


1. Raft 基础
Raft是工程上使用较为广泛分布式共识协议,是多个节点对某个事情达成一致的看法,即使是在部分节点故障、网络延时、网络分区的情况下。
其设计原则如下:
- 容易理解
- 减少状态的数量,尽可能消除不确定性
Raft 将问题分解为:Leader 选举,日志复制,安全性,将这三个问题独立思考。
在 Raft 中,节点可能的状态有三种,其转换关系如下:

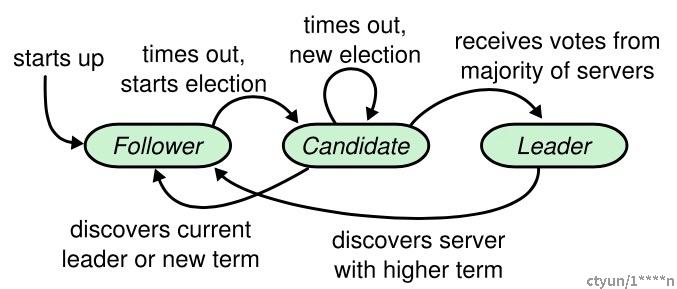
正常情况下,集群中只有一个 Leader,其他节点全是 Follower 。Follower 都是被动接收请求,从不发送主动任何请求。Candidate 是从 Follower 到 Leader的中间状态。Raft 中引入任期(term)的概念,每个 term 内最多只有一个 Leader。term在 Raft 算法中充当逻辑时钟的作用。服务器之间通信的时候会携带这个 term,如果节点发现消息中的 term小于自己的 term,则拒绝这个消息,如果大于本节点的 term,则更新自己的 term。如果一个 Candidate 或者 Leader 发现自己的任期号过期了,它会立即回到 Follower 状态。
Raft 选举流程为:
- 增加节点本地的 current term ,切换到Candidate状态
- 投自己一票
- 并行给其他节点发送 RequestVote RPC(让大家投他)。
然后等待其他节点的响应,会有如下三种结果:
- 如果接收到大多数服务器的选票,那么就变成Leader
- 如果收到来自Leader 的 RPC,转变成Follower
- 如果选举过程超时,再次发起一轮选举
通过下面的约束来确定唯一 Leader(选举安全性):
- 同一任期内,每个节点只有一票
- 得票(日志信息不旧于Candidate的日志信息)过半则当选为 Leader
成为 Leader 后,向其他节点发送心跳消息来确定自己的地位并阻止新的选举。
当同时满足以下条件时,Follower同意投票:
- RequestVote请求包含的term大于等于当前term
- 日志信息不旧于Candidate的日志信息
- first-come-first-served 先来先得
2. ES 选举流程
ES 实现的 Raft 中,选举流程与标准的有很多区别:
- 初始为 Candidate状态
- 执行 PreVote 流程,并拿到 maxTermSeen
- 准备 RequestVote 请求(StartJoinRequest),基于maxTermSeen,将请求中的 term 加1(尚未增加节点当前 term)
- 并行发送 RequestVote,异步处理。目标节点列表中包括本节点。
ES 实现中,候选人不先投自己,而是直接并行发起 RequestVote,这相当于候选人有投票给其他候选人的机会。这样的好处是可以在一定程度上避免3个节点同时成为候选人时,都投自己,无法成功选主的情况。
ES 不限制每个节点在某个 term 上只能投一票,节点可以投多票,这样会产生选出多个主的情况:

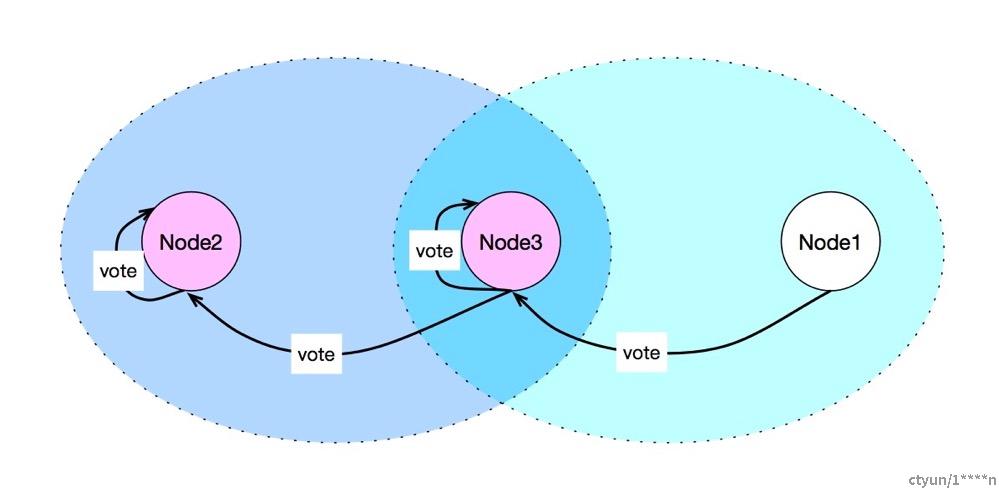
Node2被选为主:收到的投票为:Node2,Node3
Node3被选为主:收到的投票为:Node3,Node1
对于这种情况,ES 的处理是让最后当选的 Leader 成功。作为 Leader,如果收到 RequestVote请求,他会无条件退出 Leader 状态。在本例中,Node2先被选为主,随后他收到 Node3的 RequestVote 请求,那么他退出 Leader 状态,切换为CANDIDATE,并同意向发起 RequestVote候选人投票。因此最终 Node3成功当选为 Leader。
3. Raft 的 PreVote RPC
当产生网络分区,分区后的某个节点可能会永远也选不出主,例如少数节点被隔离,如下图所示:
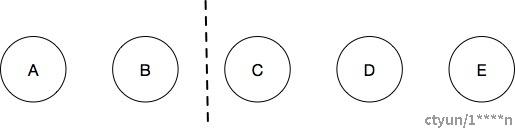

被隔离的节点会频繁尝试选举,每次都选举失败,从而导致:
- term 增长到非常大。网络恢复后传播到其他节点
- 当网络分区恢复后,由于被隔离的节点 term 已经非常大,从而导致 Leader 切换
在PreVote算法中,Candidate首先要确认自己能赢得集群中大多数节点的投票,才发起RequestVote。标准 Raft 中,其他投票节点同意发起选举的条件是:
- 当前没有 Leader
- Candidate的日志足够新(Term更大,或者Term相同raft index更大)。
Prevote是一个2PC过程,第一阶段先征求其他节点是否同意选举,如果同意选举则发起真正的选举操作,这样就避免了网络分区节点重新加入集群,触发不必要的选举操作。
其实就是候选人先检查自己的日志是否最新,如果不够新,就不要继续选举流程了,但是只考虑日志新旧程度可能不够,例如日志也足够新。因此除了 Prevote外,可以考虑另一种机制,如果Leader节点一直正常保持着与其它节点的心跳消息,那么就认为Leader节点是存活的,此时不允许发起一轮新的选举。这样Leader节点处理RequestVote请求时,就需要加上判断,除了判断候选人日志是否最新以外,如果当前还存在活跃的 Leader,那么也不允许发起新的选举。
