


1. 引言
1.1 传统关系型数据库查询优化器
查询优化器通常包含两项工作:一是逻辑优化,二是物理优化。逻辑优化主要解决的问题是如何找出SQL语句等价的变换形式,使得SQL执行更高效。运用查询优化技术,如视图重写、子查询提升、子链接提升、条件化简、等价谓词重写、外连接消除、嵌套连接消除等,对语法树进行等价转换,得到逻辑查询计划。物理优化主要解决的问题是从可选的单表扫描方式中,挑选出最优的方式,对于两个表连接时,如何连接是最优的?对于多个表连接,连接顺序有多重组合,是否要对每种组合都探索?如果不全部探索,怎么找到最优的一种组合?为了解决这些问题需要根据数据库的统计信息,使用基于代价的查询优化方式,对多种查询执行计划进行定量分析,对每一个可能的执行方式进行评估,选择出代价最小的作为最优的物理查询计划。在查询优化器实现的早期,使用的只是逻辑优化技术,认为此时生成的查询计划就是最优的。目前,数据库的查询优化器通常融合了这两种方式。
1.2 ClickHouse查询优化器
根据查询优化器的功能,也可以将ClickHouse查询优化器分成逻辑优化和物理优化两个部分,但ClickHouse并没有统计信息和代价模型,其经过逻辑优化后就生成了最优的逻辑查询计划,物理优化阶段只是将最优的逻辑查询计划转化成机器更容易识别的操作,称为物理查询计划。
生成逻辑查询计划的入口函数为InterpreterSelectQuery::InterpreterSelectQuery,生成物理查询计划的入口函数为InterpreterSelectQuery::execute。
输入:ASTSelectQuery语法树。
输出:QueryPipeline物理查询计划。
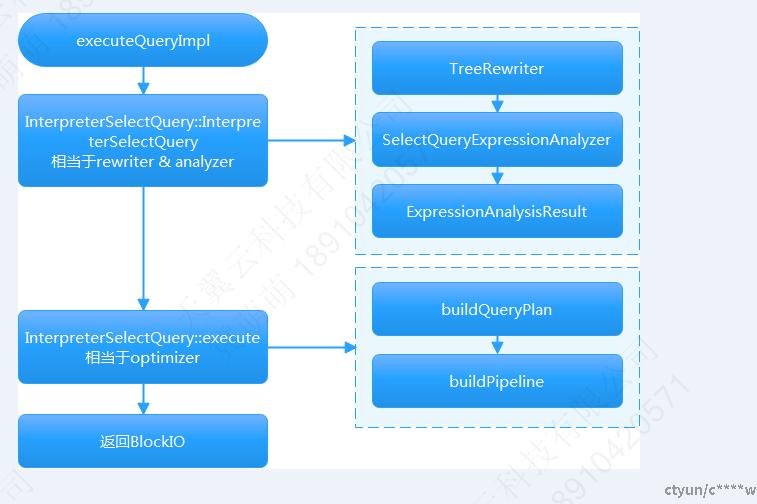
2.逻辑优化
入口函数为InterpreterSelectQuery::InterpreterSelectQuery。源码中可以看到非常多的基于规则的优化,每个规则对应一个类,类中有visitor方法,该方法会遍历整个抽象语法树,一旦匹配该规则对其进行重写,重写结果存放在TreeRewriterResult类中,然后经过表达式分析器SelectQueryExpressionAnalyzer,爬取AST上的表达式,将其转化成一系列的Actions,并形成执行操作链,并将Actions保存在ExpressionAnalysisResult上,作为buildQueryPlan生成物理查询计划的输入。
输入:ASTSelectQuery语法树。
输出:ExpressionAnalysisResult重写分析结果。
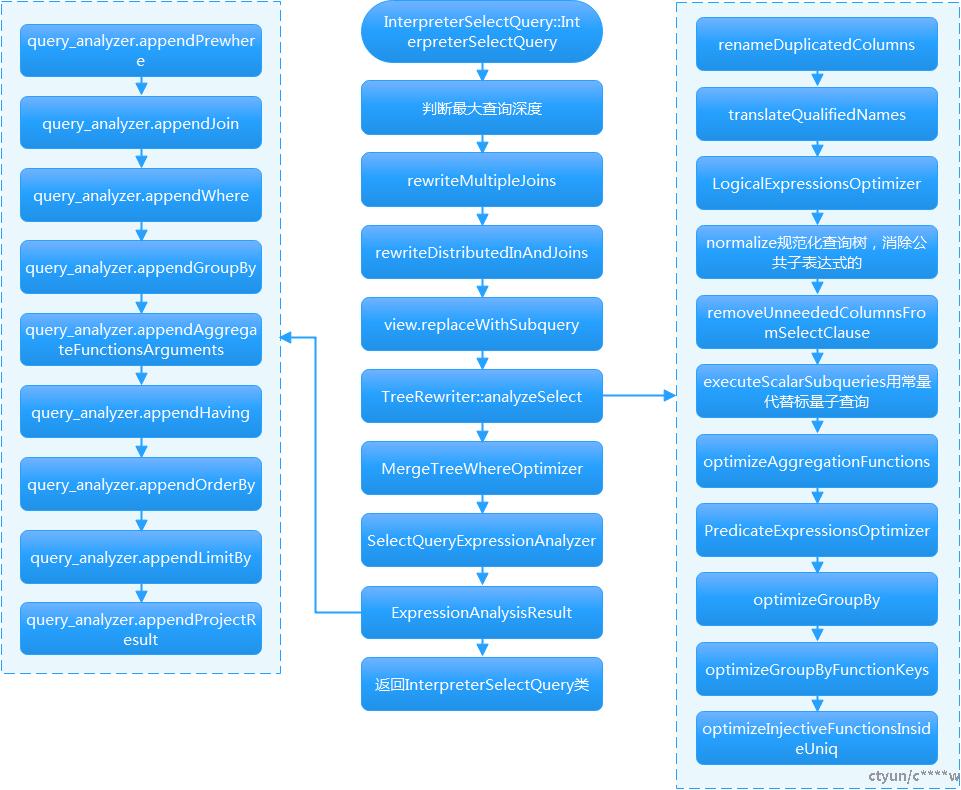
2.1 实现流程
2.2 流程描述
1. rewriteMultipleJoins针对多表join的优化,包括一定规则下,重写cross join 为inner join,重写join 为subquery。
static void rewriteMultipleJoins(ASTPtr & query, const TablesWithColumns & tables, const String & database)
{
ASTSelectQuery & select = query->as<ASTSelectQuery &>();
/// 收集查询中的别名,记录在map,指向真实的node
