


1. 引言
1.1 传统关系型数据库查询执行器
查询执行器的输入是优化器选择好的最优物理查询计划,主要告诉应该按照一个什么样的顺序和步骤去执行这个查询语句的物理查询计划,并将查询结果返回给用户,主要负责 SELECT,DML,权限检查,触发器,表达式计算等工作,一般由多种算子组成,不同算子实现不同的功能,就像CPU一样,由很多种汇编指令组成,每种汇编指令完成一种操作,例如PostgreSql数据库中常见的算子有顺序扫描算子seqscan,索引扫描算子indexscan,连接算子hashjoin,nestloop,mergejoin,聚集算子hashagg,groupagg,排序算子sort,集合算子union等。而执行器按照物理查询计划树自上而下驱动流水线,而数据自下而上的返回,深度遍历查询计划树,每次返回一条数据,如果支持矢量化,每次将返回一批数据,每个算子都有一套自己的模型实现,都有相应的Open函数,初始化执行状态,分配内存,GetNext函数,根据方向返回下一条输出结果,Close函数关闭执行状态,释放资源。那么这种流水式的迭代模型有什么优点呢??(1)低延迟,快速的返回第一行数据 (2)可能不需要完成整个执行过程,如in,limit,cursor操作等 (3)占用很少 的内存资源,非流水通常需要物化。 有什么缺点呢??性能低,无法发挥 CPU 的并行能力,对于 OLTP 低延迟来说足够,对于计算密集的 OLAP 来说是远远不够的,CPU 不到 100% 就是犯罪!
1.2 ClickHouse查询执行器
执行器的主要作用是执行物理查询计划,并将生成的查询结果写入到Socket输出缓冲区,等待发送给客户端。ClickHouse查询优化器生成Pipeline物理查询计划,查询explain pipeline select * from t2 where tc2=2 and tc3=3;(max_threads=2)的查询物理执行计划如下:
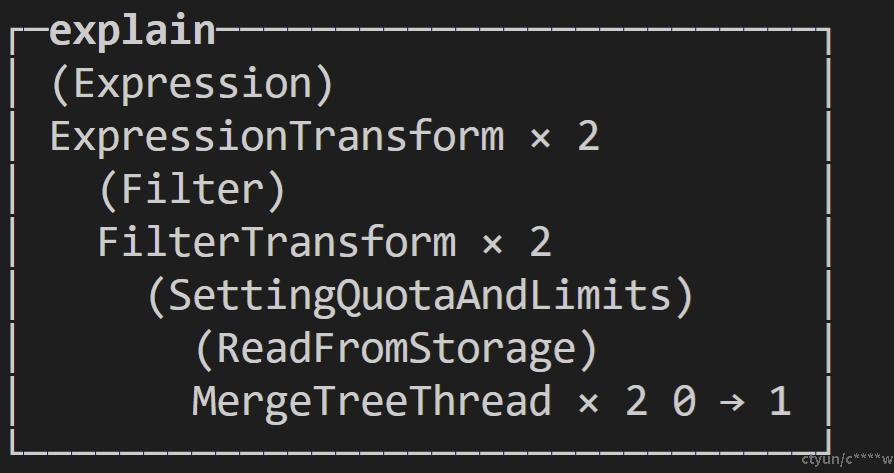
将物理查询计划以有向无环图的形式展示:

