


前言
现有一个需求需要实现SLS那样的加工DSL语句,前面有一篇文章介绍了JavaCC,同样还存在一个类似的工具叫ANTLR(ANother Tool for Language Recognition)也是一个非常强大的词法和语法解析器代码生成器,当前大版本为ANTLR4。整体思路基本上和JavaCC一致,相比于JavaCC而言ANTLR4提供了较简单强大的语法文件调试功能,AST树的遍历方法,还有多语言支持(java,golang,c++,python等)。ANTLR4也被各种强大的中间件使用,比如Groovy,SparkSQL,Presto,HIVE,debezium等。
整体逻辑
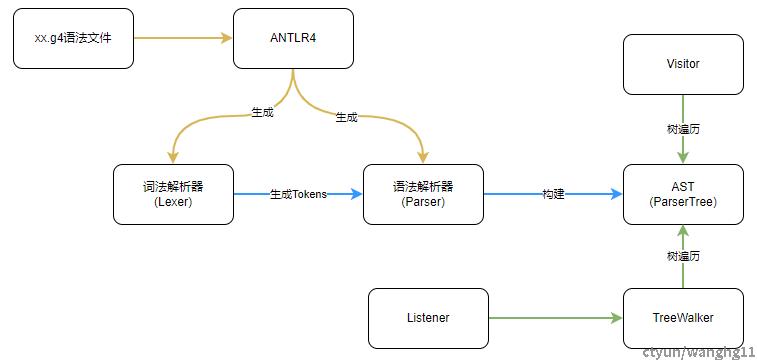
一些细节
1,用户编写xx.g4语法文件。
2,使用Antlr4生成词法解析器和语法解析器。
3,用户输入待解析的文本,词法解析器将待解析的文本内容转换成Tokens流,并过滤一些没用的字符串。
4,词法解析器将Tokens转换成AST树。
5,Antlr4提供了两种遍历AST树的方法,Listener和Visitor。
基础知识
ANTLR4 xx.g4语法文件
antlr4 grammars-v4中提供了大量g4的例子,基本上有需求照着修改即可。一般如果不是很复杂的规则文法一个g4文件即可,比如lucene的LuceneLexer.g4,如果是比较复杂的规则文法则一般放两个g4文件,比如MYSQL的规则文法可描述为MySqlLexer.g4和MySqlParser.g4。模板如下。
/** Optional javadoc style comment */
/** 详情可以查看官方文档 */
grammar Name;
options {...}
import ... ;
tokens {...}
channels {...} // lexer only
@actionName {...}
rule1 // parser and lexer rules, possibly intermingled
...
ruleNg4文件一些细节
0,g4文件中的关键字import, fragment, lexer, parser, grammar, returns,locals, throws, catch, finally, mode, options, tokens。
1,grammar 名称必须和文件名要一致。
2,语法规则(Parser)以小写字母开始,词法文件(Lexer)以大写字母开始,一般全部大写,所有的Lexer规则无论写在哪里都会被重排到Parser规则之后。
3,同理JavaCC的匹配冲突,先出现的规则优先匹配。
4,g4代码中注释使用和java一致,比如/** block comment */和// line comment。
5,anltr4默认使用<assoc=left>左结合,可以手动指定<assoc=right>右结合,anltr4默认对一些常用操作符做了特殊处理比如加减乘除等,这些就不需要再特殊处理。
6,fragment关键字可以给 Lexer 规则中的公共部分命名。
7,词法和语法规则均以分号 ';' 终结。
8,产生式后面 # label 可以给某条产生式命名,在生成的代码中即可根据标签分辨不同产生式。
9,用 'string' 单引号引出字符串,| 用于分隔两个产生式,(a|b) 括号用于指定子产生式,?+*用法同正则表达式。
10,符号#表示替代标签,可以作为变量使用,注意和产生式后的#符号区分。
11,动作Action,@header设置生成的代码的package信息,@members可以定义额外的一些变量到Antlr4语法文件中。
12,options主要是是设置语法生成的一些规则,比如设置生成的目标语言,编码等。
ANTLR4语法模式
ANTLR4主要有4中语法模式来定义语法规则。序列模式(普通序列模式,带终止符序列模式),选择模式,词法符号依赖模式,嵌套结构模式。
# 序列模式
一系列元素,它是一个任意长的,可能为空的序列,其中的元素可以是词法符号或者子规则。序列模式的例子包括变量声明和整数序列等等。
比如:
'[' NUMBER+ ']'
## 带终止符序列模式
比如:
(script ';')* //语句集合
(text '\n')* //多行数据
## 带分隔符的序列模式
比如:
params: expression ( ',' expression )*;
# 选择模式
使用|来分隔同一个语言规则的若干备选分支。
比如:
expr:NUMBER | TEXT;
# 词法符号依赖模式
一个词法符号需要和某处的另外一个词法符号配对。这样的例子包括配对的圆括号(),花括号{},方括号[]和尖括号<>。
比如:
tarray: '[' NUMBER+ ']' ; //[11,22,33]
# 嵌套结构
自相似的语言结构,表达式。一般用作最顶层的词法分析器的入口。类似java的内部类,嵌套的代码块。
比如:
expression: ID '(' expression ')' #funcDef
| '(' expression ')' #funcExp
| function #funcBase
| bool #funcBool
| TEXT #text
| NUMBER #number
;ANTLR4生成文件
<Grammar>Lexer.java: Lexer
<Grammar>Parser.java: Parser
<Grammar>Listener.java: Listener 接口
<Grammar>BaseListener.java: Listener 默认实现
<Grammar>Visitor.java: Visitor 接口
<Grammar>BaseVisitor.java: Visitor 默认实现
<Grammar>[Lexer].tokens: 当语法被拆分成多个多个文件时用于同步编号ANTLR4 Listener和Visitor两种树遍历方式对比
1,Listener由ParseTreeWalker对象自动调用遍历所有节点。Visitor为访问者模式,树的遍历由自己自动手动控制,子节点需要主动调用visit()访问,否则某写子节点则不会被调用。
2,Listener模式不能返回值,因此一般使用队列或者栈保存中间结果,而Visitor模式可以返回任何自定义类型。
3,如果要实现树上的解释器,则使用Visitor是最好的,比如函数调用 print(concat("Hello ", "World"))" ,这边只需要只执行concat函数,如果使用Visitor则非常方便,而Listener的ParseTreeWalker则会一直按顺序遍历,就不方便处理。
4,Listener在访问所有节点的时候,会依次触发进入时(enterXXX方法)和退出时(exitXXX方法),且都没有返回值。
ANTLR4 Idea插件安装
在JavaCC的时候想判断xx.jj文件是否能正确解析我的语句非常麻烦,但是Antlr4则提供了一个ANTLR Preview工具非常好用。官方安装文档。
1,依次打开IDEA Settings -> Plugins。
2,输入antlr搜索。
3,安装,重启IDEA。
4,检查,简单写一个g4文件,出现如下表示安装成功。

写个DEMO
现有个数据加工语句的DSL需求,类似与SLS加工函数语法,这边实现一个Demo,使用Visitor遍历方式简单实现解析函数表达式" str_join('##',str_lowercase('aBc5'),'d',1,true) "。如果是入门例子可以查看官网的calculator.g4例子。
编写FuncBase.g4文件
//--文法名字必须和文件名相同
grammar FuncBase;
//--设置包名信息
@header { package com.xxx.demo2.antlr4.a5; }
//--语法分析器起点,表示可以输入methodExec,TEXT,NUMBER,BOOL匹配规则
expression: methodExec
| TEXT
| NUMBER
| BOOL
;
//--函数定义语法
methodExec
: methodName '(' methodExecArguments? ')'
;
//--函数名语法
methodName
: ID