Aliases aliases;
if (ASTPtr with = select.with())
QueryAliasesNoSubqueriesVisitor(aliases).visit(with);
QueryAliasesNoSubqueriesVisitor(aliases).visit(select.select());
/// 重写cross join为inner join
/// select * from t1 a cross join t2 b where a.tc1=b.tc1 重写成 select * from t1 a inner join t2 b on a.tc1=b.tc1
CrossToInnerJoinVisitor::Data cross_to_inner{tables, aliases, database};
CrossToInnerJoinVisitor(cross_to_inner).visit(query);
/// select * from t1 join t2 on ...join t3 on ...join t4 on...重写成select * from (select * from t1 join t2 on ...)join t3 on ...)join t4 on ...
JoinToSubqueryTransformVisitor::Data join_to_subs_data{tables, aliases};
JoinToSubqueryTransformVisitor(join_to_subs_data).visit(query);
}2. rewriteDistributedInAndJoins重写分布式表的in和join。
void JoinedTables::rewriteDistributedInAndJoins(ASTPtr & query)
{
/// Rewrite IN and/or JOIN for distributed tables according to distributed_product_mode setting.
InJoinSubqueriesPreprocessor::SubqueryTables renamed_tables;
InJoinSubqueriesPreprocessor(context, renamed_tables).visit(query);
String database;
if (!renamed_tables.empty())
database = context.getCurrentDatabase();
for (auto & [subquery, ast_tables] : renamed_tables)
{
std::vector<DatabaseAndTableWithAlias> renamed;
renamed.reserve(ast_tables.size());
for (auto & ast : ast_tables)
renamed.emplace_back(DatabaseAndTableWithAlias(*ast->as<ASTIdentifier>(), database));
/// Change qualified column names in distributed subqueries using table aliases.