物理查询计划中,每一步查询计划对应的处理者就相当于传统数据库的算子,但针对表达式的计算,ClickHouse中单独作为一个查询步骤,例子中在传统数据库中由seqscan算子完成,而在ClickHouse中由三步进行完成,每一步有2个处理者,可以并行处理,每个处理者processor都有自己的work()函数和prepare()函数,work()函数负责处理Chunk,prepare()函数负责推拉数据,数据及状态的传递,数据在不同的处理者间层层传递,形成流水的模式,一次一个Chunk,多条数据。ClickHouse执行器的好处就是让CPU跑满, 流水式的矢量化执行,每次返回多条数据,这才是精华所在。
ClickHouse中根据查询种类的不同,将调用不同的处理函数:处理insert Query时调用processInsertQuery;处理并发查询调用processOrdinaryQueryWithProcessors;处理单线程查询调用processOrdinaryQuery。
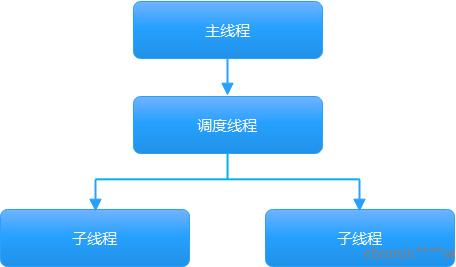
以select * from t2 where tc2=2 and tc3=3(max_threads=2)为例,其查询执行器入口函数为processOrdinaryQueryWithProcessors,执行过程由三种类型的线程共同完成,分别为主线程、调度线程和子线程,子线程的个数一般由参数max_threads控制。以max_threas=2为例,线程间的关系如下图所示:
2. 主线程
输入:QueryPipeline物理查询计划。
输出:与client交互,发送数据Block。
以简单查询select * from t2 where tc2=2 and tc3=3;为例,其入口函数为processOrdinaryQueryWithProcessors。
2.1 实现流程
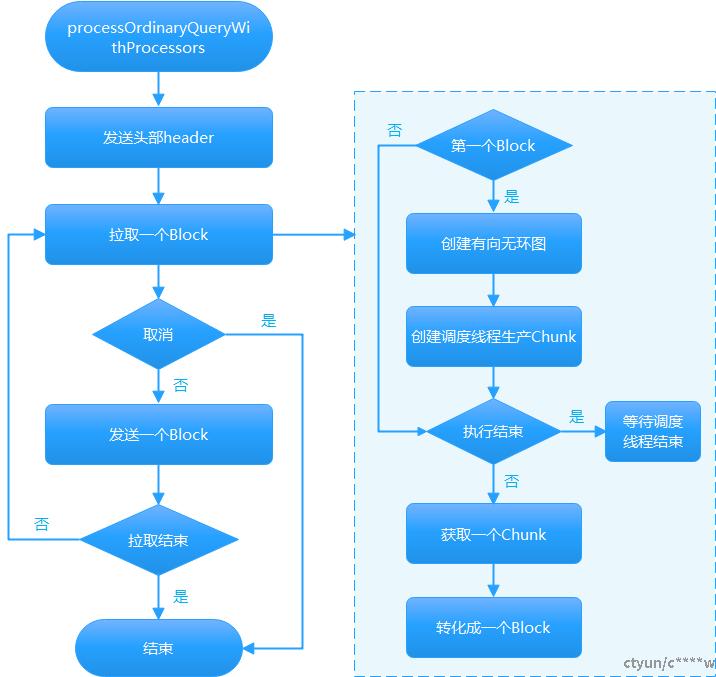
2.2 流程描述
- 调用函数sendData(header)发送头部信息,一般包括列名描述等。
- 循环调用Executor.pull(block,interactive_delay/1000)拉取一个Block,如果一定时间内拉取不到,认为超时,报错结束查询。拉取第一个Block时,根据QueryPipeline.processors创建有向无环图,创建调度线程去创建子线程生产Chunk,放到全局队列ConcurrentBoundedQueue queue。主线程每次从queue里获取一个Chunk,并转化为Block,就是将Chunk里的列数据,列名,列类型重新指向一下。当执行结束时等待调度线程结束。