4. ES 的 PreVote RPC
es 的实现中,其他投票节点同意发起选举的条件是:
- 候选人的 term 更大,或者:
- term 相同,候选人 的 version 不小于自己
如果候选人获得多数节点同意,则候选人可以发起 RequestVote 请求。
ES中 PreVote 请求对应的 RPC 为:REQUEST_PRE_VOTE_ACTION_NAME,请求封装在类:PreVoteRequest
候选人在发起 RequestVote 之前,并行给其他节点发送 PreVote RPC(包括自己)。在周期性执行的选举任务中,触发 PreVote 流程 preVoteCollector.start(…),
Arguments:
currentTerm: 候选人的 term
Response:
选民对请求的响应信息封装在类: PreVoteResponse
currentTerm:Receiver节点的当前 term,候选人用于 updateMaxTermSeen
lastAcceptedTerm:当前集群状态中存储的 term。ClusterState::term()
lastAcceptedVersion:当前集群状态中的版本号。ClusterState::version()
Receiver implementation
- 更新自己看到的最大 term:maxTermSeen
- 如果自己是 Leader,而maxTermSeen 大于 currentTerm,则辞去 Leader,尝试开始新一轮选举
- 如果节点认为集群已存在一个 Leader,而这个 Leader 并非发起 PreVote节点,则返回异常
注:第1,2步为 updateMaxTermSeen函数
Candidate implementation:
候选人发送 PreVote请求后,等待response,对收到response进行处理,保留满足条件的response进行统计,当满足条件的response达到多数,并行发送 RequestVote(包括自己),这些检查条件如下:
- 调用 updateMaxTermSeen,主要是更新了 maxTermSeen
- 如果response 中lastAcceptedTerm大于当前集群状态中的 term,则忽略此response
- 如果response 中lastAcceptedTerm等于当前集群状态中的 term,且lastAcceptedVersion大于当前集群状态中的 version,则忽略此response
为什么使用集群状态中的 term 和 version 进行对比?因为候选人自己的当前 term 可能是非常大的,因为他可能因为网络分区被隔离。
ES 实现的 PreVote 是候选人检查自己集群状态是否最新,以及集群状态中保存的 term 是否最新,如果不够新,就不发起选举了。
5. ES 的 RequestVote RPC
对应 ES 中的 RPC 为:START_JOIN_ACTION_NAME,请求封装的对应类为:StartJoinRequest
选民发出投票的 RPC 为:JOIN_ACTION_NAME,封装的对应类为 JoinRequest,核心信息为 Join 类。
Arguments:
term:取值为 Math.max(getCurrentTerm(), maxTermSeen) + 1
Response:
此处的 Response 指选民同意投票时发出的投票请求,ES 中的 RPC 为 JOIN_ACTION_NAME ,请求封装类为:Join
currentTerm:Receiver节点的当前 term
lastAcceptedTerm:当前集群状态中存储的 term。ClusterState::term()
lastAcceptedVersion:当前集群状态中的版本号。ClusterState::version()
Receiver implementation
- 如果请求中的 term 小于等于节点当前 term,则拒绝该请求。因为请求中的 term 应该是最大 term 加1的,所以他应该大于节点当前 term。
- 如果当前不是CANDIDATE状态,则切换为 CANDIDATE,哪怕他是 Leader。
- 发出投票
Receiver的主要实现是 joinLeaderInTerm 函数。
只要收到 RequestVote,并且 term 没问题,节点就会投票,不限制每个节点只能投1票。如果是 Leader 收到 RequestVote,他会退出 Leader 状态。这通常产生在多个候选人同时竞选的时候。当集群存在一个活跃 Leader 时,PreVote 会阻止其他候选人的竞选行为。
小细节:当选民发出投票,在没有收到成功或失败的回复之前,如果再次收到该节点在相同 RequestVote 中的请求,不会再次为其投票。
final Tuple<DiscoveryNode, JoinRequest> dedupKey = Tuple.tuple(destination, joinRequest);
if (pendingOutgoingJoins.add(dedupKey)) {
transportService.sendRequest(...)
