


前言
随着微服务的往多层分布式方向的发展,随着业务的增长,系统的膨胀和升级。问题排查,性能分析,架构优化越来越复杂。因此出现了APM(Application Performance Management)思想,全链路追踪管理。
发展

|
名称
|
出现时间
|
备注
|
|---|---|---|
| Dapper | 2010-04 | 谷歌公司发布的一篇论文,全链路追踪系统的思想源头 |
| CAT | 2011 | 国内开源 |
| Pinpoint | 2012-07 | 比较比较完善也比较有名的APM系统,页面功能完善,对java友好,不过封装比较死,代码庞大,依赖hbase,迭代开发麻烦 |
| Zipkin | 2012 | 轻量级APM平台 |
| skywalking | 2017 | apache顶级项目,比较成熟,支持opentrace协议 |
| jaeger | 2017 | CNCF毕业项目,云开发时代新宠,支持opentrace协议 |
| Opentelemetry | 2019 | CNCF提出可观测统一trace,logs,metrics。Opentelemetry 统一OpentTraceing和OpenCensus,统一标准,统一client library(跨语言),collector(支持contrib) |
思路
痛点
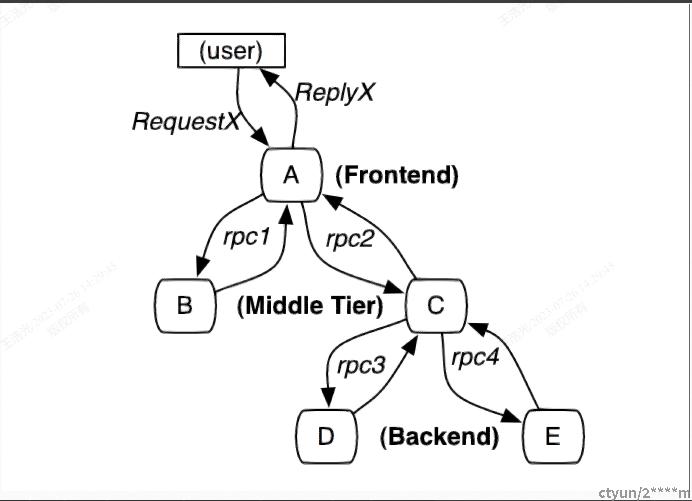
借Dapper文章图片可知,在分布式系统的调用中,一次请求会经过庞大系统中的某些服务,如果想观测这一次请求中产生的指标和日志,以及走过的路径,需要如何实现,在快捷快速接入的同时,不对整个分布式系统产生影响是很麻烦的。
数据结构

通过对一次请求调用的分析和抽象,可以定义这样的一个数据结构。基本上大部分APM系统都是按dapper的思路做的,因此在数据结构上都有相似性。
{
"trace_id": "一次分布式调用的唯一ID",
"span_id": "当前执行步骤的唯一ID",
"span_parent_id": "上一次执行步骤的唯一ID",
"span_name": "执行步骤名称",
"start_time": "当前执行步骤的开始时间",
"end_time": "当前执行步骤的结束时间",
"tags": "当前执行步骤的一些标签,比如http.method,系统版本",
"events": "当前执行步骤的一些事件"
}一些APM系统的架构
Pinpoint
官网定义
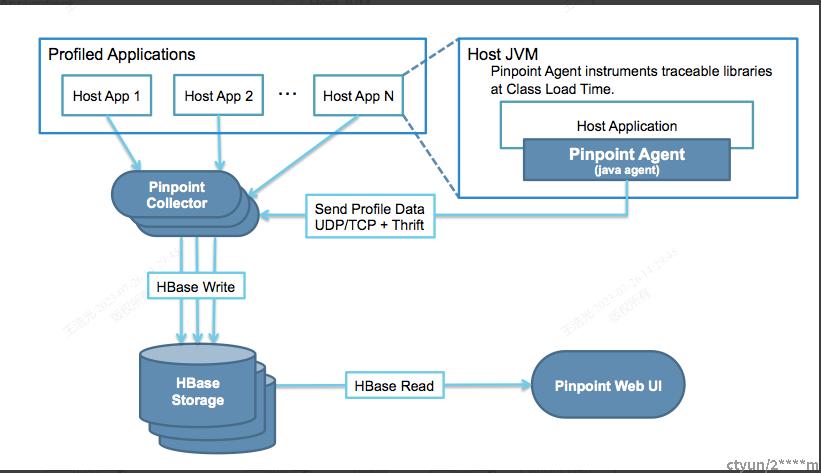
抽象

