


Chinese-CLIP模型:
Chinese-CLIP延续了CLIP的模型架构,使用了不同的训练方式以及全新的中文数据集,即在双流架构和对比学习的支持下,能够有效地整合中文的图像和文本信息到一个共享的嵌入空间,并拥有处理多模态数据的能力。初始阶段以预训练的方式设定了两种编码器:一种是CLIP的视觉编码器,另一种是中文版的RoBERTa文本编码器。
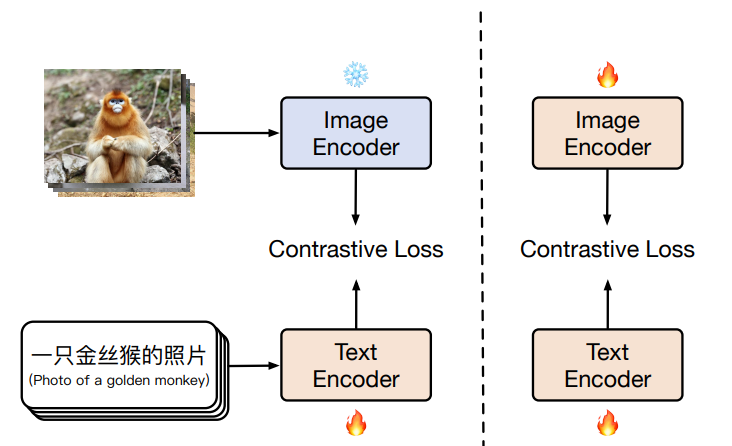
训练方式:
使用两阶段训练的方式
第一阶段:冻结 image encoder
第二阶段:image encoder 和 text encoder 都参与训练
消融实验证明了两阶段训练的好处
方法:
CLIP 的训练方法:
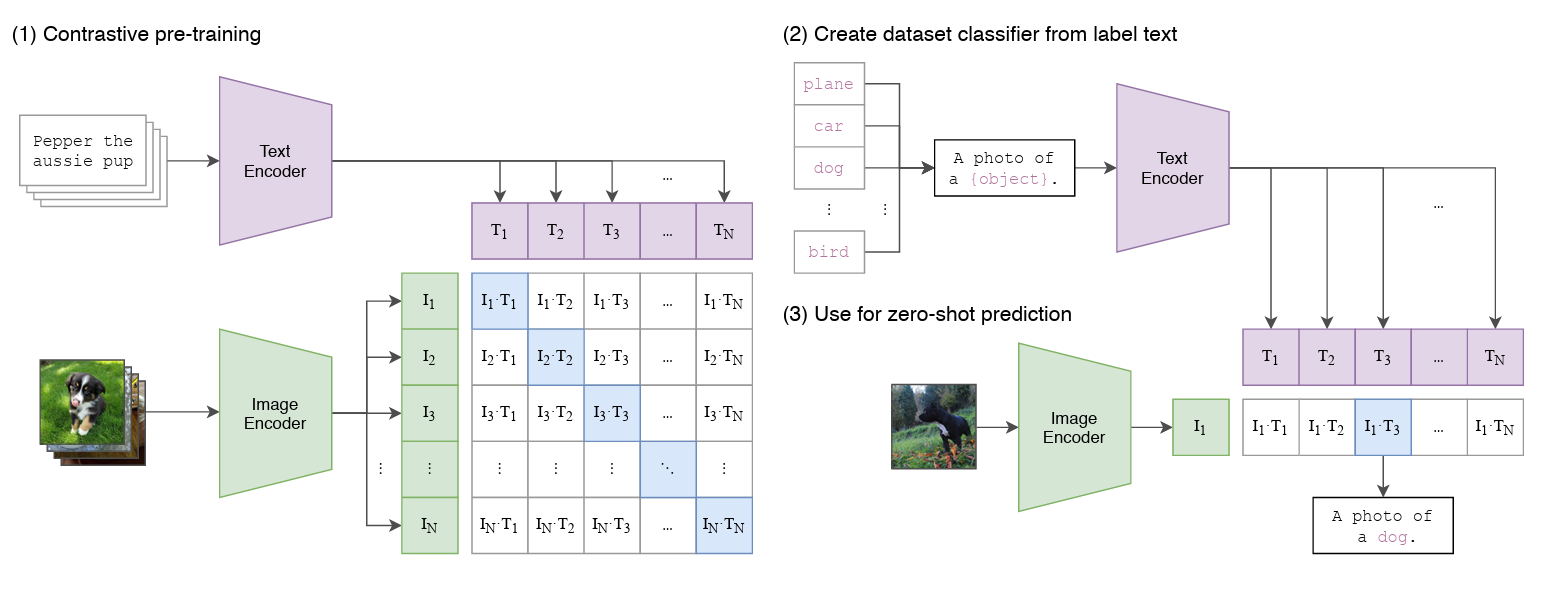
CLIP模型的架构以及训练思路,采用了对比学习的思想。预训练网络的输入是文字和图片的配对,每一张图像都有一小句解释性文字。将文字和图片分别通过一个编码器,得到向量表示。
CLIP 是由 image encoder 和 text encoder 构成的
image encoder:是 vision backbone,如 ResNet、ViT 等
text encoder:是 transformer model,如 BERT、GPT 等
训练的具体步骤:
1. 输入的text和Image分别经过各自的Encoder处理成特征向量;
2. 构建关系矩阵,矩阵中的每一个元素都是每一个Image特征向量和其他Text特征向量的余弦相似度。该矩阵中主对角线的元素都是匹配的(图像和文本特征完全对应),其他地方的元素并不匹配。使用对称交叉熵损失作为其优化目标,这种类型的损失最小化了图像到文本的方向以及文本到图像的方向。在计算对比损失时,CLIP认为在矩阵中只有对角线上的Image与Text组成的对是正样本,其余都是负样本。
3. 主对角线的余弦相似度尽可能最大,其他地方的余弦相似度尽可能最小。
CLIP 的扩展:
可以迁移到跨模态的检索,image encoder 可以作为 vision backbone 来代替在 ImageNet 上预训练的 ResNet 或 ViT,通过计算给定的 image 和固定形式 Candidate label (如 a photo of [label]) 的相似性,学习多模态的特征,进行开集的 zero-shot 分类。
Chinese-CLIP
CLIP 成功的另外一个原因在于预训练使用的超大尺度的训练集
由在 CLIP 上进行的实验可知,通过增大数据量、增长训练周期都可以提供模型在 zero-shot 学习任务上的效果
训练数据集:
从 LAION-5B 中抽取包含 ‘zh’ 的中文数据,共抽取 1.08 亿数据
从 Wukong 中获得 0.72 亿数据
将英文多模态数据翻译为中文的,包括 Visual Genome 和 MSCOCO
最后共得到约 2 亿的训练数据
一般将图像 resize 为 224x224 来使用,在 ViT-L/14 中使用 336x336 大小
预训练方法:
最简单的训练方法是从头开始训练,就是会受到训练数据的数量和质量的限制
为了利用现有的预训练模型优势:
对于 image encoder ,使用了官方 CLIP 开源预训练模型来初始化
对于 text encoder,使用 RoBERTa-wwm-ext 和 RBT3
如何基于开源模型来预训练:
constrastive tuning, 对比微调,类似于将 CLIP 迁移到下游任务上去
Locked-image Tuning(LiT),效果更好
Chinese CLIP 如何进行预训练:两阶段预训练方法,
主要思想是冻结 image encoder(冻结所有的参数)使用 LiT 让 text encoder 能够从 OpenAI 的 CLIP 的基础视觉模型中读出高质量的表示,然后将这些表示迁移到需要的数据域中。
第一阶段:冻结 image encoder 的所有参数,只训练 text encoder,这一动作是基于一个假设:训练好的 vision backbone 已经有很强的能力来抽取视觉特征了。第一阶段的训练直到对下游任务没有明显的提升而结束
第二阶段,让 image encoder 的参数参与训练,这样一来 image encoder 的参数就可以学习从中文的图了
实验结果表明两阶段的预训练能够比直接从训练好的模型来 finetune 效果更好。