- 如果client取消查询,则停止发送取消查询,等待调度线程结束。
- 如果Block不为null格式,调用sendData(block)发送给client。
2.3 与调度线程交互过程
- 正常结束时,等待调度线程结束。
- client取消查询时,取消每个processor,并等待调度线程结束。
- 出错时,子线程错误抛给调度线程,调度线程返回给主线程,调度线程结束,主线程抛出错误。
2.4 创建有向无环图实现流程
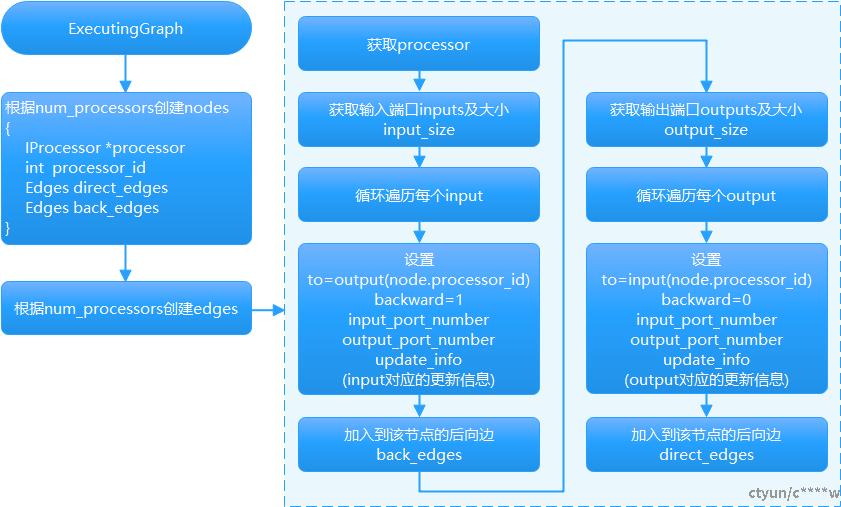
简单查询select * from t2 where tc2=2 and tc3=3 and tc4=4;物理查询计划的有向无环图(set max_threads=2)如下图所示:

注释:
id:processor_id处理者编号,outport:0,0:输出端口编号,版本号,inputport:0,0:输入端口编号,版本号。每个input/outport都有版本号version,outport指向的称为前向边(outport->inputport),版本号与outport一致,inport指向的称为后向边(inputport->outport),版本号与inport一致。LazyOutPutFormat处理者有三个输入端口,没有输出端口,因enum PortKind { Main = 0, Totals = 1,Extremes = 2 };数据输出顺序是main input,然后totals,然后extremes,默认情况下,totals,extremes为null,生成了NullSource处理者。
3. 调度线程
调度线程主要用来创建子线程,初始化子线程间共享的一些的结构,并等待子线程的结束。
入口函数:threadFunction()。
主要执行函数:PipelineExecutor::executeImpl(size_tnum_threads)。
输入:PullingAsyncPipelineExecutor::Data &data 主线程初始化,存放状态标志