}
Candidate implementation:
1.构建 RequestVote 请求,此请求在 ES 中封装为 StartJoinRequest 类,依据 Prevote 中的 maxTermSeen,取节点当前 term 与maxTermSeen的最大值并加1:
final StartJoinRequest startJoinRequest
= new StartJoinRequest(getLocalNode(), Math.max(getCurrentTerm(), maxTermSeen) + 1);
标准的 raft 增加本节点 term后发送RequestVote,ES 中实现的并没有增加本节点 term,只是把 RequestVote 请求中的 term 递增。
2.并行给其他节点发送 RequestVote RPC,其中包括本节点。
然后等待投票请求:
1.如果收到的投票请求中的 term不等于节点当前 term,则拒绝请求。(这里可能有问题?只有选民收到拉选票请求时才更新自己的 term,虽然候选人也可以投自己,但 RequestVote 并行发送,本地节点未必先处理。)
2.如果收到的投票请求中的 lastAcceptedTerm 大于本节点的lastAcceptedTerm,则拒绝请求。(候选人的 term 非最新,他会因为收集不到过半的 Join 而失败。)
3.如果 请求中的lastAcceptedTerm与本节点的lastAcceptedTerm相同,且请求中的 LastAcceptedVersion 大于本节点的 LastAcceptedVersion,则拒绝请求。
4.如果得票数量过半,则选主成功
5.发布集群 状态“elected-as-master”
6.如果集群状态发布失败,则切换到 Candidate状态
7.任意时刻(不只是选主期间),只要节点收到其他Master 发来的集群状态,自己就切换为 Follower
8.如果选举超时,则重新开始选举,ES的实现方式是在ElectionSchedulerFactory.ElectionScheduler#scheduleNextElection中通过递归调用周期性地执行选举,大约1秒执行一次,delay 时间取决于:
cluster.election.duration
cluster.election.initial_timeout–>initialTimeout
cluster.election.max_timeout–>maxTimeout
cluster.election.back_off_time–>backoffTime
等配置信息,delayMillis是周期执行选举的间隔时间:
final long maxDelayMillis = Math.min(maxTimeout.millis(), initialTimeout.millis() + thisAttempt * backoffTime.millis());
final long delayMillis = toPositiveLongAtMost(random.nextLong(), maxDelayMillis) + gracePeriod.millis();
在周期性的执行选举过程中,ES 通过 synchronized避免选举过程被并行执行,选举过程在 geneic线程池执行。个人感觉如果选举周期过短,或者选举的某个过程阻塞时间太长,线程池会被选举的锁抢占完,所以上面计算的延迟时间 delayMillis就比较关键,每次触发选举,延迟时间都会递增1倍的backoffTime时间。这是一种退避机制。
6. ES 的状态转换流程
初始为Candidate状态,如果discovery发现集群已经存在 Leader,则直接加入集群,切换到 Follower 状态。如果Candidate收到足够的投票,则转换为 Leader。当一个 Leader 收到 RequestVote,或者发现了更高的 term,则辞去 Leader,切换为Candidate。
Leader 不能直接变成 Follower,他需要先切换到 Candidate

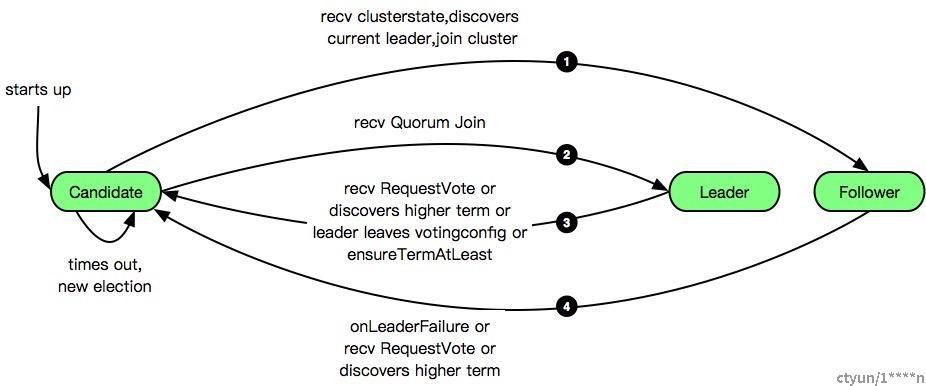
从Leader 或 Follower 切换到Candidate
这种切换与节点当前状态无关,遇到以下情况时,切换到Candidate状态
- 收到其他节点发来的 RequestVote 请求,无论当前是什么状态,都切换到 Candidate
- 收到集群状态时,handlePublishRequest中,调用ensureTermAtLeast检查集群状态中的 term,如果本节点 term 小于收到的集群状态中的 term,则切换到Candidate,并使用集群状态中的 term 替换本节点 term
Line 1,从Candidate切换到Follower
节点启动时,Node.start 调用 discovery.startInitialJoin() ,初始化为 becomeCandidate 状态。
如果 discovery 模块探测到的节点数量已达到多数(包括本节点),则触发选举流程Coordinator.CoordinatorPeerFinder#onFoundPeersUpdated函数中:
final CoordinationState.VoteCollection expectedVotes = new CoordinationState.VoteCollection();
foundPeers.forEach(expectedVotes::addVote);
expectedVotes.addVote(Coordinator.this.getLocalNode());
final ClusterState lastAcceptedState = coordinationState.get().getLastAcceptedState();
final boolean foundQuorum = CoordinationState.isElectionQuorum(expectedVotes, lastAcceptedState);
if (foundQuorum) {
if (electionScheduler == null) {
startElectionScheduler();
}
} else {
closePrevotingAndElectionScheduler();
}
节点启动时,会触发一次 onFoundPeersUpdated,其他时候当集群节点发生变化的时候应该也会调用。选举流程只在集群节点达到多数的时候才会进行,不足多数时,会将已存在的选举过程停止掉(如果有的话)。
既然节点初始为Candidate,那如果集群已经选主成功,节点要加入现有集群怎么办?这主要在节点发现层面的 PeerFinder 实现,PeerFinder如果发现了一个 Master 节点,就会执行 onActiveMasterFound ,调用 joinLeaderInTerm构造一个选票,然后 sendJoinRequest加入现有集群。
节点启动后,选举线程是独立执行的,他不考虑PeerFinder是否已经发现了主节点。当 PeerFinder发现现有主节点,加入集群,收到第一次集群状态后,handlePublishRequest函数中,节点切换到 Follower 状态,并结束周期性的选举:
closePrevotingAndElectionScheduler()->
electionScheduler.close()
Line 2,从Candidate切换到Leader
只有当Candidate收到了多数节点的投票,才切换到 Leader
Line 3,从 Leader 切换到 Candidate
从 Leader 切换到 Candidate,有非常多的情况,包括:
1.updateMaxTermSeen中,发现其他节点的 term 比自己的更高,例如收到其他节点发来的 PreVote
2.abdicateTo函数,集群状态发布成功后,如果集群状态中last_committed_config以及 last_accepted_config都不含有当前节点,则becomeCandidate,这里与动态维护的投票配置有关。参考 ”集群如何动态维护参与选举的节点列表“一节
3.ensureTermAtLeast一节图里的一堆调用
Line 4,从Follower切换到Candidate
- leaderChecker探测到Leader 失效,则 becomeCandidate
- Follower 检查 Leader 发来的FollowerCheckRequest,调用ensureTermAtLeast检查请求中的 term,如果本节点 term 小于请求中的 term,则切换到Candidate
