



《A Survey of Attacks on Large Vision - Language Models: Resources, Advances, and Future Trends》
论文地址:https://arxiv.org/pdf/2407.07403
代码:https://github.com/liudaizong/Awesome-LVLM-Attack
1. 研究背景
大型视觉-语言模型LVLMs通过结合视觉信息处理和自然语言理解的能力,在多种任务中展现出了卓越的性能。然而,随着模型规模的增大和部署的广泛性,LVLMs的安全性问题也日益突出。本文旨在提供对现有LVLMs攻击方法的全面概述,并探讨未来的研究方向。
2. LVLM攻击
基于以下下分类方法进行分类:
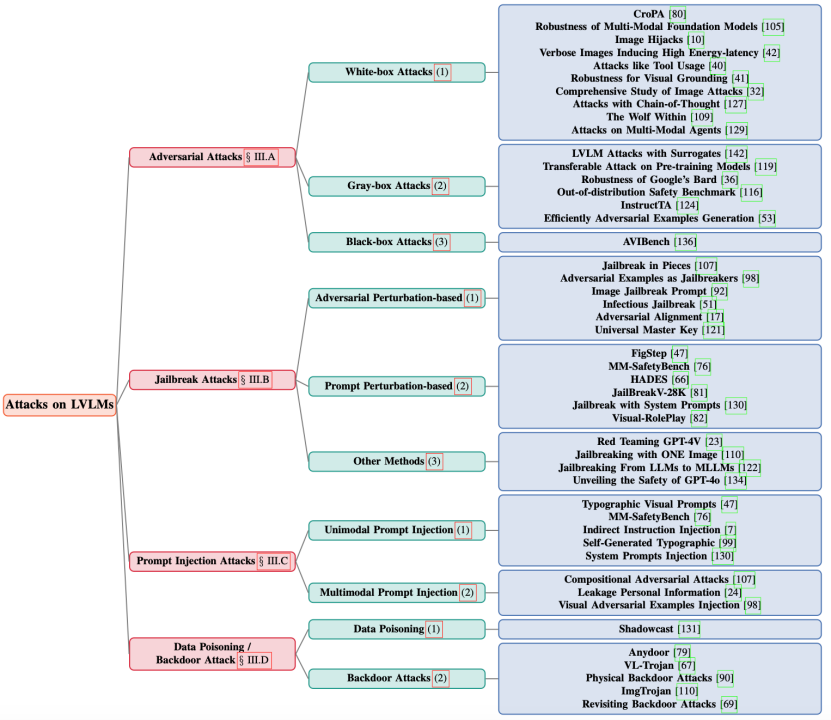
2.1 攻击流程
攻击目标是找到对图像和文本的攻击操作,使模型产生不正确或攻击者指定的输出,对于越狱和提示注入攻击,要使模型输出特定或越狱文本;对于对抗攻击,通过解决优化问题来生成扰动。
2.2 攻击面临的挑战
包括多模态复杂性、模型可扩展性、攻击实用性、攻击不可感知性和可转移性、可解释性和对防御的鲁棒性。
2.2.1多模态复杂性(Multimodal Complexity):LVLMs需要处理和整合来自多个模态(如图像和文本)的数据。这要求攻击者不仅要理解单个模态的攻击方式,还要掌握如何有效地操纵和利用多模态数据之间的复杂交互关系。
2.2.2模型可扩展性(Model Scalability):LVLMs通常涉及大规模的架构,包含数百万参数,这使得它们在计算上非常复杂和资源密集。攻击这类模型需要大量的计算资源和高效的优化技术。
2.2.3攻击实用性(Attack Practicality):在现实世界的应用中,LVLMs通常以黑盒或灰盒的形式部署,这意味着攻击者无法访问模型的内部细节。因此,攻击者需要开发能够在有限信息下有效实施的攻击策略。
2.2.4攻击隐蔽性和可转移性(Attack Imperceptibility and Transferability):高质量的攻击应该能够欺骗人类或机器的感知,同时保持良性样本的语义特征,以提高隐蔽性。此外,攻击应该能够在不同的模型和任务之间转移,这要求攻击方法具有一定程度的通用性和适应性。
2.2.5可解释性和可解释的攻击(Interpretable and Explainable Attacks):为了真正有效,攻击者需要理解LVLMs的内部工作机制和决策过程。然而,许多LVLMs的黑盒特性和复杂性使得理解和解释攻击成功或失败的原因变得困难。