数据流程
1,pinpoint采集器采集指标,主要支持java,php。java使用javaagent探针字节码注入的方式,且支持了非常多的中间件包括不仅仅有springboot,netty,kafka等,不过由于pinpoint的开发时间较早,无法支持opentraceing协议。
2,pinpoint agent采集数据后,发送到Pinpoint Collector中。
3,Pinpoint Collector将trace数据写入到hbase中。
4,Pinpoint web查询hbase数据,返回前端客户。
Jaeger
官方定义
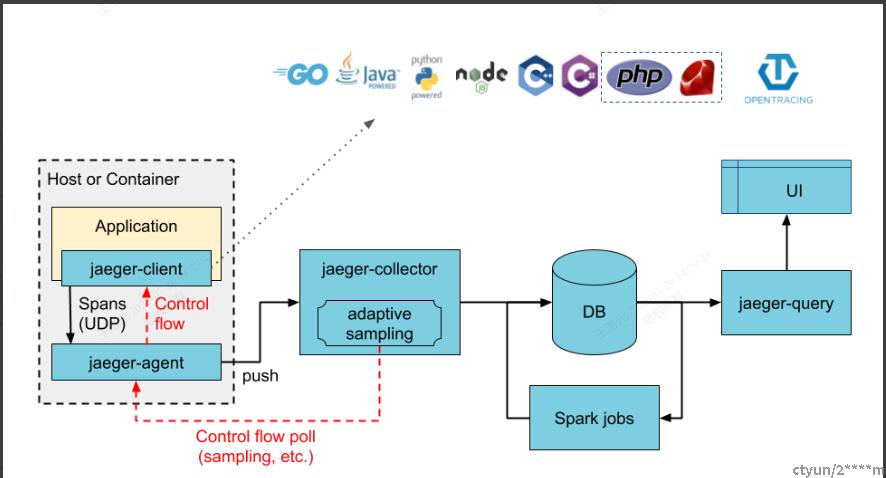
抽象
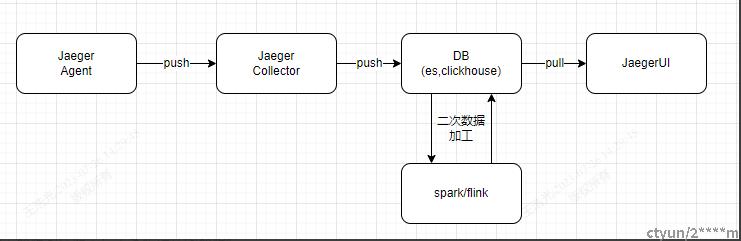
1,同理agent采集指标。支持opentracing协议。
2,Collector加工数据到存储中。主要存储为elasticsearch,主要存储索引为三个(jaeger-span,jaeger-dependances,jaeger-service)
3,spark,flink二次加工数据到存储中,主要是拓扑图数据。
4,JaegerUI查询存储中的数据返回。如果是要查看指标则使用SPM。需要单独接一个Metrics数据源。
Opentelemetry解决方案
除了pinpoint,jaeger业内还有很多优秀的APM系统,比如skywalking,zipkin等,因此客户在接入一个厂商后,后期的切换和支持非常麻烦。因此CNCF在2019年统一了OpentTraceing和OpenCensus。主要统一的方面有三个。
1,标准,或者说规则。
2,客户端(client library),不同厂商不同的客户端,客户接入一个后就不能接其他的。因此统一了采集器客户端并支持跨语言。
3,collector,通过分析和抽象大部分的APM的架构,基本上都存在一个数据加工的Collector,且都绑定了相应的存储系统。因此Opentelemetry统一了Collector,客户可以支持多种数据源的输入和输出。与存储解耦。
官方定义

主要有以下几个组件
1)Receivers:
负责接收不同格式的 telemetry data,对于 trace 来说就是 Zipkin、Jaeger、OpenCensus 以及其自研的 OTLP。除此之外,还可以支持从 Kafka 中接收以上格式的数据,可以定制开发。
2)Processors:
负责实施处理逻辑,如打包、过滤、修饰、采样等等,尾部采样逻辑就可以在这里实现。
3)Exporters:
负责将处理后的 telemetry data 按指定的格式重新输出到后端服务中,如 Zipkin、Jaeger、OpenCensus 的 backend,也可以输出到 Kafka 或另一组 collector 中,可以定制开发。
4)Extensions:
提供一些核心流程之外的插件,如分析性能问题的 pprof,健康监测的 health 等等。
使用
Collector模式(推荐)

部署模式优缺点
1,保证客户流量只需要对内,安全管理方便。
2,中心集群方便做尾采样。
3,权限管理方便。
网关模式

部署模式优缺点
1,简单方便。
2,客户安全权限控制麻烦。
3,客户端链接过多。网络延迟等。
OTEL业内思路