ES 对 term 的增加采取+1方式递增,term 为 long 型。接下来我们看一下 term 都在哪些情况下会增加。
7. ES 里 term 更新时机
term 增加时机
只有候选人发起拉选票的时候才会增加 term
1.final StartJoinRequest startJoinRequest
= new StartJoinRequest(getLocalNode(), Math.max(getCurrentTerm(), maxTermSeen) + 1);
2.final StartJoinRequest startJoinRequest = new StartJoinRequest(newMaster, Math.max(getCurrentTerm(), maxTermSeen) + 1);
节点更新本地 term 时机
1.选民收到候选人拉选票的请求RequestVote时,将拉选票请求中的 term 更新到本地逻辑时钟。handleStartJoin函数,:
persistedState.setCurrentTerm(startJoinRequest.getTerm());
2.节点应用集群状态,将收到的集群状态持久化之前,如果集群状态中的 term 大于当前 term,则更新本地 term。applyClusterState函数:
if (event.state().term() > getCurrentTerm()) {
innerSetCurrentTerm(event.state().term());
}
3.涉及到 ensureTermAtLeast的检查,参考ensureTermAtLeast一节
我们知道 term 在 Raft 中充当逻辑时钟的作用,服务器间通讯时需要携带 term,节点需要对 term 执行检查,并进行相应的处理,下面我们就来看下在 ES 的实现中, term 都存在于哪些请求,以及节点对请求中的 term 是如何检查、处理的。
Term 存在于哪些请求中?
- 候选人发起RequestVote 的拉选票请求中:StartJoinRequest,RPC 为:START_JOIN_ACTION_NAME
- Master 发布集群状态时,集群状态中:clusterState.term(),集群发布由于是2PC,RPC有两个:PUBLISH_STATE_ACTION_NAME,COMMIT_STATE_ACTION_NAME
8. 对请求中 term 的检查逻辑
选举环节
1.选民处理候选人发来的 RequestVote 请求,如果请求中的 term 小于等于节点当前 term,则拒绝。 CoordinationState::handleStartJoin
//选民处理要求投票的请求。由于候选人在发起 StartJoinRequest 的时候将 term+1了,因此请求中的 term 应该大于本节点 term
if (startJoinRequest.getTerm() <= getCurrentTerm()) {
logger.debug("handleStartJoin: ignoring [{}] as term provided is not greater than current term [{}]",
startJoinRequest, getCurrentTerm());
throw new CoordinationStateRejectedException("incoming term " + startJoinRequest.getTerm() +
" not greater than current term " + getCurrentTerm());
}
2.候选人处理投票请求,如果所投的票term不等于当前 term,则拒绝请求。 CoordinationState::handleJoin
if (join.getTerm() != getCurrentTerm()) {
logger.debug("handleJoin: ignored join due to term mismatch (expected: [{}], actual: [{}])",
getCurrentTerm(), join.getTerm());
throw new CoordinationStateRejectedException(
"incoming term " + join.getTerm() + " does not match current term " + getCurrentTerm());
}
集群状态发布环节
1.Master 开始发布集群状态时的前期验证,如果clusterState 中的 term不等于当前 term,则取消发布集群状态。Coordinator::publish
if (mode != Mode.LEADER || getCurrentTerm() != clusterChangedEvent.state().term()) {
logger.debug(() -> new ParameterizedMessage("[{}] failed publication as node is no longer master for term {}",
clusterChangedEvent.source(), clusterChangedEvent.state().term()));
publishListener.onFailure(new FailedToCommitClusterStateException("node is no longer master for term " +
clusterChangedEvent.state().term() + " while handling publication"));
return;
}
2.Master 发布集群状态第一阶段,如果clusterState 中的 term不等于当前 term,则取消发布集群状态。CoordinationState::handleClientValue
if (clusterState.term() != getCurrentTerm()) {
logger.debug("handleClientValue: ignored request due to term mismatch " +
"(expected: [term {} version >{}], actual: [term {} version {}])",
getCurrentTerm(), lastPublishedVersion, clusterState.term(), clusterState.version());
throw new CoordinationStateRejectedException("incoming term " + clusterState.term() + " does not match current term " +
getCurrentTerm());
}
3.节点收到 Master 节点发来的集群状态,在二段提交的第一阶段: CoordinationState::handlePublishRequest 中,如果 clusterState 中的 term 不等于当前 term ,则拒绝该请求。
if (clusterState.term() != getCurrentTerm()) {
logger.debug("handlePublishRequest: ignored publish request due to term mismatch (expected: [{}], actual: [{}])",
getCurrentTerm(), clusterState.term());
throw new CoordinationStateRejectedException("incoming term " + clusterState.term() + " does not match current term " +
getCurrentTerm());
}
以及这个 response 中可能含有 join 请求 PublishResponseHandler:
if (response.getJoin().isPresent()) {
final Join join = response.getJoin().get();
assert discoveryNode.equals(join.getSourceNode());
assert join.getTerm() == response.getPublishResponse().getTerm() : response;
logger.trace("handling join within publish response: {}", join);