RenameQualifiedIdentifiersVisitor::Data data(renamed);
RenameQualifiedIdentifiersVisitor(data).visit(subquery);
}
}3. replaceWithSubquery用子查询代替视图,select * from t1_v2重写成 SELECT tc1,tc2 from (select * from t1) as t1_v2,其中t1_v2为定义的视图。
void StorageView::replaceWithSubquery(ASTSelectQuery & outer_query, ASTPtr view_query, ASTPtr & view_name)
{
ASTTableExpression * table_expression = getFirstTableExpression(outer_query);
view_name = table_expression->database_and_table_name;
table_expression->database_and_table_name = {};
table_expression->subquery = std::make_shared<ASTSubquery>();
table_expression->subquery->children.push_back(view_query);
table_expression->subquery->setAlias(alias);
for (auto & child : table_expression->children)
if (child.get() == view_name.get()) child = view_query;
}4. TreeRewriter::analyzeSelect其它规则逻辑优化的总入口。
重写结果存放在TreeRewriterResult类中,包括renameDuplicatedColumns重命名重复列,LogicalExpressionsOptimizer逻辑表达式优化,比如expr=x1 or expr=x2=> expr in (x1,x2),normalize规范化查询树消除公共子表达式,如果表达式 x op y 先前被计算过,并且从先前的计算到现在其计算表达式对应的值没有改变,那么 x op y就称为公共子表达式,公共子表达式消除会搜索所有相同计算表达式的实例,并分析是否值得用保存计算值的单个变量来替换它们,以减少计算的开销,executeScalarSubqueries用常量来替换SQL中所有的标量子查询结果,。。。,如果想增加一个规则,则实现一个规则类和visitor函数,visitor函数会遍历整个查询树,跟定义的规则进行匹配,一旦匹配就重写查询树。
TreeRewriterResultPtr TreeRewriter::analyzeSelect(
ASTPtr & query,
TreeRewriterResult && result,
const SelectQueryOptions & select_options,
const std::vector<TableWithColumnNamesAndTypes> & tables_with_columns,
const Names & required_result_columns,
std::shared_ptr<TableJoin> table_join) const
{
if (remove_duplicates)
renameDuplicatedColumns(select_query);
/// Optimizes logical expressions.
LogicalExpressionsOptimizer(select_query, settings.optimize_min_equality_disjunction_chain_length.value).perform();
normalize(query, result.aliases, settings);
/// Remove unneeded columns according to 'required_result_columns'.
removeUnneededColumnsFromSelectClause(select_query, required_result_columns, remove_duplicates);
/// Executing scalar subqueries - replacing them with constant values.
executeScalarSubqueries(query, context, subquery_depth, result.scalars, select_options.only_analyze);AI助手AI助手
/// GROUP BY injective function elimination.
optimizeGroupBy(select_query, source_columns_set, context);
/// GROUP BY functions of other keys elimination.
if (settings.optimize_group_by_function_keys)
optimizeGroupByFunctionKeys(select_query);
/// Move all operations out of any function
if (settings.optimize_move_functions_out_of_any)
optimizeAnyFunctions(query);
if (settings.optimize_normalize_count_variants)
optimizeCountConstantAndSumOne(query);
if (settings.optimize_rewrite_sum_if_to_count_if)
optimizeSumIfFunctions(query);
/// Remove injective functions inside uniq
if (settings.optimize_injective_functions_inside_uniq)
optimizeInjectiveFunctionsInsideUniq(query, context);
/// Eliminate min/max/any aggregators of functions of GROUP BY keys
optimizeAggregateFunctionsOfGroupByKeys(select_query, query);
/// Remove duplicate ORDER BY and DISTINCT from subqueries.
if (settings.optimize_duplicate_order_by_and_distinct)
{
optimizeDuplicateOrderBy(query, context);
/// DISTINCT has special meaning in Distributed query with enabled distributed_group_by_no_merge
/// TODO: disable Distributed/remote() tables only
if (!settings.distributed_group_by_no_merge)
optimizeDuplicateDistinct(*select_query);
}
/// Remove functions from ORDER BY if its argument is also in ORDER BY
if (settings.optimize_redundant_functions_in_order_by)
optimizeRedundantFunctionsInOrderBy(select_query, context);
/// Replace monotonous functions with its argument
if (settings.optimize_monotonous_functions_in_order_by)
optimizeMonotonousFunctionsInOrderBy(select_query, context, tables_with_columns,metadata_snapshot ? metadata_snapshot->getSortingKeyColumns() : Names{});
/// Remove duplicate items from ORDER BY.
optimizeDuplicatesInOrderBy(select_query);
/// If function "if" has String-type arguments, transform them into enum
if (settings.optimize_if_transform_strings_to_enum)
transformIfStringsIntoEnum(query);
/// Remove duplicated elements from LIMIT BY clause.
optimizeLimitBy(select_query);
/// Remove duplicated columns from USING(...).