2.2.6对防御的鲁棒性(Robustness to Defenses):许多LVLMs采用了动态防御机制,能够适应检测到的对抗性活动。这些防御可能包括实时监控、异常检测和自适应再训练。因此,攻击策略需要不断进化以保持领先于这些自适应防御,这需要大量的计算资源和复杂的算法。
2.3 当前LVLM攻击资源
- 白盒攻击工具:对模型架构、参数和梯度有完全访问。使用如Fast Gradient Sign Method(FGSM)、Projected Gradient Descent(PGD)、C&W Attack等。
- 灰盒攻击工具:攻击者对模型有部分了解,比如架构或一些内部参数,但不能完全访问模型的权重或完整的训练数据。使用其他视觉/语言编码器或生成模型作为代理模型。
- 黑盒攻击工具:如Simple Black - box Attack(SimBA),使用简单的随机搜索方法对输入图像添加扰动,它会评估这些扰动对模型输出的影响,如果它们增加了损失就接受它们。Random Gradient - Free(RGF),通过对输入空间中的随机方向进行采样,并根据模型的输出差异估计期望梯度来逼近梯度,然后,它使用这个估计的梯度来执行对抗性攻击。Query - Limited Black - Box Attacks,侧重于最小化对目标模型的查询数量,它的主要技术包括利用替代模型、迁移学习和高效采样方法。
- 数据集:分为一般任务数据集和安全相关数据集。一般任务数据集与标准视觉任务相关联,如对象检测和视觉问答,它们通常由带注释的图像或图像-问答对组成,用于生成对抗样本。安全相关数据集通常与大模型的安全性有关,例如越狱攻击和提示注入攻击中使用的数据集,在与安全相关的场景中,它们通常包含许多带有毒性注释、纯有害提示、或文本-图像对的提示,其用于攻击。许多工作还利用生成式大模型构建数据集。
- LVLM模型:攻击者通常选择具有代表性的LVLM模型进行攻击,如Flamingo、BLIP - 2、InstructBLIP等,一个LVLM模型通常由视觉编码器、适配器和LLM骨干组成。
- 评估指标:使用攻击成功率(ASR)评估攻击效果,具体含义和计算方法因任务和攻击目标而异,还包括Contain(模型的输出包含攻击者特定的内容)、Exactmatch(模型的输出完全匹配攻击目标)等指标,以及人类评估、基于规则的评估和基于模型的评估等方法。
- 防御策略:分为推理时防御和训练时防御,如prompt engineering、JailGuard、ECSO、使用鲁棒的自然语言反馈或提示等。
3.攻击技术方案及评估比较
|