onJoin(join);
}
onJoin()->
handleAssociatedJoin() 函数实现见下(4)
4.Master 发布集群状态时,对第一阶段收到的回复进行处理时,如果 Response 的 term 不等于当前 term,则拒绝请求。 CoordinationState::handlePublishResponse
if (publishResponse.getTerm() != getCurrentTerm()) {
logger.debug("handlePublishResponse: ignored publish response due to term mismatch (expected: [{}], actual: [{}])",
getCurrentTerm(), publishResponse.getTerm());
throw new CoordinationStateRejectedException("incoming term " + publishResponse.getTerm()
+ " does not match current term " + getCurrentTerm());
}
以及:
Coordinator::CoordinatorPublication()::handlePublishResponse()
protected Optional<ApplyCommitRequest> handlePublishResponse(DiscoveryNode sourceNode,
PublishResponse publishResponse) {
assert Thread.holdsLock(mutex) : "Coordinator mutex not held";
assert getCurrentTerm() >= publishResponse.getTerm();
return coordinationState.get().handlePublishResponse(sourceNode, publishResponse);
}
5.同理,节点收到 Master 节点发来的集群状态,在处理二段提交的第二阶段: CoordinationState::handleCommit 中,如果 clusterState中的 term 不等于当前 term,则拒绝该请求。
if (applyCommit.getTerm() != getCurrentTerm()) {
logger.debug("handleCommit: ignored commit request due to term mismatch " +
"(expected: [term {} version {}], actual: [term {} version {}])",
getLastAcceptedTerm(), getLastAcceptedVersion(), applyCommit.getTerm(), applyCommit.getVersion());
throw new CoordinationStateRejectedException("incoming term " + applyCommit.getTerm() + " does not match current term " +
getCurrentTerm());
}
if (applyCommit.getTerm() != getLastAcceptedTerm()) {
logger.debug("handleCommit: ignored commit request due to term mismatch " +
"(expected: [term {} version {}], actual: [term {} version {}])",
getLastAcceptedTerm(), getLastAcceptedVersion(), applyCommit.getTerm(), applyCommit.getVersion());
throw new CoordinationStateRejectedException("incoming term " + applyCommit.getTerm() + " does not match last accepted term " +
getLastAcceptedTerm());
}
term 校验贯穿集群状态发布的整个过程,值得注意的是,2PC 第二阶段,master 发送 commit 请求sendApplyCommit,以及master 对 commit response 的处理ApplyCommitResponseHandler中,并不检查 term
6.集群状态发布完毕之后,无论成功还是失败,调用 Publication::onPossibleCompletion()->
onCompletion()->handleAssociatedJoin()
private void handleAssociatedJoin(Join join) {
if (join.getTerm() == getCurrentTerm() && hasJoinVoteFrom(join.getSourceNode()) == false) {
logger.trace("handling {}", join);
handleJoin(join);
}
}
7.isActiveForCurrentLeader 发布集群状态时,如果某个节点发布失败,Master检查当前是否满足 Master 条件:CoordinatorPublication::removePublicationAndPossiblyBecomeCandidate中调用 isActiveForCurrentLeader
boolean isActiveForCurrentLeader() {
// checks if this publication can still influence the mode of the current publication
return mode == Mode.LEADER && publishRequest.getAcceptedState().term() == getCurrentTerm();
}
FollowerChecker
1.Coordinator::onFollowerCheckRequest Follower 收到 Leader 发来的心跳检查时,如果当前 term 不等于请求中的 term ,则拒绝请求。Leader 会收到一个异常的 Response,当节点的错误次数超过阈值后,将节点标记为异常。
if (getCurrentTerm() != followerCheckRequest.getTerm()) {
logger.trace("onFollowerCheckRequest: current term is [{}], rejecting {}", getCurrentTerm(), followerCheckRequest);
throw new CoordinationStateRejectedException("onFollowerCheckRequest: current term is ["
+ getCurrentTerm() + "], rejecting " + followerCheckRequest);
}
但是 LeaderChecker不会检查 term,LeaderCheckRequest的请求中也不包含 term。Leader 不检查自己的 term 是否落后于 Follower。对 Leader 的检查是很宽容的。
/**
* The LeaderChecker is responsible for allowing followers to check that the currently elected Leader is still connected and healthy. We are
* fairly lenient, possibly allowing multiple checks to fail before considering the Leader to be faulty, to allow for the Leader to
* temporarily stand down on occasion, e.g. if it needs to move to a higher term. On deciding that the Leader has failed a Leader will
* become a Candidate and attempt to become a Leader itself.