;
//--函数参数,正则语法表示使用逗号分割,可以输入多个参数
methodExecArguments
: expression ( ',' expression )*
;
//--bool数据类型词法定义
BOOL
: TRUE
| FALSE
;
//--函数名词法定义
ID : [a-zA-Z_] [a-zA-Z0-9_]*;
//--true词法定义
TRUE : 'true';
//--false词法定义
FALSE : 'false';
//--数值词法定义
NUMBER : '-'?( [0-9]* '.' )? [0-9]+;
//--字符串文本定义
TEXT : ('"'|'\'') ~[\r\n']* ('"'|'\'');
//--忽略字符
WS : [\t\r\n]+ -> skip;调试xx.g4语法文件
输入函数语法" str_join('##',str_lowercase('aBc5'),'d',1,true) ",可以看到左侧的函数表达式翻译成了右侧的AST语法树。
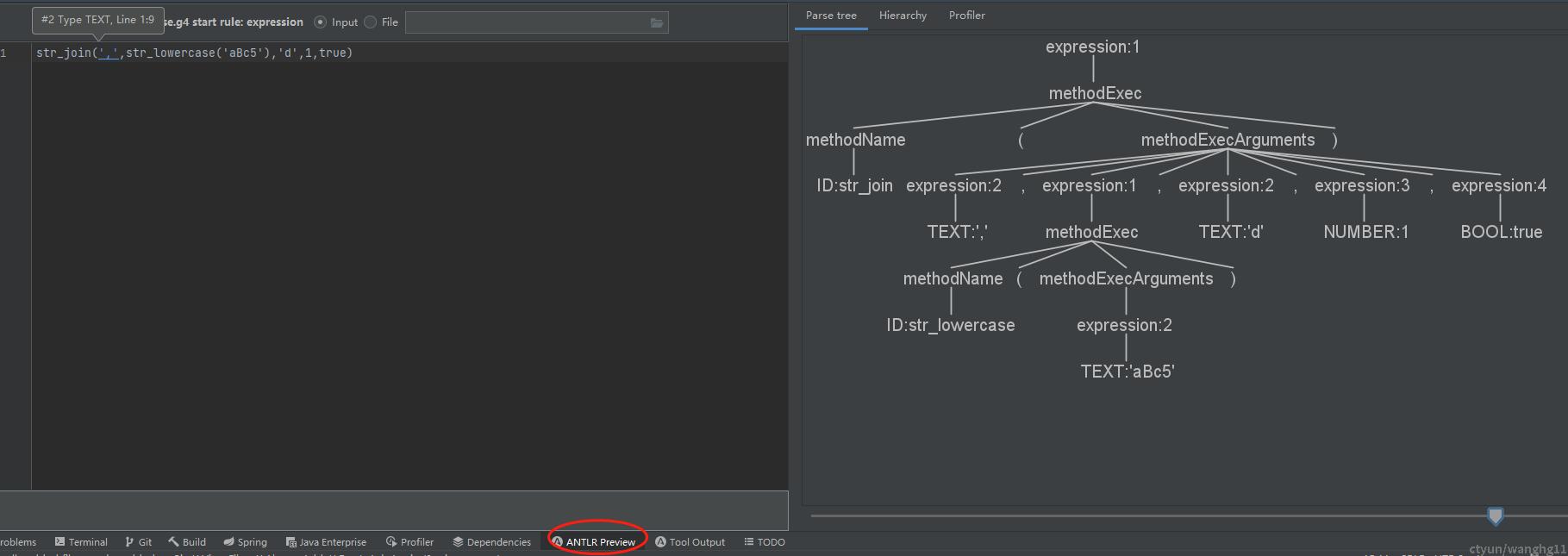
如果输入的语法有错,则左边的AST树也会提示。

生成分析器代码
生成代码有多种方式,因为我这边IDEA已经装了Antlr插件,直接生成即可,其他方式可以查看官网文档(Runtime Libraries and Code Generation Targets),还包括其他语言的生成方式。
Visitor遍历树
使用Visitor遍历树,并执行函数返回相应的结果,这里只是一个demo,如果是正式业务开发,一般为了避免频繁修复g4文件,不会直接将函数定义到g4中,而是定义一个抽象的函数模型,然后再代码中做相关的业务处理,然后遍历函数列表和参数列表,做相关的函数执行器逻辑,就像我下面代码一样。
public class MyFuncBaseVisitor extends FuncBaseBaseVisitor<Object> {
@Override
public Object visitExpression(FuncBaseParser.ExpressionContext ctx) {
if (null != ctx.methodExec()) {
return visitMethodExec(ctx.methodExec());
} else if (null != ctx.BOOL()) {
return Boolean.parseBoolean(ctx.BOOL().getText());
} else if (null != ctx.NUMBER()) {
return Double.parseDouble(ctx.NUMBER().getText());
} else {
return ctx.TEXT().getText();
}
}
@Override
public Object visitMethodExec(FuncBaseParser.MethodExecContext ctx) {
// --获得函数名
String methodName = ctx.methodName().getText();
// --获得参数信息
List<String> argList = ctx.methodExecArguments().expression().stream().map(expressionContext -> {
Object o = visitExpression(expressionContext);
if (null == o) {
return null;
}
return o.toString().replaceAll("'", "");
}).collect(Collectors.toList());
// --函数处理,这里只是demo,一般情况下需要使用不同放入函数执行逻辑器来处理相应的功能
if ("str_join".equals(methodName)) {
// --System.out.println("str_join,params:" + argList);
String splitChar = argList.get(0);
