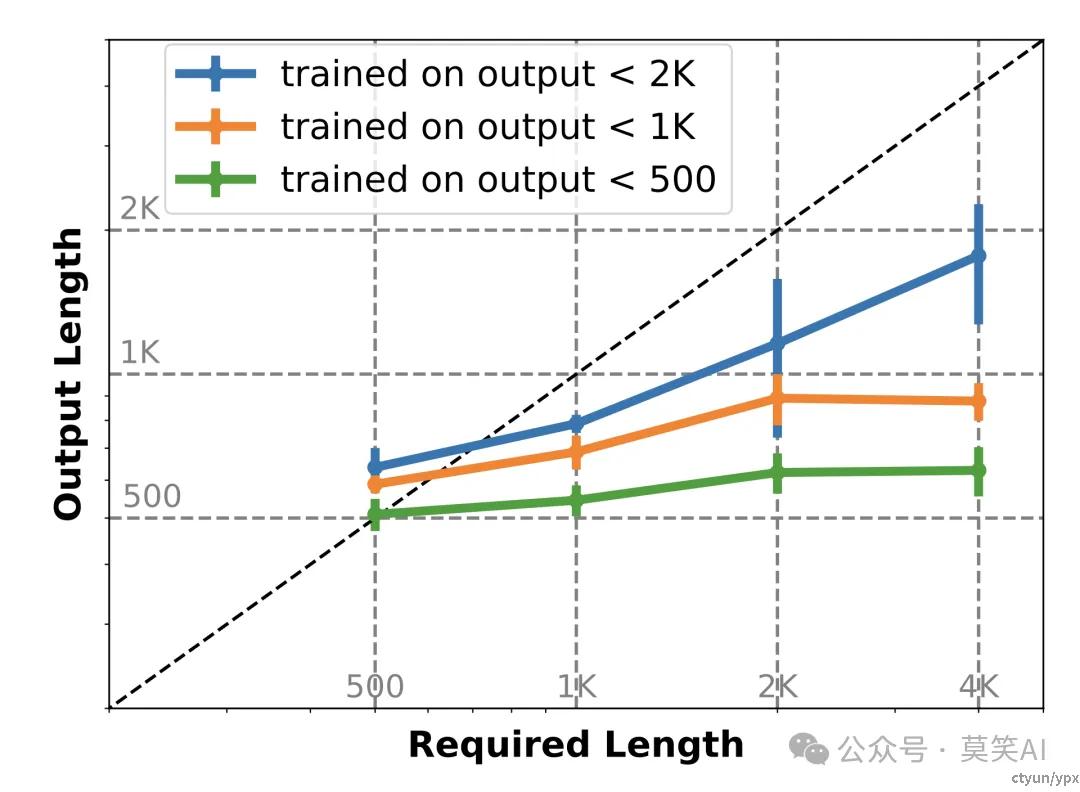
最终通过在该数据集上的SFT与DPO有效提升了模型的输出质量与长文本生成中遵循长度要求的能力:
QWen2.5-Coder
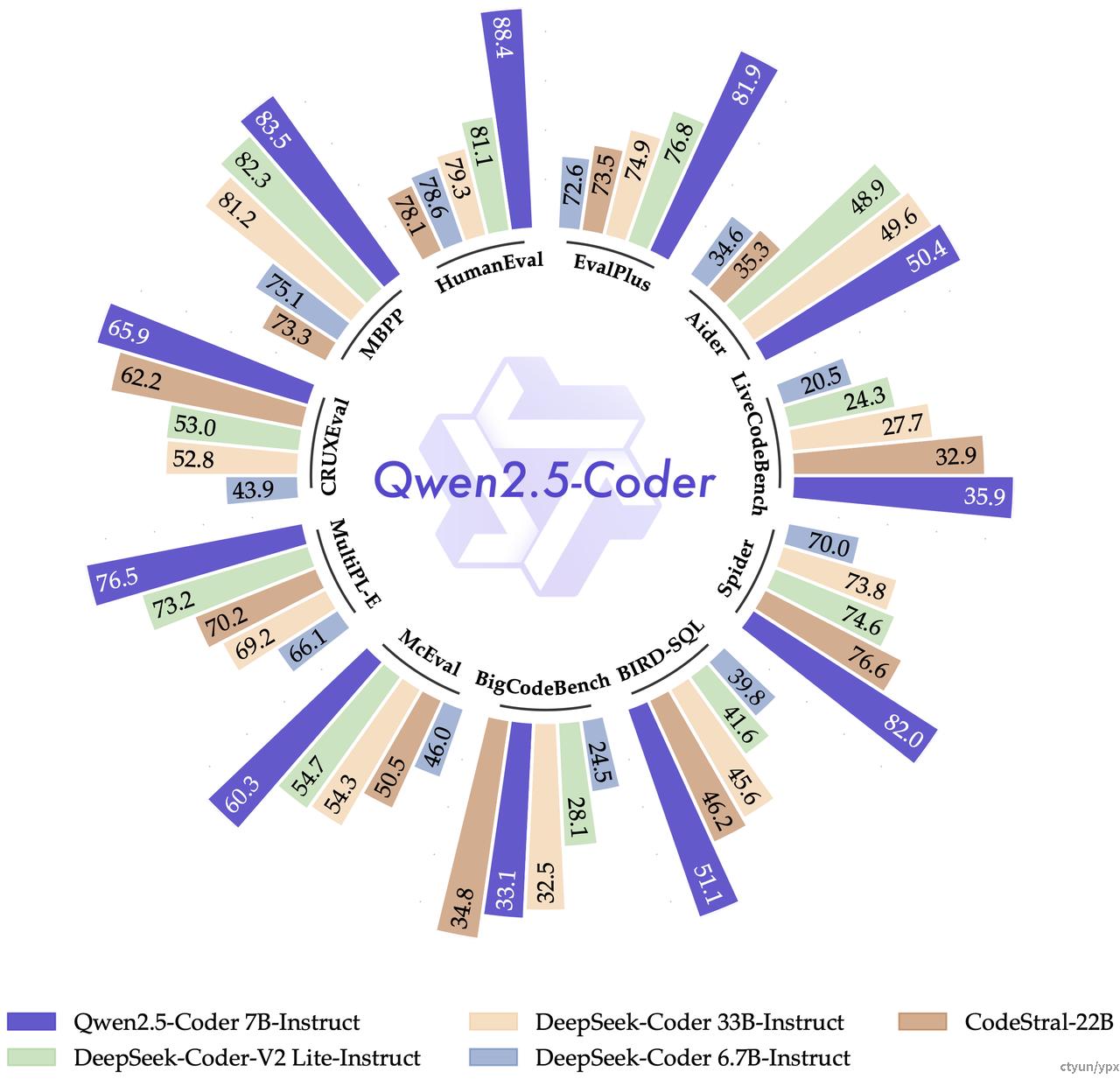
Qwen2.5-Coder 最多 128K tokens 上下文,支持 92 种编程语言,并在多个代码相关的评估任务中都取得了显著的提升,包括代码生成、多编程语言代码生成、代码补全、代码修复等。值得注意的是,本次开源的 7B 版本 Qwen2.5-Coder,甚至打败了更大尺寸的 DeepSeek-Coder-V2-Lite 和 Codestral-20B,成为当前最强大的基础代码模型之一。
其中Qwen2.5-Coder的核心点包括代码训练数据的进一步扩展,以及探索在提升代码能力的同时保持数学和通用能力。
-