*/
2.如果本节点 term 小于请求中的 term,则 becomeCandidate
ensureTermAtLeast(followerCheckRequest.getSender(), followerCheckRequest.getTerm());
ensureTermAtLeast
ensureTermAtLeast检查节点当前 term 是否小于目标 term,如果小于,则执行 joinLeaderInTerm,构造一个投票,保存到lastJoin,并切换到 Candidate状态。在构造投票的handleStartJoin过程中,会使用目标 term 更新本节点的term值,且持久化(在ensureTermAtLeast->joinLeaderInTerm->handleStartJoin过程中)。
private Optional<Join> ensureTermAtLeast(DiscoveryNode sourceNode, long targetTerm) {
if (getCurrentTerm() < targetTerm) {
return Optional.of(joinLeaderInTerm(new StartJoinRequest(sourceNode, targetTerm)));
}
return Optional.empty();
}
调用 ensureTermAtLeast执行检查的点比较多:

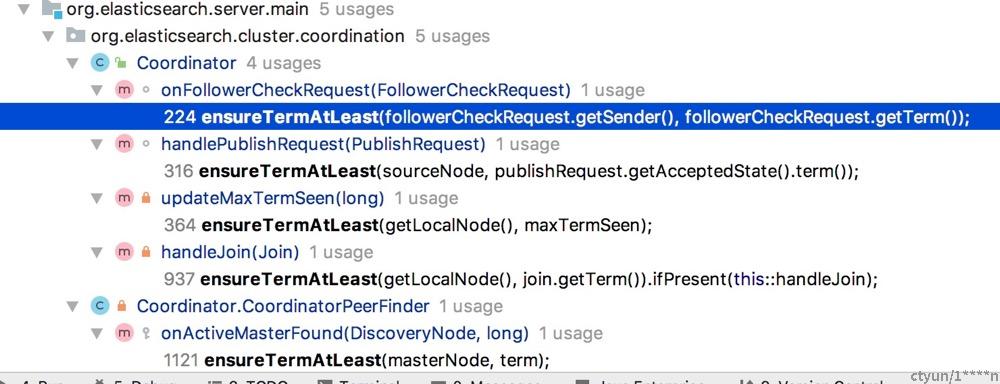
下面一一说明:
- Coordinator#onFollowerCheckRequest,Follower 检查 Leader 发来的FollowerCheckRequest,调用ensureTermAtLeast检查请求中的 term,如果本节点 term 小于请求中的 term,则切换到Candidate,更新本地 term
-
Coordinator#handlePublishRequest, 收到集群状态时,handlePublishRequest调用ensureTermAtLeast检查集群状态中的 term,如果本节点 term 小于收到的集群状态中的 term,则切换到Candidate,更新本地 term
-
Coordinator#updateMaxTermSeen,如果发现其他节点的 term 比自己的更高,则切换到Candidate,更新本地 term。例如收到其他节点发来的 PreVote
-
Coordinator#handleJoin,候选人处理投票请求,调用 ensureTermAtLeast,如果节点当前 term 小于所投票中的 term,则切换到Candidate,更新本地 term
-
CoordinatorPeerFinder#onActiveMasterFound,当节点发现模块PeerFinder探测到已存在的 master 时,调用ensureTermAtLeast,如果节点当前 term 小于 master 的 term,则切换到Candidate(加入集群,收到集群状态后,切换到 Follower),更新本地 term
9. 动态维护参与选举的节点列表(集群成员变化)
在此之前,我们讨论的前提是在集群节点数量不变的情况下,现在考虑下集群扩容,缩容,节点临时或永久离线时是如何处理的。在7.x 之前的版本中,用户需要手工配置 discovery.zen.minimum_master_nodes,来明确告诉集群过半节点数应该是多少,并在集群扩缩容时调整他。现在,集群可以自行维护。
投票配置
在取消了discovery.zen.minimum_master_nodes配置后,ES 如何判断多数?是自己计算和维护minimum_master_nodes值么?不,现在的做法不再记录“quorum” 的具体数值,取而代之的是记录一个节点列表,这个列表中保存所有具备 master 资格的节点(有些情况下不是这样,例如集群原本只有1个节点,当增加到2个的时候,这个列表维持不变,因为如果变成2,当集群任意节点离线,都会导致无法选主。这时如果再增加一个节点,集群变成3个,这个列表中就会更新为3个节点),称为 VotingConfiguration,他会持久化到集群状态中。
在节点加入或离开集群之后,Elasticsearch会自动对VotingConfiguration做出相应的更改,以确保集群具有尽可能高的弹性。在从集群中删除更多节点之前,等待这个调整完成是很重要的。你不能一次性停止半数或更多的节点。
通过下面的命令查看集群当前的 VotingConfiguration
curl -X GET "localhost:9200/_cluster/state?filter_path=metadata.cluster_coordination.last_committed_config&pretty"
默认情况下,ES 自动维护VotingConfiguration,有新节点加入的时候比较好办,但是当有节点离开的时候,他可能是暂时的重启,也可能是永久下线。你也可以人工维护 VotingConfiguration,配置项为:cluster.auto_shrink_voting_configuration,当你选择人工维护时,有节点永久下线,需要通过 voting exclusions API 将节点排除出去。如果使用默认的自动维护VotingConfiguration,也可以使用 voting exclusions API 来排除节点,例如一次性下线半数以上的节点。
如果在维护VotingConfiguration时发现节点数量为偶数,ES 会将其中一个排除在外,保证 VotingConfiguration是奇数。因为当是偶数的情况下,网络分区将集群划分为大小相等的两部分,那么两个子集群都无法达到“多数”的条件。
ES 可以在集群节点增减的时候自动维护VotingConfiguration,但是他需要一个初始化配置,也就是说在第一次的时候你必须明确告诉 ES,VotingConfiguration中都有哪些节点。其他的 Raft 实现也都有类似的要求。这就产生了“集群引导”的概念
集群引导
