


多模态大模型是一种基于深度学习的模型,它可以同时处理多种模态的信息,例如文本、图像、音频、视频等。这些模态可以是不同的数据源,也可以是不同的表示形式,它可以利用多种模态的信息来提高模型的性能和泛化能力。
多模态模型让深度学习的效率进一步得到提升,业界认为单靠语言模型是无法实现AGI的,因为人类自身是多模态学习的生物,而且很多信息在单纯的语言中难以体现,当GPT3.5或GPT-4刚出现时,很多人觉得离AGI似乎越来越近了,但现在看来,LLM仍存在很多难以解决的问题,此外,在模型参数达到1000亿级别之后,增加更多的参数只能带来越来越小的收益,因此目前虽然大语言模型的加持必不可少,但多模态模型自身的发展和突破,才是通往通用AI(AGI)的关键。
多模态模型的实现需要多种必要条件,包括:
- 大语言模型加持,本身需要基座模型具备高参数量
- 多模态能力涌现,需要大模型去吸收海量数据所蕴含的世界知识
- 多模态模型通常需要不同模态进行特征表征后,进行模态间的对齐和加工融合,相比于文本,图像、语音的信息密度更低,模态的表征,语义对齐需要更强大的模型才能有效实现
多模态大模型解锁出新的算法能力和应用方式,具体如下:
1)5种使用方式
输入图像(images)、子图像(sub-images)、文本(texts)、场景文本(scene texts)和视觉指针(visual pointers)
2)3种能力
指令遵循(instruction following)、思维链(chain-of-thoughts)、上下文少样本学习(in-context few-shot learning)
3)10大算法任务
开放世界视觉理解(open-world visual understanding)、视觉描述(visual description)、多模态知识(multimodal knowledge)、常识(commonsense)、场景文本理解(scene text understanding)、文档推理(document reasoning)、写代码(coding)、时间推理(temporal reasoning)、抽象推理(abstract reasoning)、情感理解(emotion understanding)
多模态大模型和传统AI小模型相比,具有多种潜在优势:
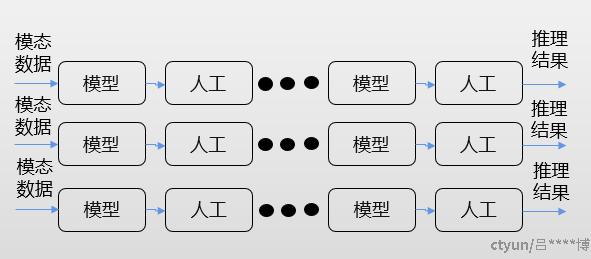
单模态小模型:
- 任务设计编排:需要多个独立的小模型,结合人工设计+阈值参数调整co-design解决
- 训练+推理:训练阶段采用从头训练,或者迁移学习;按照固定预设的逻辑进行确定性推理
- 产品能力:通常需要case by case构建AI模型专属能力,采用“烟囱式”的模型迭代开发管理
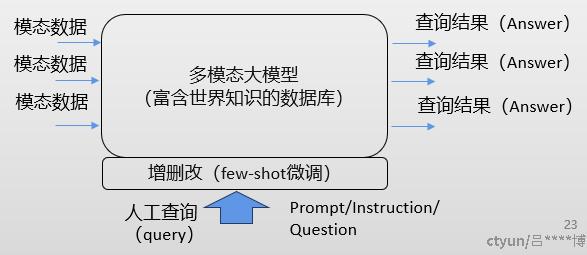
多模态大模型:
- 任务设计编排:感知+认知+决策任务大统一,多模态大模型可实现端到端隐式学习,减少人工设计引入的“归纳偏置”,具有更强的通用性
- 训练+推理:打破传统AI训练推理方式,预训练充分吸收世界知识,成为一个通用“数据库”;推理阶段通过prompt交互(类似数据库query)、现场学习、思维链方式解决
- 产品能力:更容易打造成标品,多个case源自同一个大模型“公共祖先”
目前多模态大模型呈现出百模渐欲迷人眼,AI应用繁花开的良好发展态势;在技术路线方面,主要以LLM大语言模型加持为必要条件,也是通往AGI的有效发展路径;目前已浮现出人机智能交互、现场学习和内涵理解等特有能力。与小模型相比,多模态大模型采用全新的学习框架,为多任务端到端隐式学习,模型的训练和推理方式也为之改变;未来有望在LLM应用场景下实现多模态能力的多维扩展,实现感知+认知任务的有机统一与协同整合,预测将在医疗诊断、工业质检、自动驾驶、机器人自主智能等场景进行应用落地。