ThreadGroupStatusPtr thread_group对应线程组,一个query对应一个num_threads线程总数,一般由max_threads决定。
输出:执行结束标志,执行出错标志(主线程获取标志后进行处理)。
3.1 实现流程
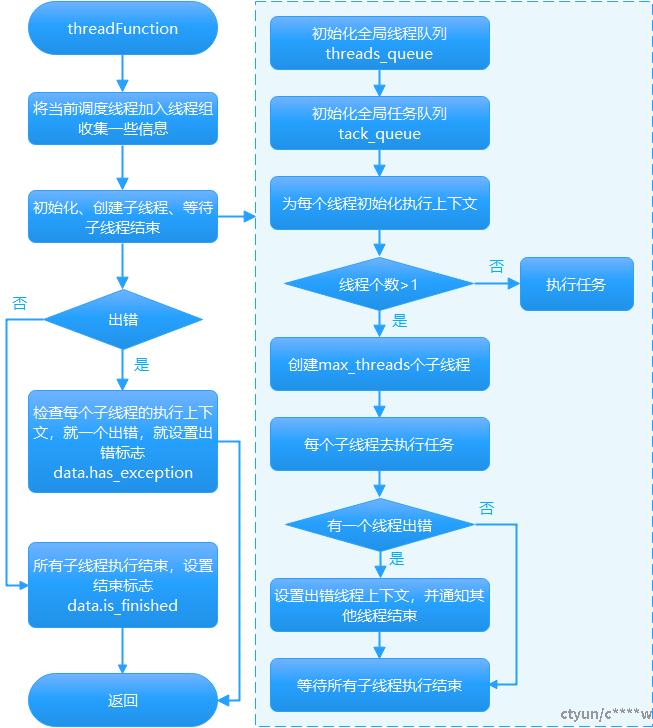
3.2 流程描述
- 将当前调度线程加入线程组,一个查询对应一个线程组,目的是跟踪,收集查询信息。
- 调用executeImpl(num_threads),进行初始化工作,包括全局任务队列task_queue,全局线程队列threads_queue,如果num_threads>1,则创建多个子线程同时去执行任务,并等待子线程结束。如果num_threads=1,则直接去执行任务。全局任务队列task_queue是个数组,数组下标就是子线程编号,每个子线程对应一个任务队列,一个任务就是有向无环图中的一个node。其中,全局线程队列threads_queue,大小为num_threads,队列中的元素值是子线程编号,代表目前可用的线程数及哪些线程可用,初始化后可用的线程数为0。
- 根据子线程的执行情况,设置出错标志或结束标志,目的是让主线程知道目前的执行状态。
3.3 与子线程的交互过程
- 初始化全局任务队列task_queue,全局线程队列threads_queue,每个线程的执行上下文ExecutorContext。
- 创建子线程,去执行任务,入口函数为executeSingleThread(thread_num, num_threads),thread_num表示线程编号,num_threads表示线程总个数。
- 处理错误,如果一个线程执行过程中出错,调度线程则通知其他子线程执行结束,并等待所有子线程结束。
- 等待所有子线程执行结束。
3.4 初始化全局任务队列task_queue过程
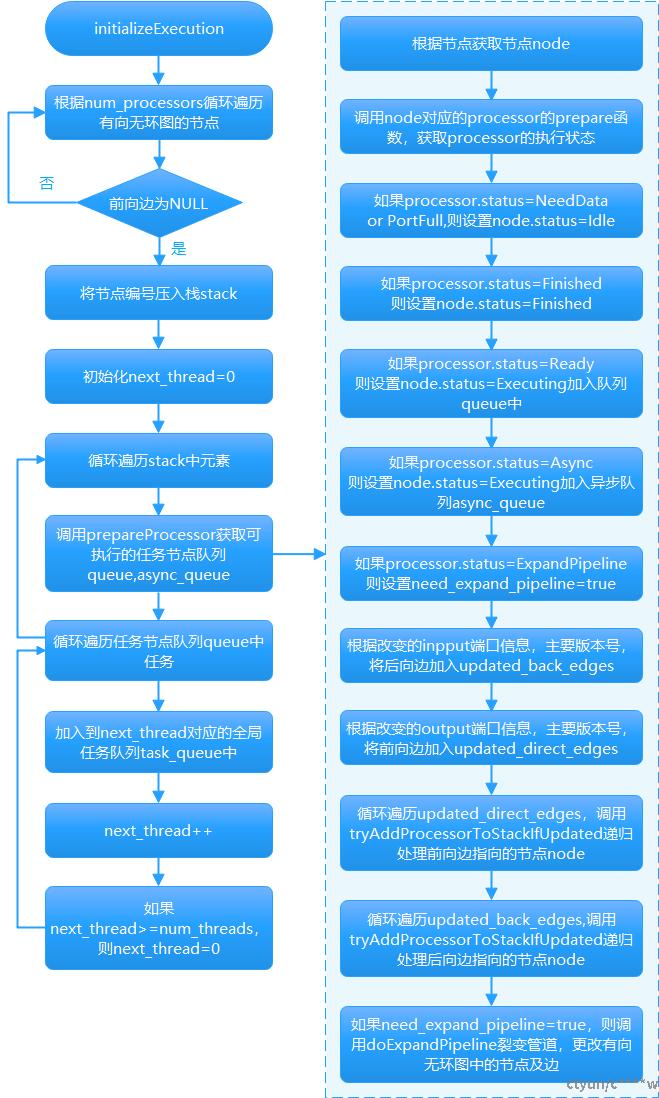
流程描述:
(1)遍历有向无环图中所有节点node,将没有前向边的节点编号压入stack。