return String.join(splitChar, argList.subList(1, argList.size()));
} else if ("str_lowercase".equals(methodName)) {
// --System.out.println("str_lowercase,params:" + argList);
StringBuilder strBuffer = new StringBuilder();
for (int i = 0; i < argList.size(); i++) {
strBuffer.append(argList.get(i).toLowerCase());
if (i < argList.size() - 1) {
strBuffer.append(",");
}
}
return strBuffer.toString();
} else {
System.err.println("Unknown Method " + methodName);
return null;
}
}
}测试解析器
public class MyFuncBaseTest {
public static void main(String[] args) {
// --编写DSL语句
String exprStr = "str_join('##',str_lowercase('aBc5'),'d',1,true)";
CodePointCharStream codePointCharStream = CharStreams.fromString(exprStr);
// --创建词法解析器(Lexer)
FuncBaseLexer lexer = new FuncBaseLexer(codePointCharStream);
// --获得Tokens流
CommonTokenStream tokens = new CommonTokenStream(lexer);
// --创建语法解析器(parser)
FuncBaseParser parser = new FuncBaseParser(tokens);
// --获得AST解析树
FuncBaseParser.ExpressionContext parserTree = parser.expression();
// --打印AST解析树
System.out.println("ParserTree: " + parserTree.toStringTree(parser));
// --使用visitor遍历树
MyFuncBaseVisitor myFuncBaseVisitor = new MyFuncBaseVisitor();
Object val = myFuncBaseVisitor.visit(parserTree);
System.out.println("Visitor Result: { " + val + " }");
}
}返回结果

其他的函数可以同理实现,完成所有的函数实现即可实现SLS那种类似的加工语句解析功能。
总结
Antlr4和JavaCC思路大体一致。不过个人在开发使用上,感觉Antlr4更加人性化,尤其是Antlr4语法文件的IDEA调试和AST树的遍历上。
1,大体流程都是将语法文件翻译词法解析器(Lexer)和语法分析器(Parser)。
2,Antlr4和JavaCC语法文件除了格式不一样,思路差不多,词法器描述主要是使用正则匹配,语法器描述使用EBNF语法。
2,Antlr4提供了多语言(java,C++,Python,golang等)的支持,JavaCC只能翻译成java的Lexer和Parser。
3,Antlr4 Idea Plugin在调试语法文件上非常人性化,直观简单。
4,Antlr4提供的Listener和Visitor两种树遍历器非常方便,jjTree使用上则需要一定的功底。
5,一般业务场景都是使用Antlr4处理SQL解析,除了大名鼎鼎的Calcite,我们也可以使用Antlr4处理相应的SQL解析在执行的业务,就像SparkSQL一样。
