


1. sora模型结构
SORA结构如下图所示,大体可以分为三部分,视频编码、扩散学习和文本编码部分。视频编码是VAE结构,扩散学习是DiT(DDPM) ,文本编码采用CLIP
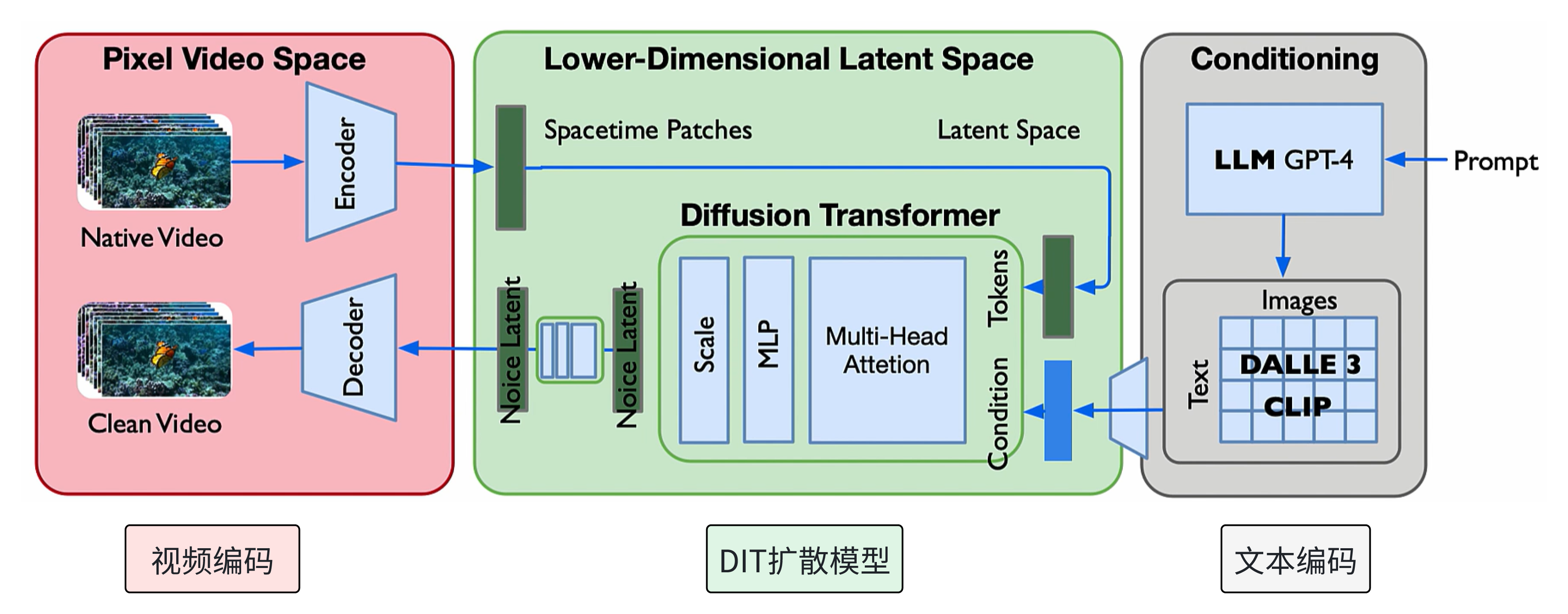
下面具体看VAE结构,DiT ,文本编码三部分。
2. 视频编码
在 LLM 里,以 token 作为基本单位。对应于图像/视频,基本单元是 patch。
视频是时间序列上的图像,每张图像都可以划分成多个 patch,且每张图像有RGB三个通道,因此 patch 后为一个小立方体。
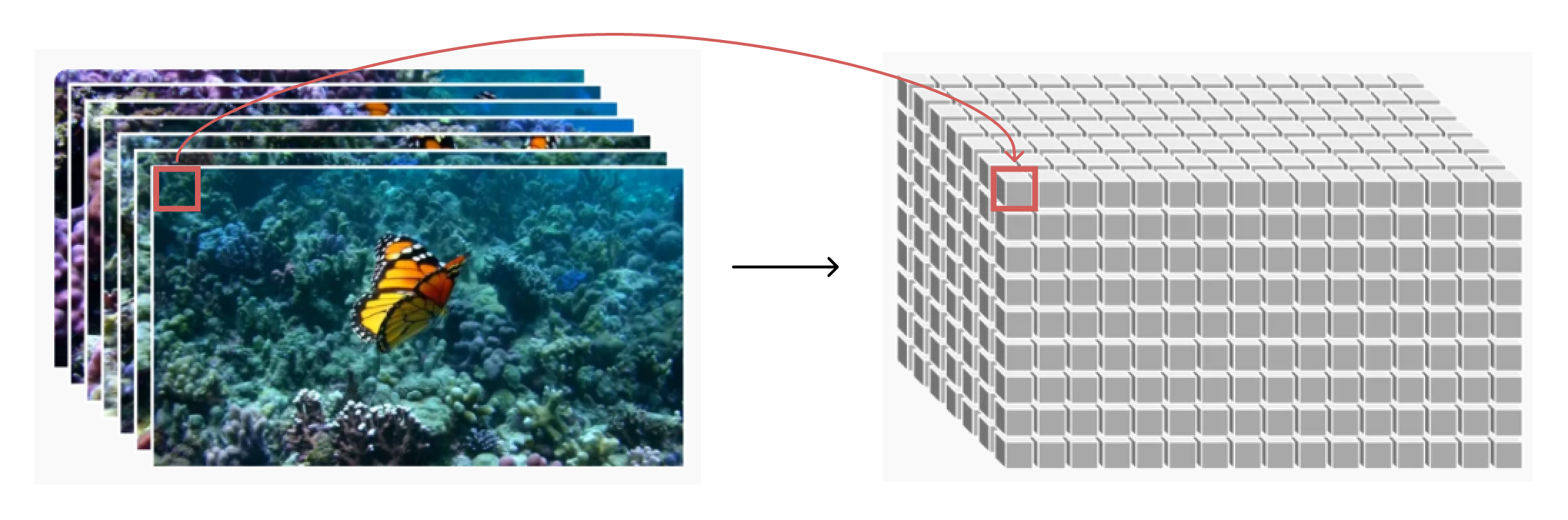
但这里有两个问题,一是小立方体的像素长度太大,比如20x20x3的大小,有1200维特征,太长不好计算。需要对原始视频进行“压缩”处理,提炼出视频图像里的特征信息。
二是 ViT 无法直接适用于不同尺寸图片输入,因为 Patch 大小是固定的,当图片大小改变时,序列长度就会改变,位置编码就无法直接适用了,那么不同分辨率和宽高比的视频如何处理?