optimizeUsing(select_query);
return std::make_shared<const TreeRewriterResult>(result);
}5. MergeTreeWhereOptimizer优化where子句。
当查询语句中没有指定prewhere子句,只指定where子句,则从where子句选择一列或多列(该列的选择率比较大,能过滤掉多行,一般选择column = const or const1 <=column<=const2的条件)条件赋值prewhere,使在storage层根据prewhere条件提前过滤,提升性能。比如select * from t1 where tc2=2 and tc3=5,其中5的distinct较小,重复数据多,则将tc3=5 下降到prewhere,改写成select * from t1 prewhere tc3=5 where tc3=5 and tc2=2;
void MergeTreeWhereOptimizer::optimize(ASTSelectQuery & select) const
{
if (!select.where() || select.prewhere())
return;
Conditions where_conditions = analyze(select.where());
Conditions prewhere_conditions;
UInt64 total_size_of_moved_conditions = 0;
UInt64 total_number_of_moved_columns = 0;
/// Move condition to prewhere
auto move_condition = [&](Conditions::iterator cond_it)
{
prewhere_conditions.splice(prewhere_conditions.end(), where_conditions, cond_it);
total_size_of_moved_conditions += cond_it->columns_size;
total_number_of_moved_columns += cond_it->identifiers.size();
};
/// 移动条件,直到移动条件的总大小total_size_of_moved_conditions与查询列的总大小total_size_of_queried_columns之比小于某个阈值,意味着能过滤更多的行
while (!where_conditions.empty())
{
/// 从where条件中选择最好元素,每个元素按照是否有好的选择率,大小等排序,首选有好的选择率的条件
auto it = std::min_element(where_conditions.begin(), where_conditions.end());
/// 是否满足规定的阈值限制,如果满足则停止移动条件
bool moved_enough =