(2)初始化局部变量next_thread=0,循环遍历stack中的元素,针对每一个元素调用prepareProcessor递归获取状态为Ready 或者Async的节点加入任务队列queue或者async_queue(初始化时该队列一定为NULL),然后再循环遍历queue,依次将任务加入task_queue[next_thread],并next_thread++,当next_thread>=num_thread,重新设置next_thread=0。
(3)简单查询select * from t2 where tc2=2 and tc3=3;的初始化全局任务队列task_queue过程:
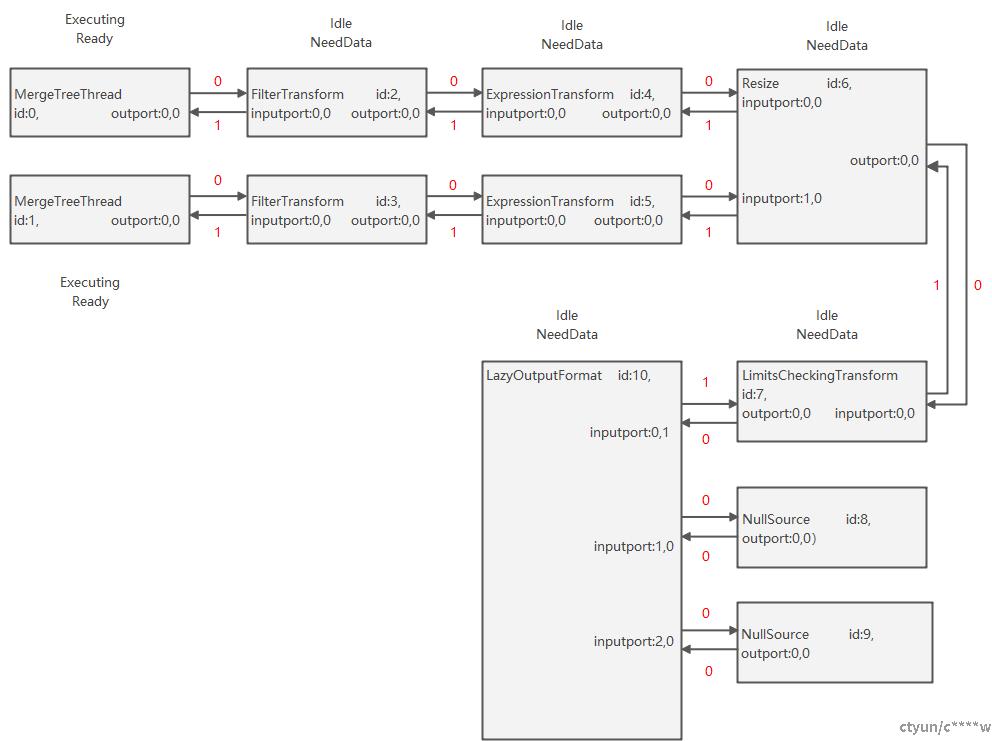
(i)遍历所有节点,选择没有前向边的节点10压入stack。
(ii)调用IOutputFormat::prepare()获取节点10对应的processor执行状态NeedData,并更新inputport 0的版本号为1,此时节点10的后向边版本号也变成1,发现后向边版本改变,继续处理节点7,调用ISimpleTransform::prepare()获取节点7对应的processor执行状态NeedData,并更新inputport 0的版本号为1,此时节点7的后向边版本号也变成1,发现后向边版本改变,继续处理节点6,4,2,0,处理节点0时调用ISource::prepare()获取执行状态为Ready,则将节点0加入线程号为0的任务队列task_queue[0],继续处理节点6,5,3,1,处理节点1时调用ISource::prepare()获取执行状态为Ready,则将节点1加入线程号为1的任务队列task_queue[1]。
(iii)经过初始化后,全局任务队列task_queue[0]={节点0},task_queue[1]={节点1}。
4. 执行子线程
子线程是任务的实际执行者,通过生产处理Chunk,放到全局ConcurrentBoundedQueue queue中让主线程去消费。
入口函数:executeSingleThread(size_t thread_num,size_t num_threads)。
主要执行函数:PipelineExecutor::executeStepImpl(size_t thread_num, size_t num_threads, std::atomic_bool * yield_flag)。