攻击方法 |
技术方案 |
评估比较 |
|
对抗攻击(Adversarial Attacks) |
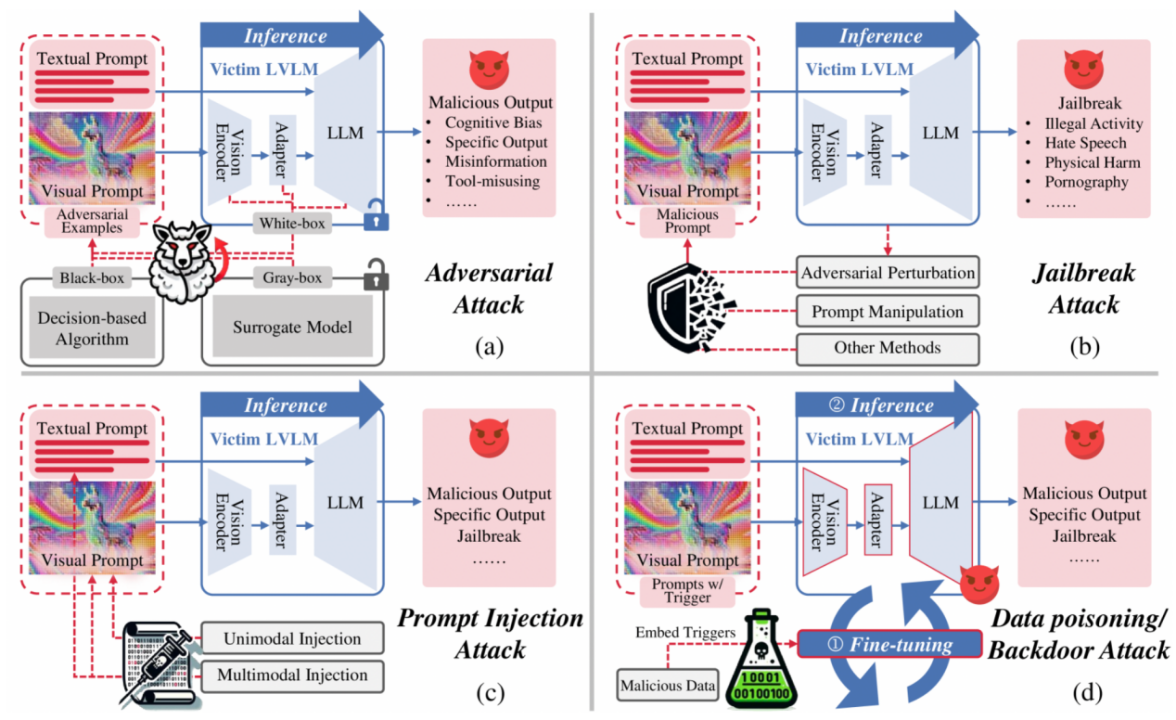
- 白盒攻击:利用对模型架构、参数和梯度的完全访问,使用梯度工具如PGD、APGD和CW等在图像和文本输入中生成和优化噪声,以诱导模型产生错误或不理想的输出。例如,通过有目标攻击使模型产生预定输出,或通过无目标攻击降低输出质量。 - 灰盒攻击:攻击者具有部分模型知识,通常以其他视觉/语言编码器或生成模型作为代理模型生成对抗样本,然后转移攻击LVLMs。这些方法通过匹配特征/嵌入来生成对抗语义或隐藏噪声,以增强攻击的不可感知性。 - 黑盒攻击:在无法访问模型架构或参数的情况下,通过一些基准评估来测试模型对对抗性视觉指令的鲁棒性。例如,使用简单的随机搜索方法添加扰动或通过估计梯度来进行攻击。 |
- 白盒攻击:能够充分利用模型的信息,生成高度有效的对抗样本,但在实际应用中,攻击者通常难以获得对模型的完全访问权限。 - 灰盒攻击:在一定程度上平衡了攻击效果和实际可行性,通过使用代理模型可以生成具有一定攻击性的样本,但可能不如白盒攻击那么精确。 - 黑盒攻击:更具现实意义,因为在许多情况下攻击者无法了解模型的内部结构,但攻击效果可能相对较弱,需要更多的尝试和优化。 |
|
越狱攻击(Jailbreak Attacks) |
- 基于对抗扰动的攻击:通过构建对抗图像或文本绕过模型的内部对齐机制,使用梯度工具迭代更新对抗噪声,以诱导模型产生有害内容。例如,利用连续域图像作为对抗提示或优化对抗图像前缀和文本后缀来实现越狱。 - 基于提示操纵的攻击:在视觉或文本提示中操纵数据,通过排版等方式将恶意语义直接注入输入数据,以降低模型对有毒输入的敏感性或伪装有毒查询为无害输入,从而规避模型的安全对齐。 - 其他方法:包括类似于数据中毒的越狱攻击范式,如在训练数据中引入中毒图像或文本对,以及构建综合越狱评估数据集来评估现有越狱方法的迁移能力等。 |
- 基于对抗扰动的攻击:直接针对模型的内部对齐机制进行攻击,能够有效地突破模型的限制,但需要精心构建对抗样本。 - 基于提示操纵的攻击:通过操纵提示来规避模型的安全对齐,相对较为隐蔽,但可能需要对模型的输入处理机制有深入了解。 - 其他方法:如数据中毒式的越狱攻击,具有一定的创新性,但可能需要在特定的场景下才能发挥作用。 |
|
提示注入攻击(Prompt Injection Attacks) |