(total_size_of_queried_columns > 0 && total_size_of_moved_conditions > 0
&& (total_size_of_moved_conditions + it->columns_size) * 10 > total_size_of_queried_columns)
|| (total_number_of_moved_columns > 0
&& (total_number_of_moved_columns + it->identifiers.size()) * 10 > queried_columns.size());
if (moved_enough)
break;
/// move to prewhere
move_condition(it);
}
/// Rewrite the SELECT query.
select.setExpression(ASTSelectQuery::Expression::WHERE, reconstruct(where_conditions));
select.setExpression(ASTSelectQuery::Expression::PREWHERE, reconstruct(prewhere_conditions));
LOG_DEBUG(log, "MergeTreeWhereOptimizer: condition \"{}\" moved to PREWHERE", select.prewhere());
}6. SelectQueryExpressionAnalyzer创建表达式分析器。
输入是经过重写后生成的TreeRewriterResult,目的将语法树里表达式转换成一系列的可执行的操作链,转化后的Actions存放在ExpressionAnalysisResult相应字段,比如一个简单查询select * from t2 where tc2=2 and tc3=3,会调用query_analyzer.appendWhere生成where有关Actions,存放在analyzer_result.filter_info,query_nalyzer.appendProjectResult生成project有关Actions,存放在analyzer_result.final_projection字段,Actions之间是相互链接的。Actions就是机器更容易理解的动作,在执行阶段对每个数据block执行相应的Actions进行处理数据。
ExpressionAnalysisResult::ExpressionAnalysisResult(SelectQueryExpressionAnalyzer & query_analyzer)
{
ExpressionActionsChain chain;
/// 生成prewhere相关的actions
if (auto actions = query_analyzer.appendPrewhere(chain))
{
/// 保存到analyzer_result.prewhere_info