解决第一个问题
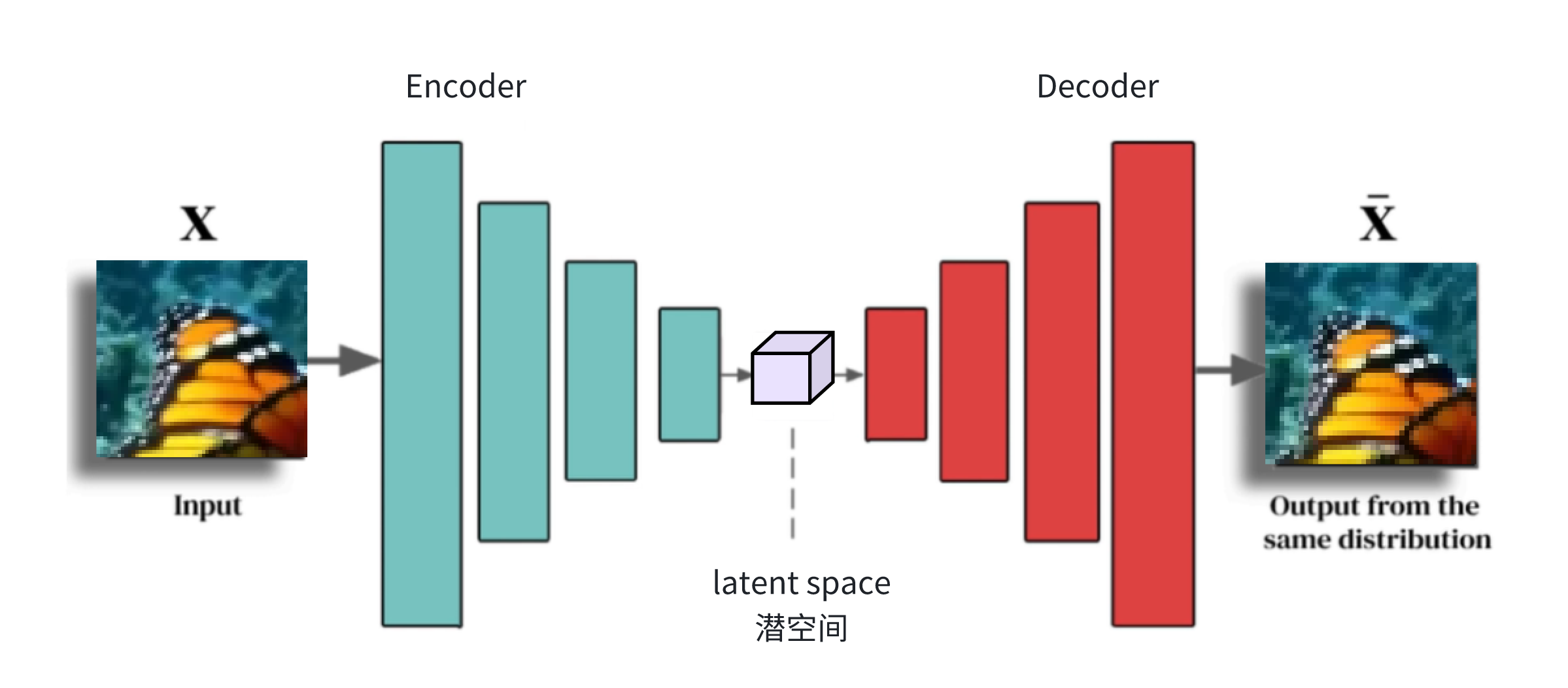
VAE(Variational Auto Encoder)
VAE的基本思想是将输入数据编码为潜在空间中的概率分布,并通过解码器网络生成新的样本数据。核心在于引入了隐变量,使得模型能够从高维数据中提取低维的潜在表示。
VAE的结构包括 Encoder 和 Decoder 两个部分。Encoder 负责将输入数据压缩成一个隐变量,而 Decoder 则将这个隐变量还原成新的样本数据。这种结构使得VAE不仅可以用于数据压缩,还能用于生成新的样本数据。
解决第二个问题
NaViT(Native Resolution ViT)
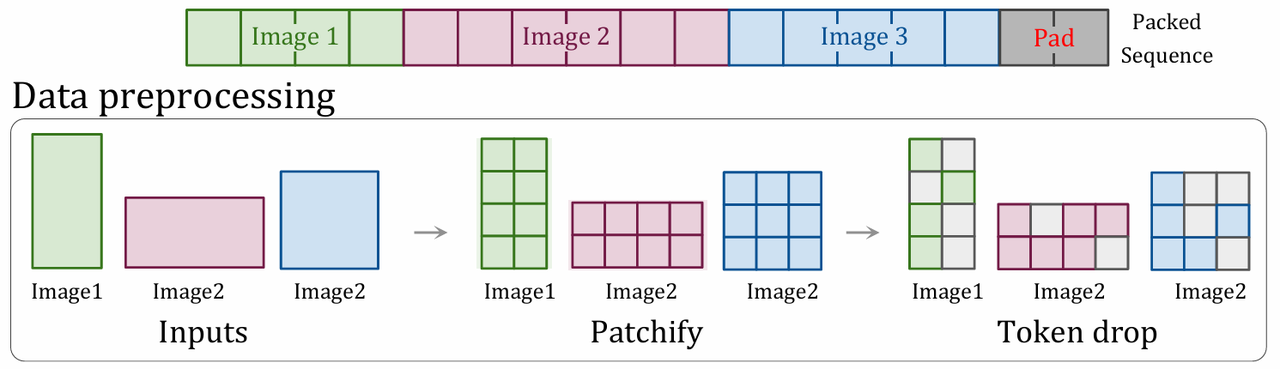
深度学习模型的batch训练,通常要求输入形状是固定大小,而大多数图像并非正方形,有各种长宽比,所以对图像通常采用缩放或填充的方法,但这会损害模型性能或效率。