输入:size_t thread_num(当前子线程编号);size_t num_threads(子线程总数)。
输出:Chunk。
4.1 实现流程
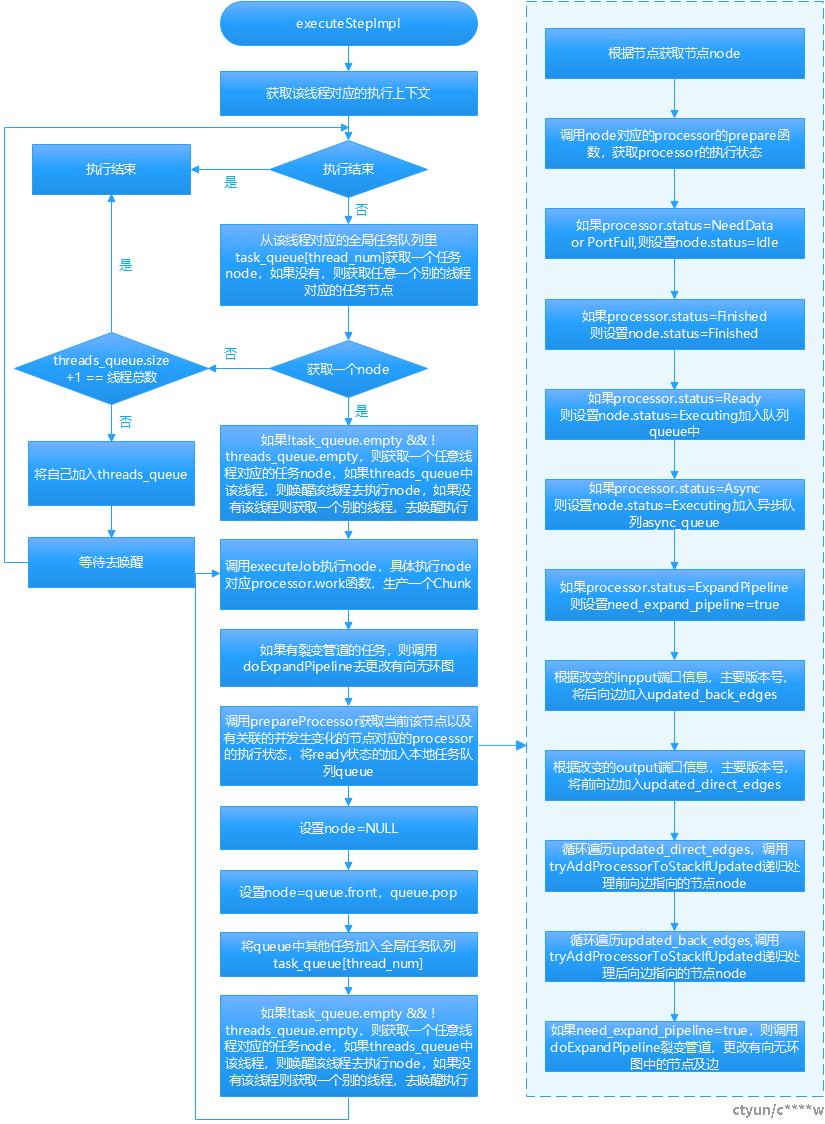
注:work()函数负责处理Chunk,prepare()函数负责推拉数据,数据及状态的传递,如果引起了前向边,后向边的变化,则接着处理临近的节点,将节点状态为Ready的加入任务队列。
4.2 前向边节点间数据流及状态的传输
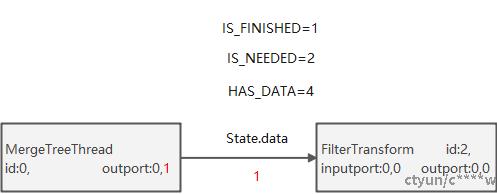
以节点0,2为例:
- 节点0经过work()函数获取不到数据,执行结束,然后调用prepare()函数,调用output.finish(),设置状态位IS_FINISHED=1写入到与input共用state.data的前八字节,更新output版本信息,因此前向边版本发生变化,接着处理节点1。
- 节点0经过work()函数获取到数据,然后调用prepare(),调用output.putData(),设置状态位HAS_DATA,并更新output版本信息,因此前向边版本发生变化,接着处理节点1。
- 节点1调用prepare()获取状态位IS_FINISHED,调用output.finish(),结束执行,更新output版本信息,接着处理后面的节点。
- 节点1调用prepare() 获取状态位HAS_DATA,调用input.pullData将数据拉回本地,将节点1的处理者状态变为Ready,准备执行,压入任务队列,此时input,output都不发生变化,结束遍历有向无环图,去执行任务。
4.3 后向边节点间状态的传输
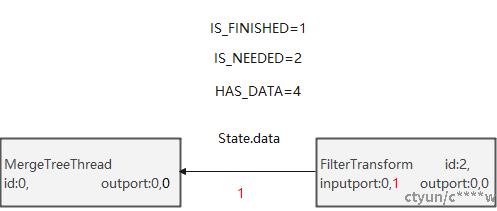
以节点2,0为例:
- 节点1的output执行结束,比如limit语句,则调用input.close(),关闭input,设置状态为IS_FINISHED,更新input版本号及后向边的版本号。
- 节点1的output有数据has_output=true,则调用input.setNotNeeded(),设置状态为!IS_NEEDED,更新input版本号及后向边的版本号。