prewhere_info = std::make_shared<PrewhereDAGInfo>(actions, query.prewhere()->getColumnName());
}
/// 生成join相关的actions
array_join = query_analyzer.appendJoin(chain);
/// 生成where相关的actions
filter_info = query_analyzer.appendWhere(chain);
if (need_aggregate)
{
query_analyzer.appendGroupBy(chain);
query_analyzer.appendAggregateFunctionsArguments(chain);
query_analyzer.appendHaving(chain)
}
if (has_window)
{
query_analyzer.makeWindowDescriptions(chain);
query_analyzer.appendWindowFunctionsArguments(chain);
}
query_analyzer.appendOrderBy(chain);
query_analyzer.appendLimitBy(chain)
query_analyzer.appendProjectResult(chain);
finalize_chain(chain);
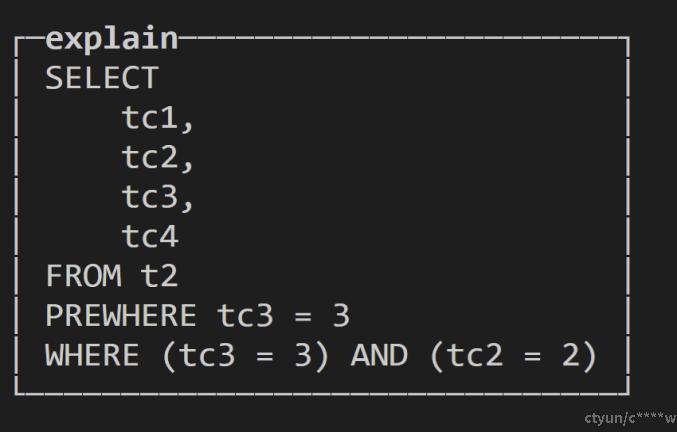
}2.3 如何查看经过哪些语义优化
explain syntax select * from t2 where tc2=2 and tc3=3;
3. 物理优化
入口函数为InterpreterSelectQuery::execute。首先调用buildQueryPlan根据ExpressionAnalysisResult分析结果,创建物理查询计划QueryPlan,每个节点称为一个QueryPlanStep,并指定相应的Actions。以查询语句select * from t2 where tc2=2 and tc3=3为例,普通的MergeTree表扫描创建ReadFormStorageStep,根据用户限额创建SettingQuotaAndLimitsStep,where条件创建FilterStep,project投影创建ProjectStep。其次调用buildQueryPipeline为每一个QueryPlanStep生成Processor,InputPort,OutputPort,并将每一步的InputPort,OutputPort连接起来,下层的OutputPort连接上层的InputPort。
输入:ExpressionAnalysisResult重写分析后的结果。
输出:QueryPipeline可执行物理计划。
3.1 buildQueryplan
3.1.1 实现流程
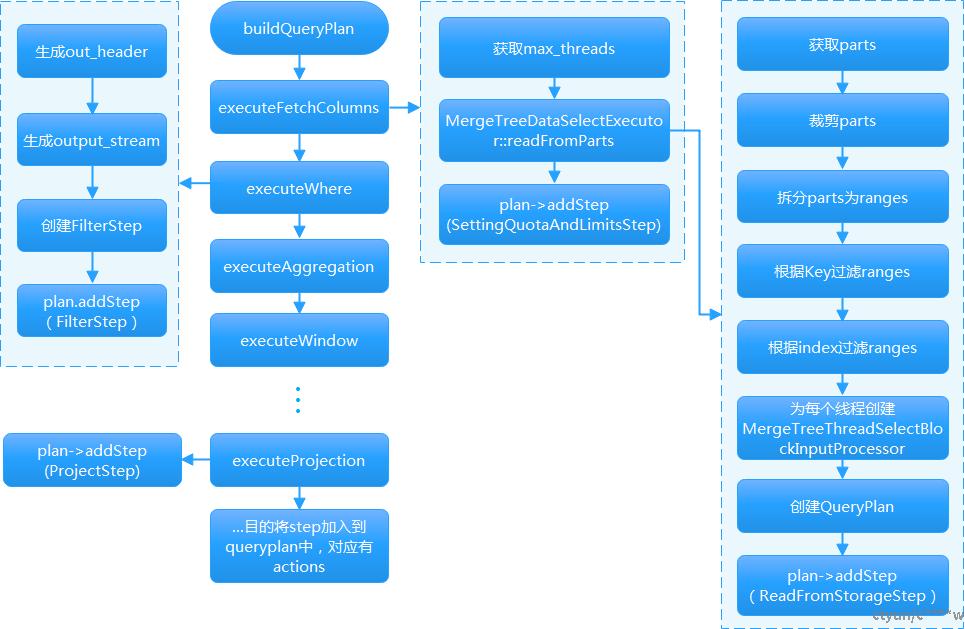
3.1.2 流程描述