集群引导需要配置 cluster.initial_master_nodes 字段,将具备 master 资格的节点都配置进去,官方的说法是你可以在单个节点上配置,并且字段里只配置一个节点,但不建议这么做,除了官方提及的容错性问题,个人认为还会导致较长的初次选举时长,你要知道判断是否选举成功是要依赖这个列表中节点个数的。因此推荐将具备 master 资格的节点全都配置进去。在每个节点上,该字段的配置应该相同,还是因为要以此列表的size判断“多少”才是多数。如果每个节点认为的“多数”不一致,就可能会形成多个集群。
cluster.initial_master_nodes配置只在集群引导时使用1次,后续启动节点时将忽略此配置,如果你有一个新节点要加入现有集群,也无需配置这个字段。
动态更新VotingConfiguration
判断选主是否成功的时候,依据收到投票与VotingConfiguration进行比较,VotingConfiguration中维护了集群节点(具备 master 资格的)列表nodeIds
现在我们讨论下 ES 自行维护VotingConfiguration是如何实现的。以下当我们讨论到“节点”时,特指具备 Master 资格的节点。
当有节点加入,或离线时,ES 需要根据一些信息计算新的VotingConfiguration,这个过程需要依赖一些已知信息,包括:
- liveNodeIds 当前集群活跃节点
- currentConfig.getNodeIds() 当前投票配置中的节点
- retiredNodeIds 通过voting exclusions API 排除的节点
- currentMaster 当前 master 节点
根据这些输入信息,计算出以下几个列表:
- nonRetiredInConfigLiveNotMasterIds 不在排除列表中,在当前投票配置中,活跃的,且不含当前 master 的节点列表
- nonRetiredInConfigLiveMasterIds 不在排除列表中,在当前投票配置中,活跃的,master 节点列表,这个列表里只有一个节点,要么是空,要么是当前 master
- nonRetiredLiveNotInConfigIds 不在排除列表中,活跃的,不在当前投票配置中的节点列表
- nonRetiredInConfigNotLiveIds 不在排除列表中,在当前投票配置中,不活跃的节点列表
计算过程的实现为 coordination.Reconfigurator#reconfigure 过程如下图所示:

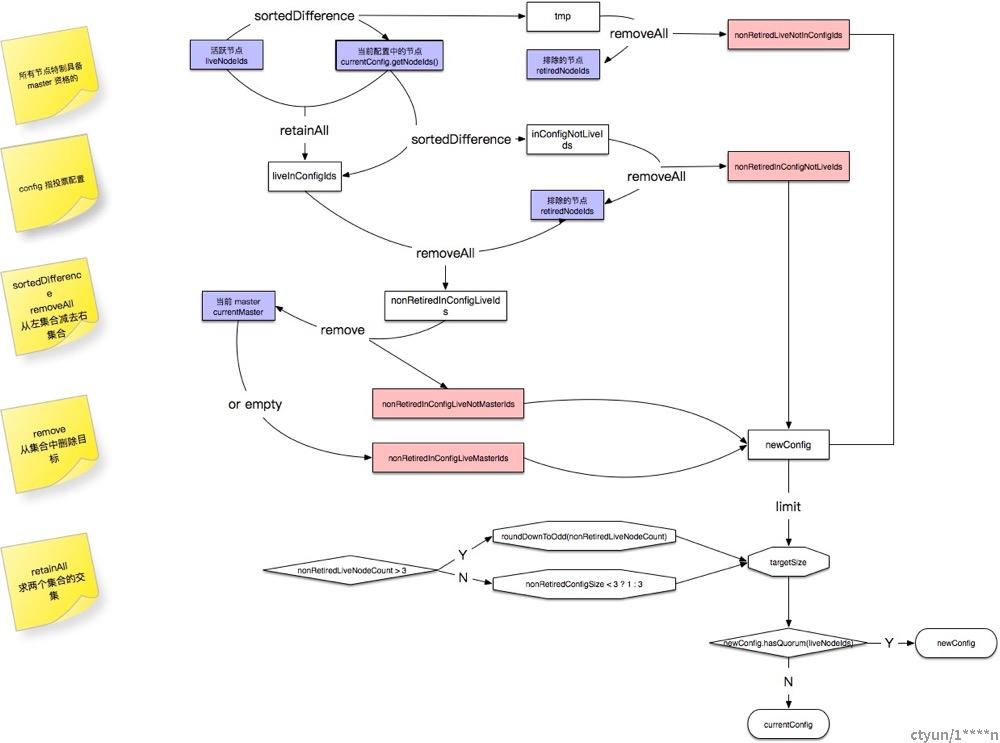
整体来看,计算过程需要先计算出上述4个列表,然后计算出一个新投票配置中所需的节点个数targetSize,将4个列表合并,按targetSize输出新的投票配置 newConfig
根据已知信息计算4个列表是一个不变的过程。不详细描述。目标节点数 targetSize 取决于几个因素:
- 节点数量是否3个及以上?
- 是否配置了排除的节点 ?
- 当前的活跃节点数 有多少?
- 最终需要保证节点个数为奇数,如果是偶数,就排除1个
我们通过最简单的情况来了解一下这个过程的核心思想。核心思想之外的小环节只是多加一些判断而已。
假设没有配置排除的节点,也不考虑奇数偶数,那么计算 targetSize 无外乎两种情况:
- 当集群规模大于等于3时,目标节点数就是活跃节点数量
- 集群规模小于3的时候,就取决于当前配置的节点数,如果小于3,目标节点数就是1,否则等于3
集群节点数小于3的时候要特殊处理,其实就节点数量为2的时候怎么办,如果集群节点数量为2,配置里真的写2个,那么当任意节点离线的时候,将会导致无法选举成功,因此这种情况需要将节点保持为1个。
同样,在不考虑排除节点的情况下,新的投票配置节点列表应该包含:
- 当前投票配置中的所有节点
- 不在当前投票配置中的活跃节点
最后,计算出的 newConfig 数量如果相对于原来投票配置来说能够达到多数,就确定 newConfig 为新的投票配置,否则使用原有的投票配置。
更新集群列表VotingConfiguration有两个时机:
1.启动的时候从集群状态中加载:MetaStateService::loadFullState()
2.状态发布成功的时候、以及有新节点加入集群的时候更新:Reconfigurator::reconfigure
集群状态中对应的结构为:
"cluster_coordination" : {
"term" : 125,
"last_committed_config" : [
"3zkYvb-9TAOGzNztHRvvXA"
],
"last_accepted_config" : [
"3zkYvb-9TAOGzNztHRvvXA"
],
"voting_config_exclusions" : [ ]
},
last_committed_config和last_accepted_config就是VotingConfiguration列表。
两者的关系是什么?这是Raft 中关于集群成员变化时的处理方式,参考 Raft 协议第6节。当使用新的投票配置替代旧的投票配置时,集群会在某个时期同时存在新旧两种配置,这会导致脑裂:

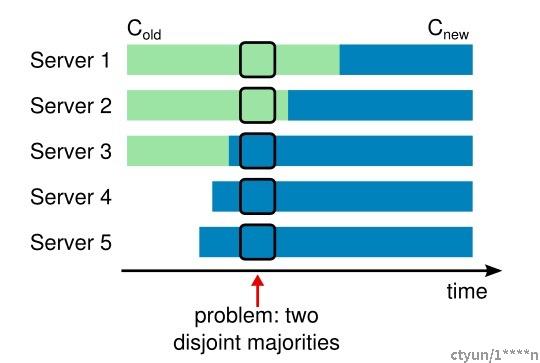
在这个例子中,集群配额从 3 台机器变成了 5 台。不幸的是,存在这样的一个时间点,两个不同的领导人在同一个任期里都可以被选举成功。一个是通过旧的配置,一个通过新的配置。
Raft 使用两阶段来完成从旧配置到新配置的转换,引入一个中间状态,在这个中间状态,同时存储新旧两种配置,达成一致(针对选举和提交)需要分别在两种配置上获得大多数的支持。
ES 本身就是通过二段提交的方式来变更集群状态,分为应用阶段和提交阶段。而 VotingConfiguration就存储在集群状态中,但是如果VotingConfiguration只有1份,仅仅通过二段提交无法保证避免这个问题,原因是各个节点在 commit 这个集群状态的时候不在同一个时间点。因此这里延用 Raft 提供的方案,在新旧配置转化过程中, 引入一个”共同一致“配置 C-old,new 实际上就是将新旧配置都存储,判断是否达到法定数量时,需要在两种配置上都成功。
- last_accepted_config 代表二段提交第一阶段,节点收到的投票配置
- last_committed_config 当节点收到 master 发来的二段提交第二阶段的请求时,将last_accepted_config中的值替换到last_committed_config中。
