


LoRA论文:LoRA: Low-Rank Adaptation of Large Language Models
下面根据论文内容做一个技术分享
一、技术简介
LoRA,即低秩适应(Low-Rank Adaptation),是一种针对大型预训练语言模型的优化技术。它的目的是在不牺牲模型性能的前提下,显著减少模型的存储和计算成本。
LoRA的工作原理
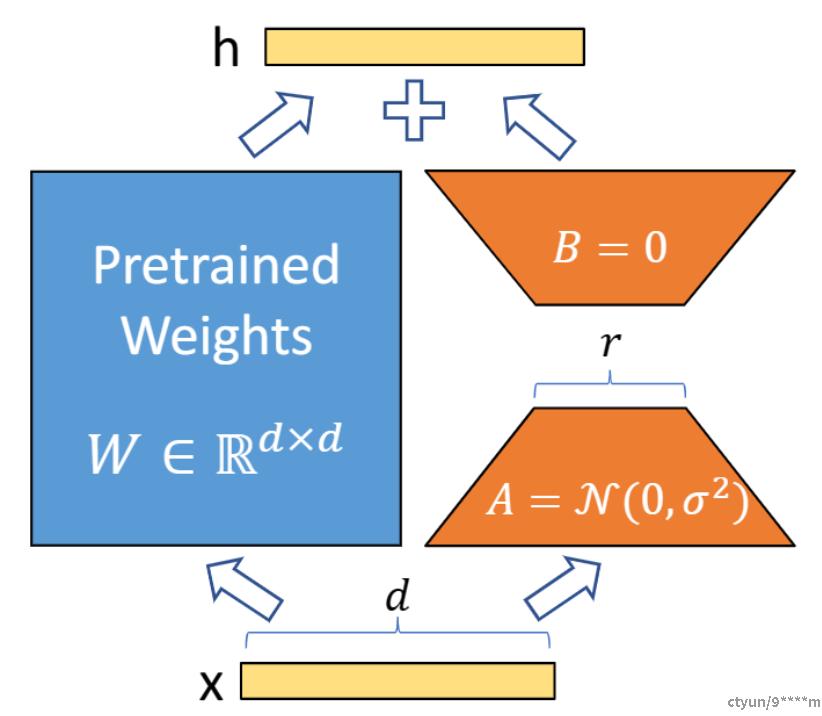
LoRA的原理可以用一个简单的数学公式来描述。假设我们有一个预训练的权重矩阵\( W \),LoRA不是直接修改\( W \),而是通过优化一个低秩的分解矩阵\( \Delta W = BA \)来调整模型,其中\( B \)和\( A \)是两个小得多的矩阵。
LoRA的技术关键点
1. 预训练权重固定:LoRA保持预训练模型的权重\( W \)不变,这样可以利用模型在预训练阶段学到的知识。
2. 注入低秩矩阵:在模型的每一层注入一个可训练的低秩矩阵\( \Delta W \),这个矩阵是通过两个低维矩阵\( B \)和\( A \)相乘得到的。
3. 参数更新:在训练过程中,我们只更新矩阵\( A \)和\( B \)中的参数,而不是整个\( W \),这样就大大减少了需要训练的参数数量。
LoRA的优势
1. 参数和存储效率:通过减少可训练参数的数量,LoRA显著降低了模型的存储需求。
2. 计算效率:由于需要训练的参数减少,LoRA也减少了训练和推理时的计算成本。
3. 无额外推理延迟:与其他一些适应技术不同,LoRA在模型部署时不会引入额外的推理延迟。
4. 灵活性:LoRA可以与多种现有方法结合使用,如前缀调整(prefix-tuning)。
LoRA的实验
在论文中,作者进行了一系列实验来验证LoRA的有效性。以下是一些关键的实验结果:
1. GLUE基准测试:LoRA在GLUE(一个广泛使用的自然语言理解基准测试)上的表现与全参数微调相当。
2. GPT-3模型:即使在参数数量减少10000倍的情况下,LoRA在GPT-3模型上的性能也与全参数微调相媲美。
3. 不同秩下的性能:实验表明,对于GPT-3模型,较小的秩(如1或2)已经足够应对多数任务。
4. 低数据环境下的性能:LoRA在数据较少的情况下也表现出了良好的性能,这表明它具有很好的样本效率。
LoRA的应用示例
假设我们有一个预训练的GPT-3模型,并且希望将其应用于情感分析任务。使用LoRA,我们可以按照以下步骤进行:
1. 固定GPT-3的预训练权重。
2. 为模型的每一层注入低秩矩阵\( A \)和\( B \)。
3. 训练注入的矩阵:使用情感分析任务的数据来训练\( A \)和\( B \),而预训练权重保持不变。
4. 模型部署:训练完成后,将\( A \)和\( B \)与原始权重合并,形成适应后的情感分析模型。
结论
LoRA技术为大型语言模型的高效利用提供了一种新的可能性。通过低秩适应,我们可以在保持模型性能的同时,显著降低模型的计算和存储成本,使得大型模型的部署和应用变得更加容易。