1. 通过executeFetchColumns函数根据主键和索引裁剪parts,拆分为ranges,为每个线程创建扫描处理者MergeTreeThreadSelectBlockInputProcessor,创建QueryPlan,并生成ReadFormStorageStep加入到QueryPlan,将ranges,prewhere信息带入到MergeTreeThreadSelectBlockInputProcessor,等从storage读取数据时使用。
2. 根据ExpressionAnalysisResult分析结果,如果有where调用executewhere函数,生成filterStep,并生成输出头信息out_header,将filterStep加入到QueryPlan。
3. 如果有project调用executeProjection函数生成projectStep,并生成输出头信息out_header,output_stream,将projectStep加入到QueryPlan。
举例:当max_threads=2时,查询语句select * from t2 where tc2=2 and tc3=3;整个QueryPlan的结构如下所示:

3.2 buildPipeline
根据物理查询计划QueryPlan,buildPipeline为其它QueryPlanStep(除了ReadFromStorageStep)创建processors,inputport,outputport,并将上下层的连接起来,下层的outputport与上层的inputport相连,共享执行状态state,数据经过每步的processors处理后通过state进行上下层的传输。入口函数为buildPipeline()。
输入:QueryPlan。
输出:QueryPipeline可执行物理查询计划。
3.2.1 实现流程
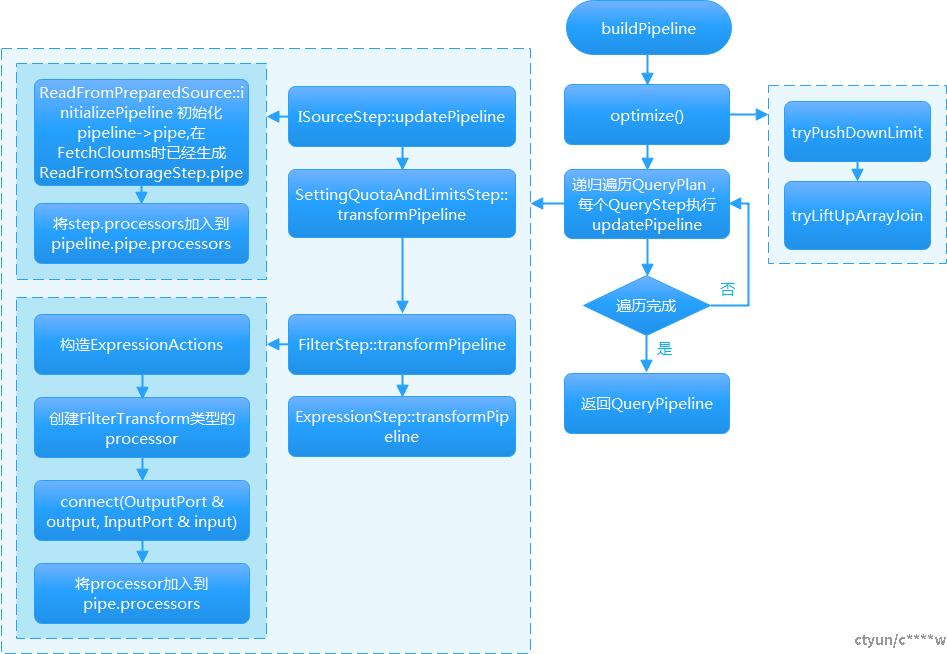
3.2.2 流程描述
1. 递归遍历QueryPlan,由叶子节点创建QueryPipeline,并为每一个Step生成max_threads个processors,并加入到QueryPipeline.pipe.processors,并连接上下层的inputport,outputport。
2. 每个Step都有自己的transformPipeline函数,根据Actions构造ExpressionActions,连接inputport,outputport,创建共享state。
举例:当max_threads=2时,查询语句select * from t2 where tc2=2 and tc3=3;的整个QueryPlan和QueryPipeline的结构及关系如下所示:
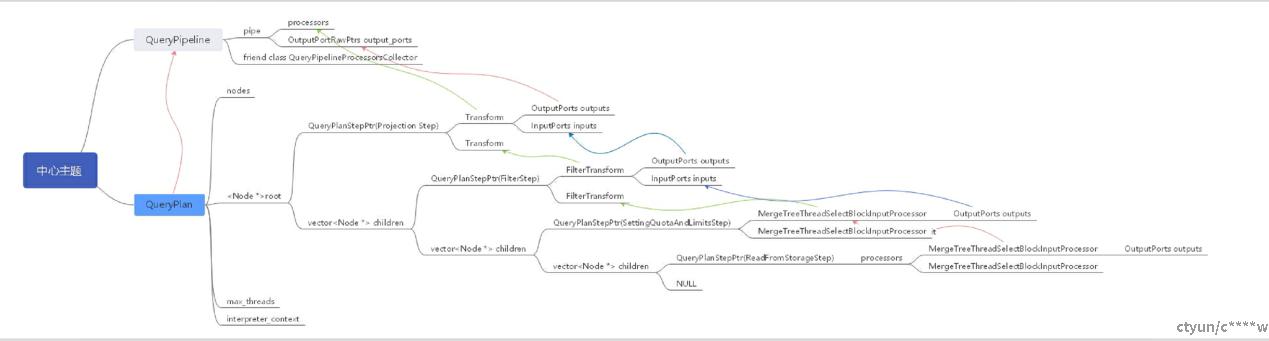
4.分布式查询计划
当数据表包含多个分片的时候,需要将普通的本地查询转换为分布式查询,在ClickHouse里面由Distributed表引擎进行代劳。Distributed表引擎的定位就好比是一个分表的中间件,它本身并不存储数据,而是分片的代理,能自动的将SQL查询路由到每个分片。