在语言模型中,通过将多个样本的tokens打包成一个序列来加速训练,这种方法可以绕过固定序列长度的限制。
在图像视频领域,NaViT借鉴了该做法,采用Patch n' Pack技术,将多个图像的patches组合成一个序列,实现了模型在原生分辨率下进行训练,避免了缩放和填充图像所带来的缺陷。
NaViT还有一个关键技术:连续Token丢弃。它允许在训练过程中随机丢弃输入的patches。与传统的丢弃方法不同,连续Token丢弃可以根据每个图像独立调整丢弃率,从而在保持一些完整图像信息的同时提高训练速度。
下图中原始视频通过 VAE Encoder 将视频数据压缩成一个低维的潜在空间表示。这个过程既减少了视频在时间上的维度(比如减少帧数),也减少了空间上的维度(比如降低分辨率)。然后,这个压缩后的视频特征被分解成一系列的时空块(spacetime patches),这些 patch 就像 LLM 中 token 的角色,成为了模型学习和生成的基础。
这种基于时空块的方法使得模型能够处理和生成各种分辨率、持续时间和宽高比的视频,因为模型学习的是视频的基本构成单元——时空图像块的表示,而不是整个视频的全貌。

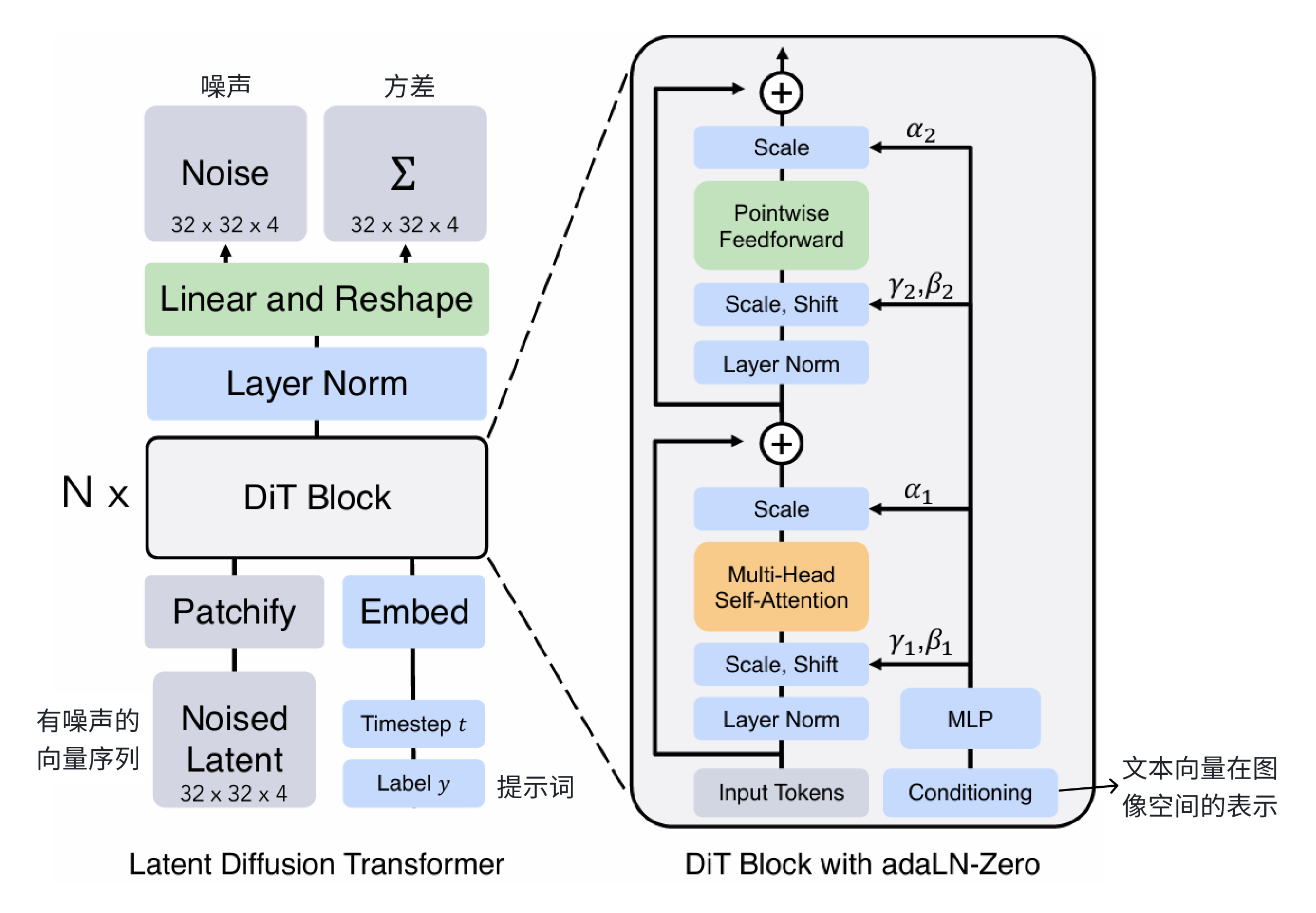
3.DiT(Diffusion Transformer)
DiT 是一种新型的扩散模型,结合了去噪扩散概率模型(DDPM)和 Transformer 架构。核心思想是使用Transformer 作为扩散模型的骨干网络,而不是传统的卷积神经网络(如U-Net),以处理图像的潜在表示。
【注意】
1.视频是一次性全部生成,并不是先生成第一帧,再生成第二帧,逐帧生成。这样可以保证生成视频的连续性。
2.DiT 的输入和输出是在潜空间操作,最后是需要 decoder 回真正的像素域图像空间。
4.文本编码
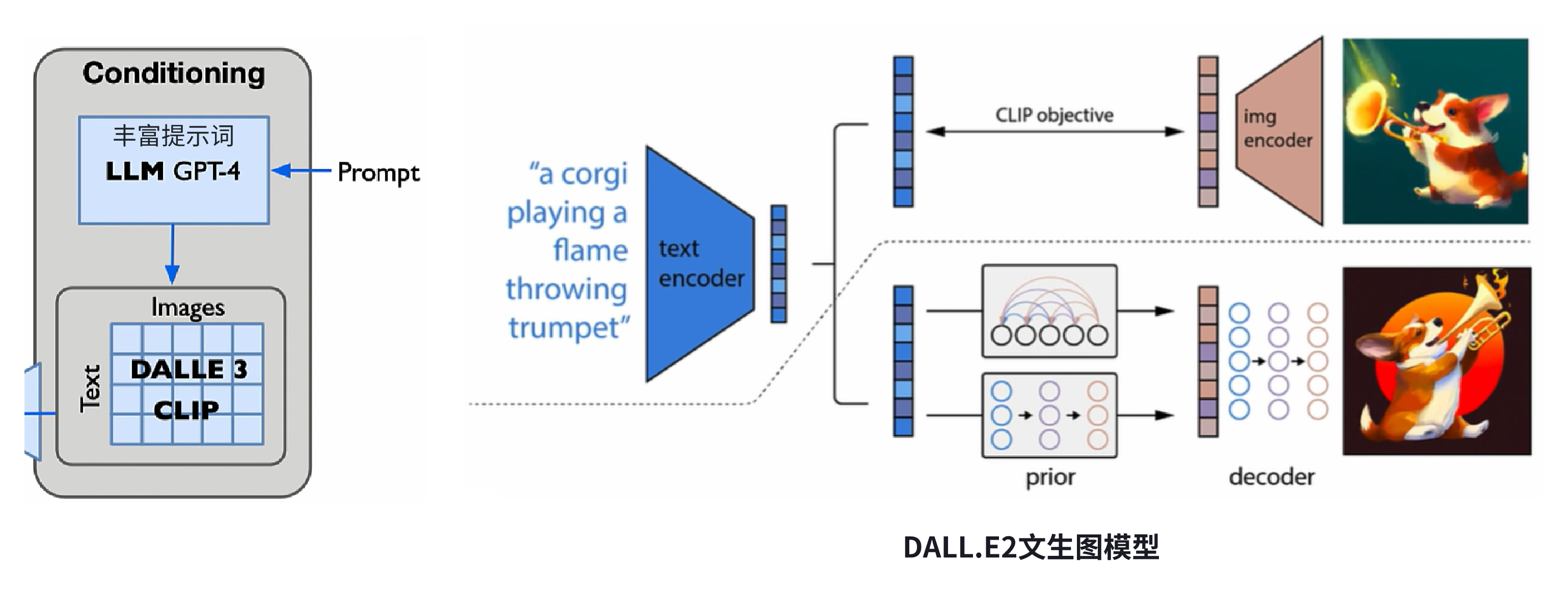
由于DALL.E3并未有相关技术论文,我们以DALL.E2来说明。上图是DALL.E2 的技术原理
分为两个阶段:prior阶段和decode阶段。
- prior阶段,该模型将文本特征作为输入,输出为图像特征。prior模型可以理解为一个文本到图像的映射关系,它能够将输入的文本描述转化为对应的图像特征表示。prior阶段采用CLIP的技术。当给定一段文本描述时,CLIP能够将其转化为对应的图像特征表示。
- decode阶段,DALL.E2将这些图像特征输入给解码器,从而生成一个完整的图像。DALL.E2采用了基于扩散模型的解码器。将prior阶段得到的图像特征作为初始条件,通过迭代扩散过程生成最终的图像。
文本编码只使用文生图模型中第一阶段的模型,将文本内容转换成对应的图像特征表示即可,该向量直接作为 DiT 扩散学习的条件输入。
根据上面的解析,我们可以得到 SORA 模型的整体训练流程:
1.视频数据通过 VAE 编码器压缩成低维空间表示;
2.原始prompt通过gpt4进行扩充,再使用 DALL.E3中CLIP模型把文本映射成图像空间的表示;
3.将视频和文本的特征输入到Diffusion Transformer中进行扩散学习;
4.DiT 生成的低维空间表示,通过 VAE 解码器恢复成像素级的视频数据。