- 单模态提示注入:将恶意指令注入到单个模态(视觉或文本)的输入中,例如通过将对抗性扰动融入带有提示和指令的图像中,或使用排版来转换有毒文本以注入视觉提示。 - 多模态提示注入:同时影响文本和视觉模态,将恶意语义注入多个模态以协同增强绕过对齐障碍的可能性,例如通过组合来自视觉和文本模态的对抗性噪声并在嵌入域中实施恶意注入,或构建文本和视觉提示注入攻击来诱导模型披露受保护的个人信息。 |
- 单模态提示注入:实施相对简单,但其攻击效果可能受到模态的限制。 - 多模态提示注入:能够同时利用多个模态的信息,增强了攻击的威力和绕过对齐障碍的能力,但也增加了攻击的复杂性。 |
|
数据投毒/后门攻击(Data Poisoning/Backdoor Attacks) |
- 数据投毒:将恶意数据引入微调/RLHF数据集,导致LVLM学习错误参数并在后续推理中产生错误。 - 后门攻击:利用数据中毒嵌入恶意触发器,然后激活以引发特定的有害行为,例如在文本模态中使用对抗性测试图像注入后门,或通过隔离和聚类策略促进图像触发学习并生成文本触发以提高攻击在不同模型上的可转移性,还包括展示针对特定自动驾驶任务的后门攻击以及对后门攻击在LLM指令调优中的泛化性的实证研究。 |
- 数据投毒:可以在模型训练阶段就植入恶意样本,对模型的影响较为深远,但需要对训练数据有一定的控制能力。 - 后门攻击:能够在特定条件下触发恶意行为,具有较强的隐蔽性,但需要精心设计恶意触发器。 |
4.未来方向
① 提高攻击实用性:设计通用扰动,通过查询LVLM模型进行梯度估计,以适应不同任务和模型的攻击。应用以前基于图像的策略到多模态任务中,通过对抗训练通用扰动来提高攻击的实用性。
② 自适应和可转移攻击:使攻击更少依赖特定受害者网络,更好地推广到不同网络。采用集成学习的方法,同时学习攻击多个LVLM模型,或适当调整基于图像的提高对抗样本可转移性的策略到LVLM模型中。
③ 跨模态对抗样本:探索同时扰动视觉和文本输入的新方法,研究模态之间的相互作用和依赖关系,以创建更有效的跨模态攻击。利用多键策略或多模态对比学习来增强多模态扰动之间的关系。
④ 基于数据偏差的攻击:关注LVLM对训练数据偏差的继承和放大,发展偏差放大攻击和潜意识操纵攻击等方法。研究如何通过有针对性的操纵输入来放大训练数据中的偏差,以突出和加剧模型的固有弱点。
⑤ 人类和AI协作攻击:探索人类 - AI协同攻击策略,将人类专业知识与AI工具相结合,开发框架使人类攻击者能够在AI工具的协助下迭代优化对抗输入。同时,研究社会工程和操纵技术,基于社会背景或用户行为构建操纵输入,以欺骗模型及其用户。
⑥ 综合基准测试和评估:开发标准化攻击基准、持续评估框架、综合攻击分类法以及鲁棒性指标和评估标准,以全面评估LVLM模型的鲁棒性和安全性。