- 节点1的output没有数据has_output=false,input也没有数据has_input=false,调用input.setNeeded,设置状态为IS_NEEDED,更新input版本号及后向边的版本号。
- 节点0的output发现状态为IS_FINISHED,则执行结束。
- 节点0的output发现状态为!IS_NEEDED,则返回状态PortFull。
- 节点1的output需要数据,则返回状态Ready,开始执行工作。
4.4 执行流程举例
以简单查询select *fromt2 where tc2=2 and tc3=3的物理计划为例(set max_threads=2),执行流程如下:
1. 调度线程初始化全局任务队列task_queue[0]={节点0},task_queue[1]={节点1}。
2. 调度线程创建执行子线程,子线程0,子线程1,子线程0进入自己的入口函数executeSingleThread,从对应任务队列task_queue[0]={节点0}获取任务节点0,调用ISource::work()进行处理一个Chunk,并更改has_input=true,再调用ISource:: prepare()执行outport.pushData(Chunk),将数据放到与相连的inputport共用的state上,更新状态为HAS_DATA,并更新outport的版本,获取执行状态为PortFull,此时前向边版本号发生改变,继续处理节点2,调用FilterTransform::prepare(),判断output没有数据并且inputport的执行状态为HAS_DATA,执行inputport.pullData()将state上的数据拉回本地(其实move一下),获取执行状态为Ready,此时outport,inputport都不更新版本,将节点2加入本地任务队列去执行,然后执行任务节点2,调用FilterTransform::work()执行transform处理一个Chunk,并更改has_input=false,has_output=true,再调用FilterTransform::prepare()执outport.pushData(chunk),将数据放到与相连的inputport共用的state上,并更新outport的版本,获取执行状态为PortFull,此时前向边版本号发生改变,继续处理节点4,调用ISimpleTransform::prepare()获取执行状态,如果为Ready,加入任务队列继续执行……,有向图变化如下图所示:
(1)节点0,1分别从Storage读取第一个Chunk,并更新前向边的版本号为1。
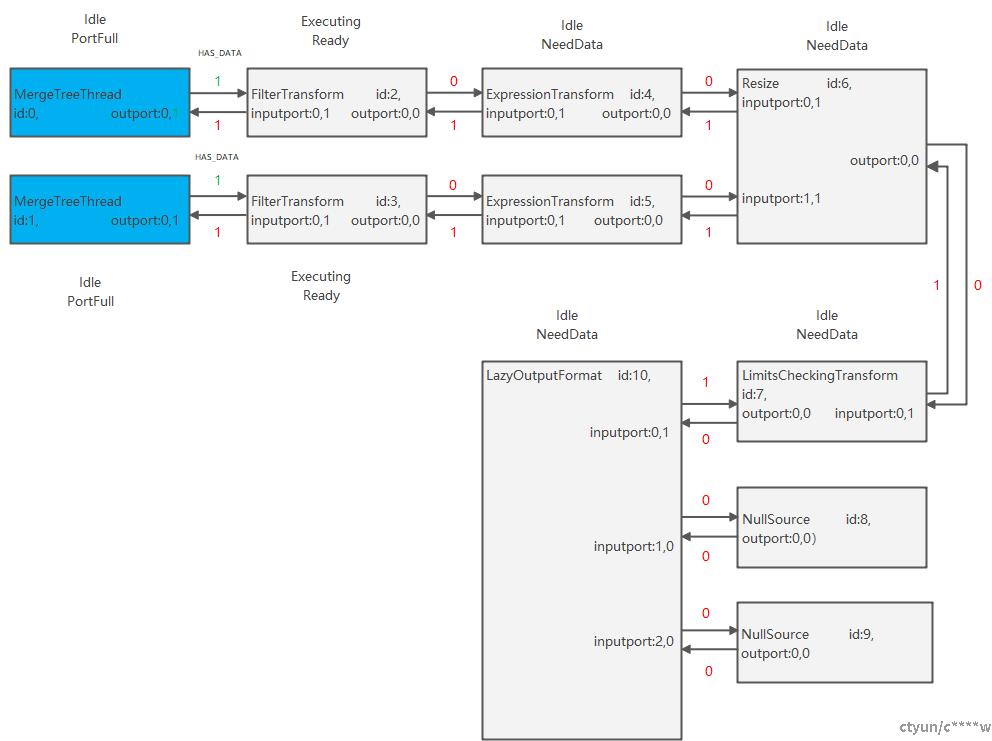
(2)节点2,3分别处理第一个Chunk,并更新前向边的版本号为1。
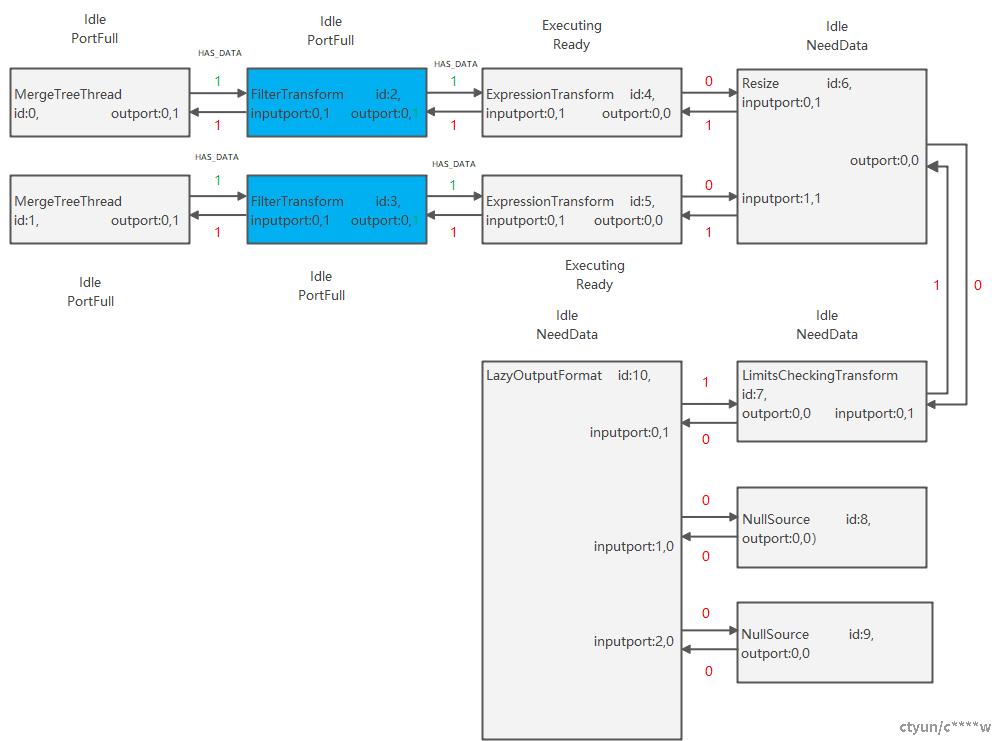
(3)节点6处理第一个Chunk,Resize只有prepare函数,只做数据的移动,不做任何处理,当接到节点4的数据后,会同时更新前向边和后向边,同时将节点7,节点0加入任务队列,当前线程会获取队列的第一个元素,及节点7去执行,将节点0加入全局任务队列task_queue,如果此时有空闲的线程,则唤醒去执行。
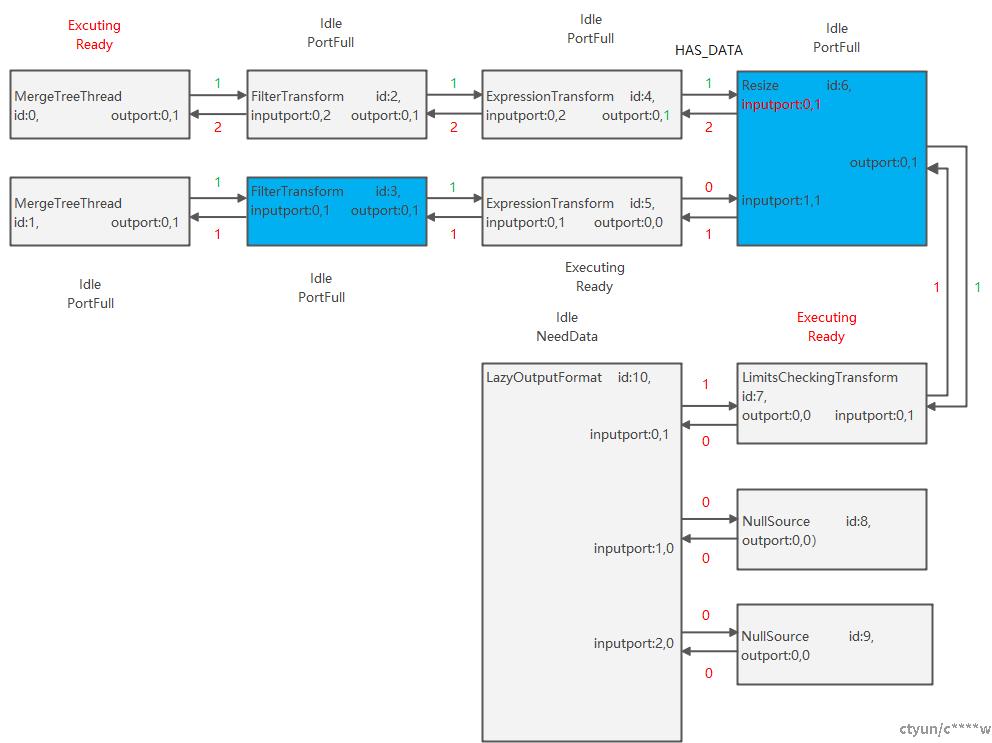
(4)线程1执行完节点5,发现节点6的状态为PortFull,就空闲下来等待,结果被线程0唤醒去执行节点0,线程1处理完第三个Chunk。
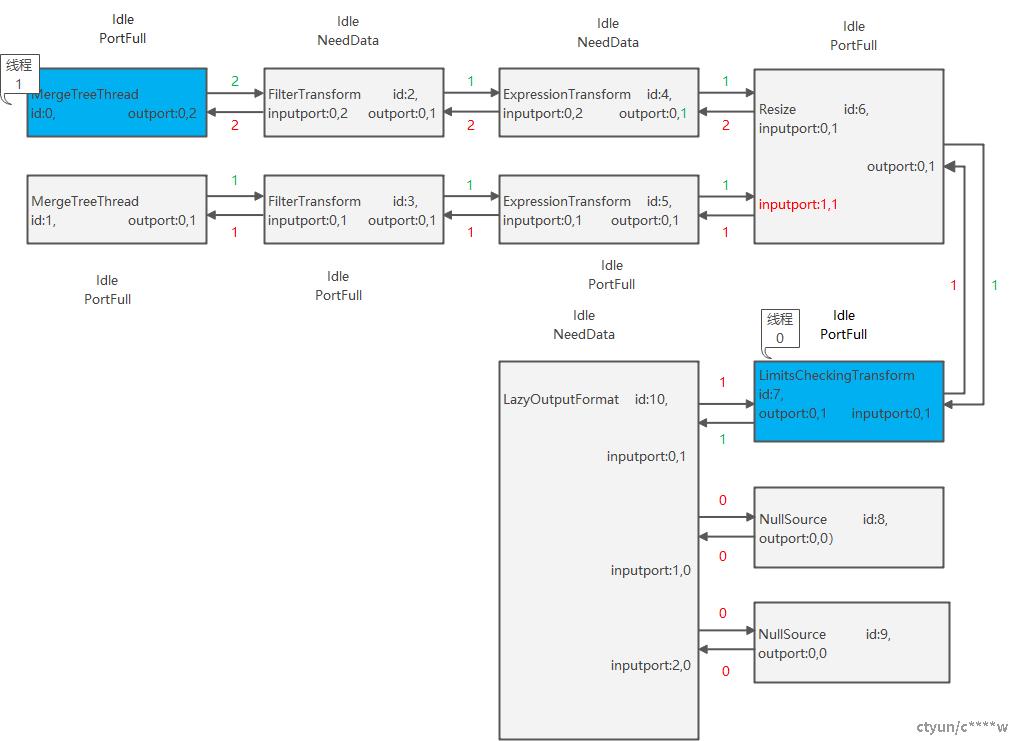
3. 子线程0读取第4个Chunk时,发现没有数据,则执行完成,调用Isource::prepare()执行outport.finish更新输出端口版本号,更改执行状态为Finished,然后调用FilterTransform::prepare()更新输出端口版本号,更改执行状态为Finished,继续调用ISimpleTransform::prepare(),ISimpleTransform::prepare(),ResizeProcessor::prepare()……,有向图执行状态变化如下:
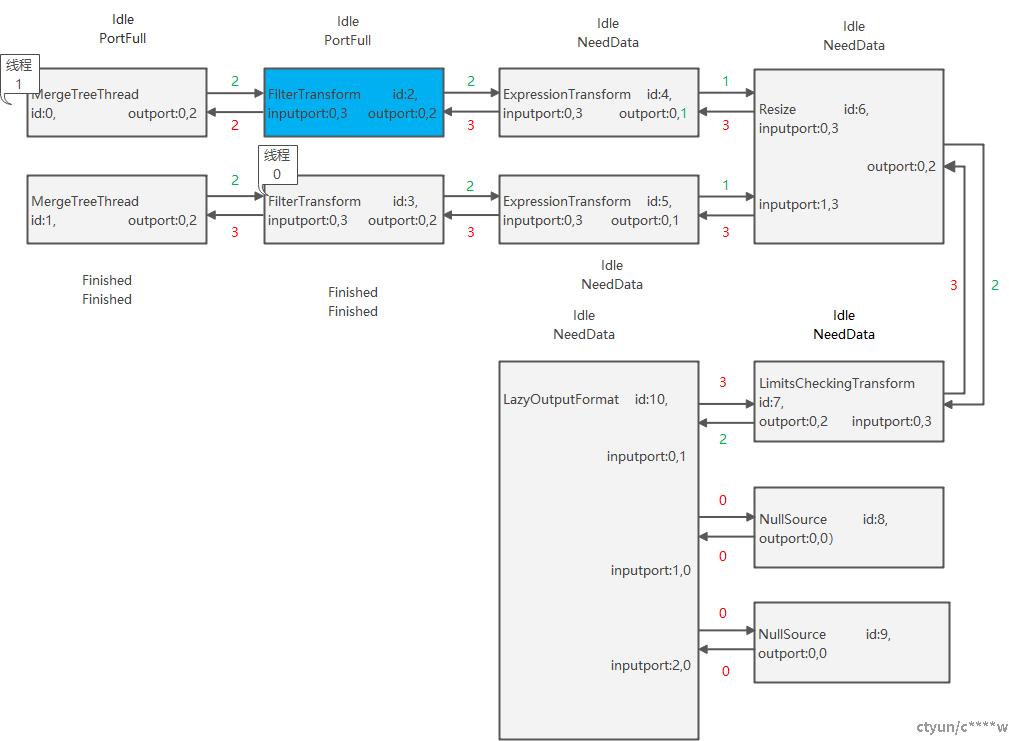
4. 调度线程等待执行子线程结束。
4.5 子线程间的交互
- 子线程获取任务节点后,发现全局任务队列task_queue不为NULL,全局线程队列threads_queue不为NULL,则唤醒别的空闲线程去执行任务。
- 当自己出错后,会遍历所有节点,设置每个节点的取消标志,并唤醒其他等待的子线程。
- 当自己判断执行结束时,会唤醒其它等待的子线程。