码无止境:Qwen2.5-Coder 基于强大的 Qwen2.5 初始化,扩增了更大规模的代码训练数据持续训练,包括源代码、文本代码混合数据、合成数据等共计 5.5T tokens。使得 Qwen2.5-Coder 在代码生成、代码推理、代码修复等任务上都有了显著提升。
-
学无止境:希望 Qwen2.5-Coder 在提升代码能力的同时,也能保持在数学、通用能力等方面的优势。因此,我们在 Qwen2.5-Coder 中加入了更多的数学、通用能力数据,为未来的真实应用提供更为全面的基座。
QWen2.5-Math
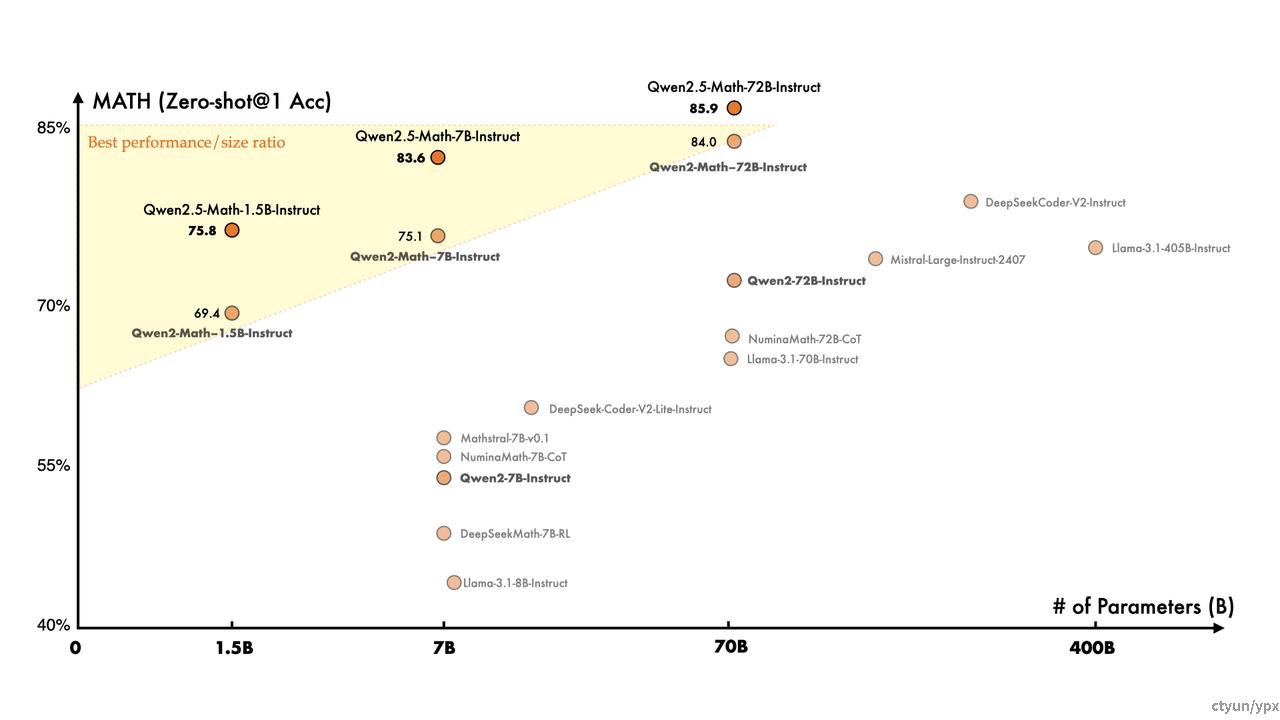
Qwen2.5-Math系列在中文和英文的数学解题能力上均实现了显著提升。并且同时支持使用思维链和工具集成推理(TIR) 解决中英双语的数学题。
相比于 Qwen2.5-Coder 的技术报告,Qwen2.5-Math 的技术报告多了一个副标题:“Toward Mathematical Expert Model via Self-Improvement”,可以看出,这是一个贯穿整个 Qwen2.5-Math 训练流程的重要方法论——自我改进(Self-Improvement)。在摘要中, Qwen 团队也提到,自我改进主要体现在三个方面:
-
Pre-training:用 Qwen2-Math-Instruct 来合成扩充预训练数据
-
Post-training:SFT 模型和奖励模型之间的交互迭代
-
Inference:奖励模型用于指导采样
总结:
QWen2.5在保持与前代一致结构的基础上,创新性地引入了专用工具调用模板,大幅提升了结构化数据的处理能力。模型经过18T数据的深度训练,输出长度扩展至8K,综合性能显著增强。
在垂直领域,QWen2.5-Coder模型通过5.5T代码数据的训练,实现了对92种编程语言的高效支持,同时保留了卓越的数学和通用推理能力。而QWen2.5-Math模型更是突破性地超越多个闭源对手,凭借1T高质量数学数据的训练,结合COT和TIR等先进技术,在数学领域展现出了非凡的表现。