ES 7.x 之前的版本中,在第一阶段是不对集群状态进行持久化的,只保存在节点的内存中,但是 Raft 这种实现方式需要在第一阶段就将投票配置持久化。因为如果不持久化,如果节点重启,会丢失新的投票配置,重启后的节点使用旧的投票配置,就会导致可能的脑裂。因此ES 7.x 的实现中,将第一阶段的集群状态进行了持久化。
10. 如何判断达到多数
由于:
同时存储新旧两种配置,达成一致(针对选举和提交)需要分别在两种配置上获得大多数的支持。
因此,判断达到多数的依据就是:当获得的投票与LastCommittedConfiguration以及LastAcceptedConfiguration中节点的交集,相对于LastCommittedConfiguration或LastAcceptedConfiguration都达到多数时,此时认为达到多数。
依据节点已获得的投票votes,以及lastAcceptedState进行比较,当依据 LastCommittedConfiguration 和 LastAcceptedConfiguration判断都达到多数,则认为Quorum成立
static boolean isElectionQuorum(VoteCollection votes, ClusterState lastAcceptedState) {
return votes.isQuorum(lastAcceptedState.getLastCommittedConfiguration())
&& votes.isQuorum(lastAcceptedState.getLastAcceptedConfiguration());
}
下面以 LastAcceptedConfiguration 这个为例说明一下判断过程。
votes.isQuorum最终 调用VotingConfiguration::hasQuorum,依据两个节点列表进行对比:
//nodes是已收到的投票,configuration是来自集群状态中的信息
public boolean isQuorum(VotingConfiguration configuration) {
return configuration.hasQuorum(nodes.keySet());
}
public boolean hasQuorum(Collection<String> votes) {
final HashSet<String> intersection = new HashSet<>(nodeIds);
intersection.retainAll(votes);
return intersection.size() * 2 > nodeIds.size();
}
- votes,已经收到的投票
- nodeIds,VotingConfiguration的节点列表,这是一个动态维护的具备 master 资格的节点列表,来自 LastAcceptedConfiguration或LastCommittedConfiguration
- 将两个列表求交集,得到intersection,如果intersection对于nodeIds来说过半,则达到多数的要求。
对 LastCommittedConfiguration 进行相同的判断,如果同样达到多数,则认为Quorum成立。
TLA 描述如下:
IsElectionQuorum(n, votes) ==
/\ IsQuorum(votes, lastCommittedConfiguration[n])
/\ IsQuorum(votes, lastAcceptedConfiguration[n])
11. 节点切换集群
曾经有一个节点在 A 集群,现在要把他加入到 B 集群,如何操作?在 ES 7.x之前的版本中,直接修改集群名称和发现地址就可以,现在由于选举算法的差异,需要以下操作:
- 删除节点/data/nodes/0/_state目录。
- 集群名称改成相同
- cluster.initial_master_nodes配置修改成一致,或者删除该配置
- 启动节点
12. ES 关键词与 Raft 的对应关系
Join
Join 就是正式的投票,他是JoinRequest中的核心信息,选民发送投票时封装的就是 Join类
StartJoinRequest
候选人发送 RequestVote 请求时,ES 对 RequestVote 请求封装的类名称
handleStartJoin
选民收到候选人发起的 RequestVote 请求后执行对应的处理
HandleJoin
候选人对投票请求的处理,当收到足够的 Join 后被选为Master
handleClientValue
Master 准备发布集群在状态,执行发布之前的检查,并构建 PublishRequest。
HandlePublishRequest
Follower收到 Leader发来的二段提交的第一阶段请求,执行相应的处理,返回 PublishResponse
HandlePublishResponse
在二段提交过程中,Master对Follower 发来的 PublishResponse 的处理
HandleCommit
Follower收到 Leader发来的二段提交的第二阶段请求,执行相应的处理
followersChecker
Leader 定期检查 Follower 的检查器。默认1秒一次
leaderChecker
Follower 定期检查 Leader 的检查器。默认1秒一次
VotingConfiguration/config
投票配置,里面存储的是节点id
accepted
二段提交第一阶段,节点收到了 master 发来的集群状态
committed
二段提交第二阶段,节点已将集群状态应用
13. 总结
ES 实现的 Raft 比标准 Raft 有以下优点:
- 可以尽量少的增加 term
- 选举成功的几率更高
与标准 Raft 相比,ES 实现的版本保持了 Raft 选举的核心思想,使用逻辑时钟,一个 term 内只能产生一个 Leader,term 最高的信息才是可信的。选举过程引入 Prevote 流程来消除不必要的 term 增加,消除无意义的选举。在处理集群节点变更的时候,沿用 Raft 的思想,引入中间状态,节点需要在新旧两个配置上同时达到多数,才能认为达成一致。