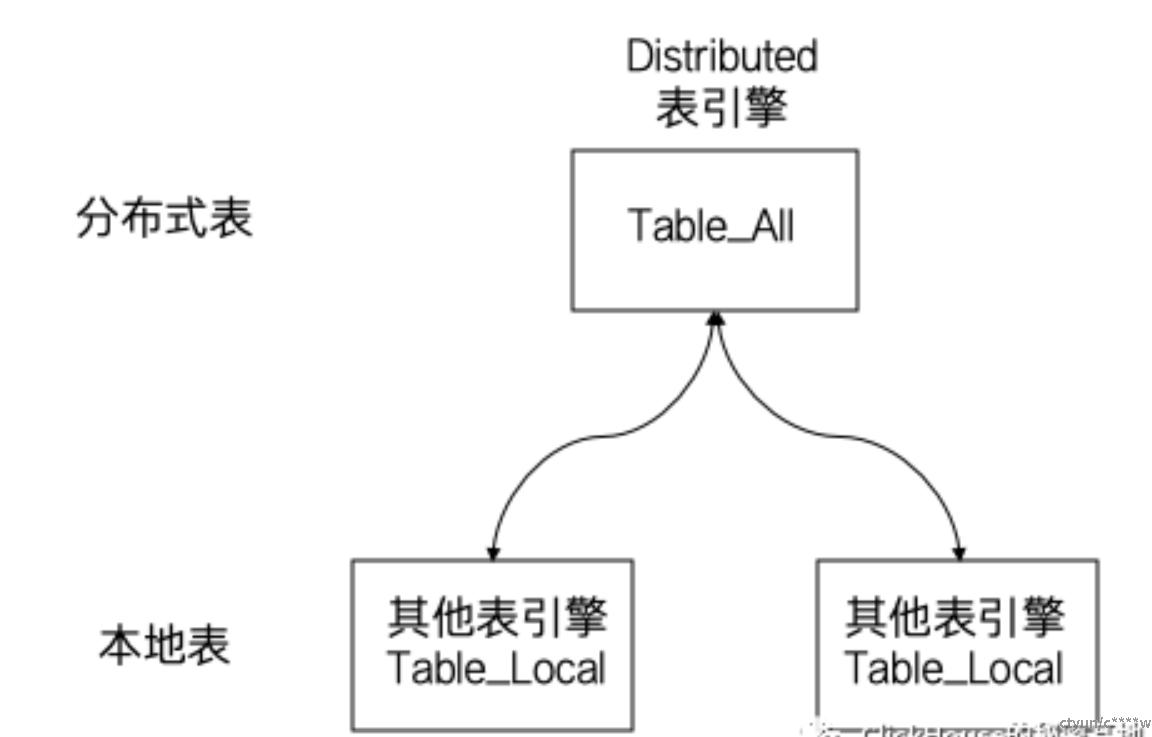
一种约定俗成的命名方式,是将Distributed表附带_all后缀;本地分片附带_local后缀,以示区分。
Distributed表引擎查询时,主要作用为:
(1)发起远程查询,根据集群的配置信息,从当前节点向远端分片发起Remote远程查询。
(2)分布式表转本地表,在发送远程查询时,将SQL内的 _all表 转成 _local表。
(3)合并结果集,合并由多个分片返回的数据。
例1:单表扫描explain select * from t1_all;
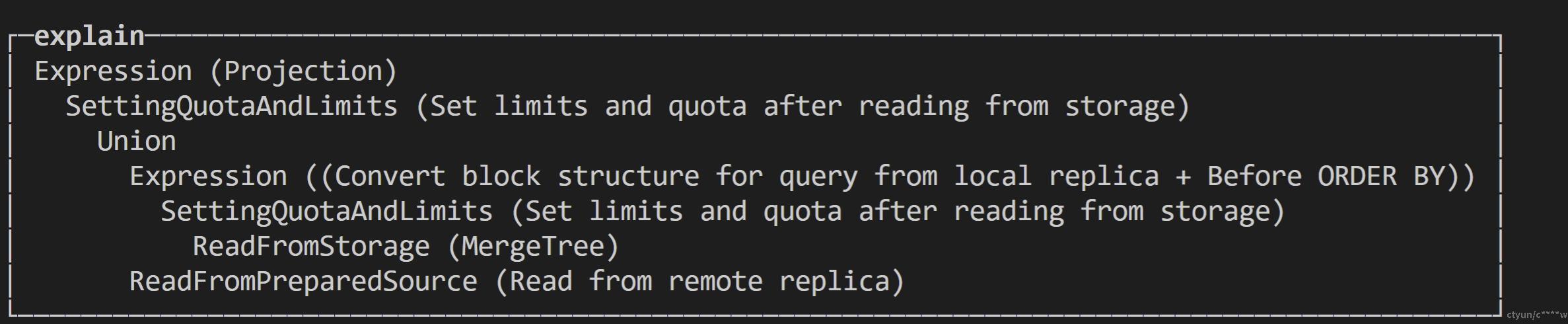
例1执行流程为:
1. ReadFromPreparedSource 向其它分片发起远程调用,并将发送查询语句select * from t1_local。
2. ReadFormStorage+SettingQuotaAndLimits+Expression查询本地分片数据。
3. union+SettingQuotaAndLimits+Expression合并本地和远端分片数据,并做投影。
例2:多表join explain select * from t1_all t1 inner join t1_all t2 on t1.tc1=t2.tc1;
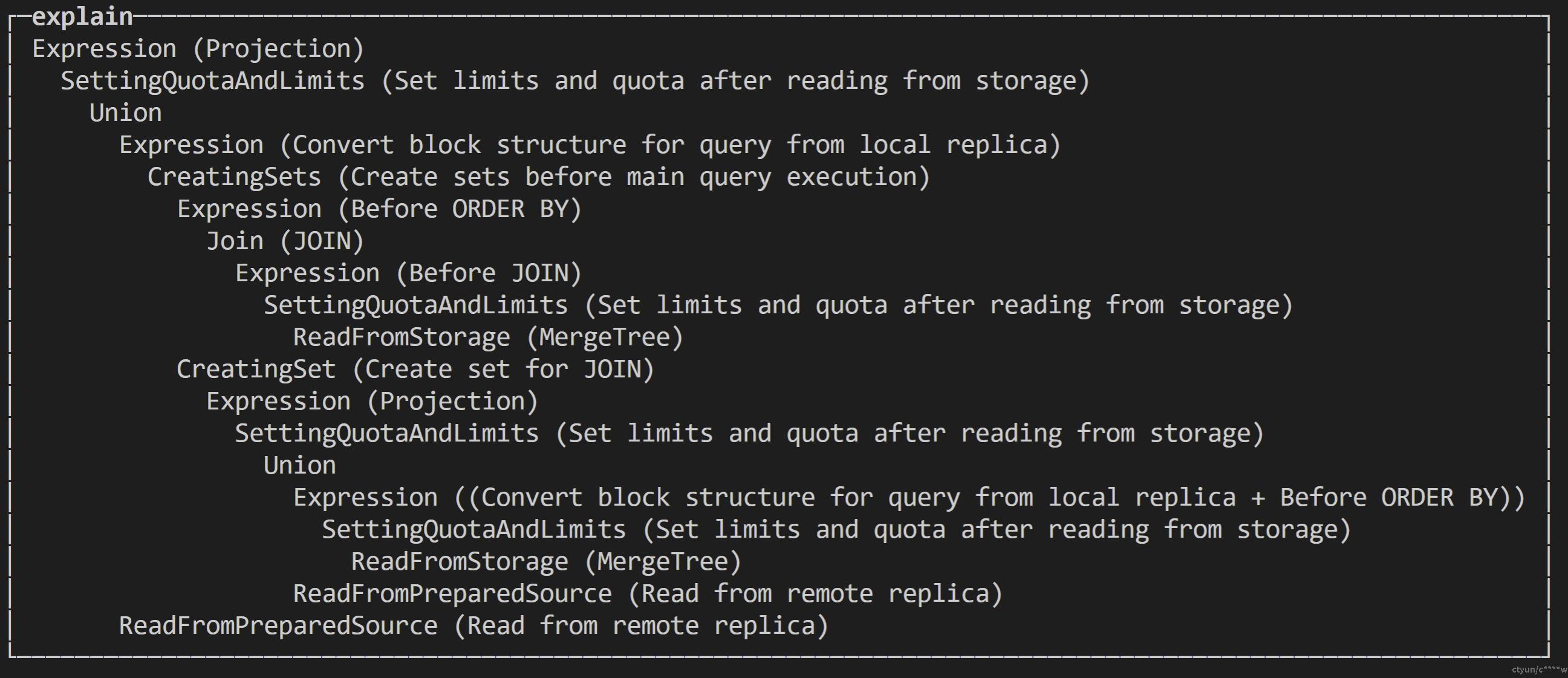
例2执行流程为:
1. 向t1表其它分片发起远端查询并将_all转化为_local,查询语句变为select * from t1_local inner join t1_all t2 on t1.tc1=t2.tc1;
2. t1的其它分片接到查询语句,向t2表其它分片发起远端查询,并将_all转化为_local,查询语句变为select * from t1_local t2并合并t2表数据,然后t1的每个分片执行select * from t1_local inner join t1_all t2 on t1.tc1=t2.tc1。
3. 合并select * from t1_local inner join t1_all t2 on t1.tc1=t2.tc1的join结果数据。
例2缺点:放大查询次数,放大次数是N的平方(N=分片数量),所以说,如果一张表有10个分片,那么一次Join的背后会涉及100次查询,这显然是不可接受的。
例2优化:可通过增加GLOBAL修饰符进行优化:explain select * from t1_all t1 global join t1_all t2 on t1.tc1=t2.tc1;
1. GLOBAL修饰的子句右表t2单独进行一次分布式查询 select * from t1_all t2。
2. 将右表t2的查询结果汇总后用内存临时表保存。
3. 直接将临时表分发至每个分片节点,然后t1_local与之作join操作,最后合并join结果数据, 从而避免了查询放大的问题。
