


前言
日志聚类主要在智能运维场景中用的比较多,比如异常检测告警,告警合并,日志类型统计,安全场景下的入侵检测,日志统计分析,数据挖掘等方面。业内厂商做的好的有SLS的LogReduce,CLS的日志聚类,LTS的日志聚类等。由于业务场景需要,文章主要做个聚类算法论文的简单理解。
思路
1,日志聚类的前提是:同一个服务下,一个日志模板产生的日志经过分词得到的词的个数是相同的。
2,日志聚类的过程就是对日志数据进行模板(Pattern)的提取和匹配,而不是对文档的主题分类。因此不用设计到复杂的自然语言处理(NLP),如果是自然语言处理主题分类则存在数据清洗->分词处理->文本转向量->PCA降维->k-means聚类。那将非常复杂,且计算成本将异常高,下一篇将关于离线数据下的文本主题分类。
3,在如果不满足第一点的情况下,如果分词长度不一样将如何处理?
4,日志数据是实时的,能不断增量更新模板(Pattern),因此无法使用k-means聚类。
聚类流程
业内主要的日志聚类解决方案主要实现是使用Drain3和Spell算法。Drain3一般做第一层的分类长度相等的聚类过程,Spell主要做分类长度不相等的二次聚类过程。
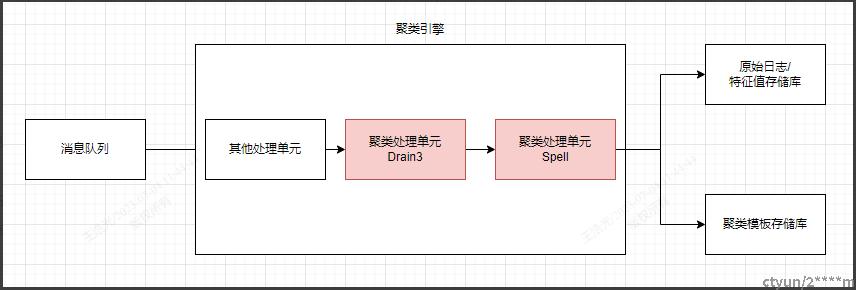
主要思路
1,数据采集到消息队列中。
2,日志数据进入聚类引擎后,首先通过Drain3做一次聚类,spell做二次聚类。
3,聚类完成后将原始日志和特征值一起存储到日志行中。
4,聚类完成后同时将聚类模板(Pattern)数据写到第三方的存储中。
Drain3算法
Drain算法由香港中文大学提出《Drain An Online Log Parsing Approach with Fixed Depth Tree》并提供了一个python实现的demo,Drain3在Drain的基础上主要是为中文提供了解决方案,整体思路和Drain基本一致。其核心思想是使用一个固定深度的Parser Tree,提供了实时增量提取日志模板的能力。
Parser Tree

树结构说明:
1)第一层是 root node,无任何意义;
2)第二层是分词后词的个数,通常分词符号可以按自己定义比如(,#$|等),如果是中文的话需要单独的分词器,分词数组长度Length。
3)第三层及以下是日志模板中的前缀单词。一般情况下不会超过4层,且为了避免子节点爆炸,会设置一个maxChild,超过这个节点数值的全部标识为*。
4)最底层的叶子节点为相同前缀单词的日志模板。
5)树的所有深度都一致。
聚类流程
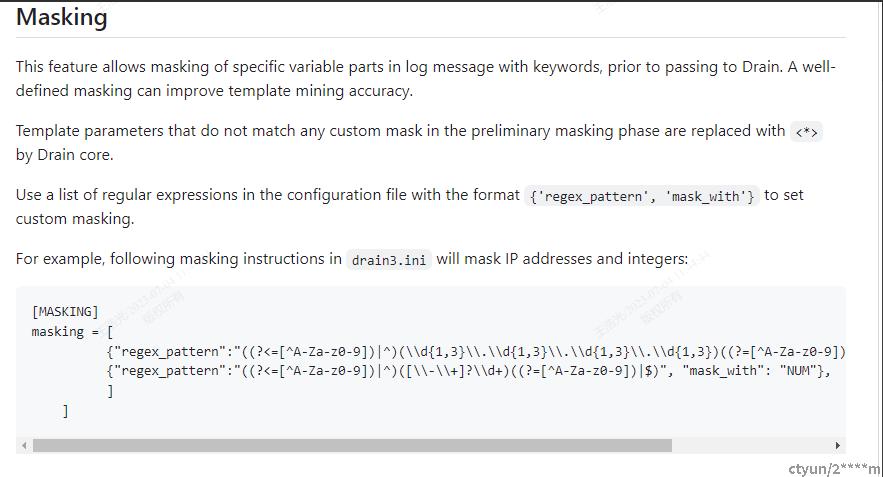
1,Preprocess by Domain Knowledge (领域知识处理)
之前说过,使用同一个日志模板打印出的日志,同一个分词器下,分词后长度是一致的。因此可以把这个模板区分变量和常量,变量使用*代替,常量直接显示然后组成一个模板。而Drain3就是推导这样一个模板汇聚的过程。

那反过来如何将变量提取出来呢,这个时候就可以把那些比如:数值,IP,时间,邮件等使用正则提取出来即可,然后组成预处理后的日志。比如论文中的例子。
#原始日志
PacketResponder 0 for block blk_4003 terminating
#领域处理后的(正则处理)
PacketResponder * for block * terminating像官方demo就提供了一个这样的领域知识提取配置正则的地方。
2,Search by Log Message Length(通过日志长度搜索树)
通过分词获得数组长度即为日志长度,比如论文中的原始日志"Send block 44",分词获得["Send","block","44"],经过第一步领域只是出来后变成["Send","block","*"],Length为3。获得Length后即可遍历Parser Tree匹配第2层节点。
3,Search by Preceding Tokens (通过前缀词搜索树)
上一步获得的分词数组["Send","block","44"],遍历到第3到depth-1层,判断是否命中节点。
4,Search by Token Similarity(通过词的相似度匹配)
由于之前的步骤已经将Length和前缀树都匹配成功了,则后面需要匹配叶子节点中日志组的相似度。匹配算法如下。

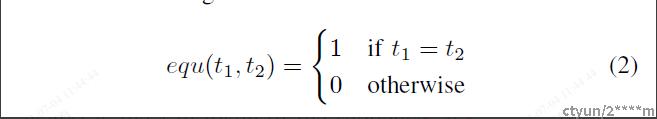


由于之前的前提是分词后的长度一致,因此n是一样的。通过两个数组的对比,计算函数simSeq如果>=我们设置的st(相似度)则表示当前日志组为最近匹配,否则返回么有匹配到。
5,Update the Parse Tree (更新树)
考虑到日志是实时增量的,需要不断更新树。然后通过大量的数据聚类出一个统一的模板,但是如果是同一个服务同一个日志模板,基本上前缀单词节点数是不会很大的,如果超过了为了避免子节点爆炸,超过maxChild的模板均使用*作为前缀单词。那是如何更新的呢。

a,原始日志"Send block 44",分词获得["Send","block","44"],经过第一步领域只是出来后变成["Send","block","*"],Length为3。
b,构架图中的左边的Parser Tree。
c,来了新的日志"Receive 120 bytes",首先对齐分词获得["Receive","120","bytes"],Length为3。
d,匹配到了第二层节点,匹配第三层节点前缀词为send,不匹配则传家一个新的子节点,在构架图中左边的Parser Tree。底层的叶子节点保存日志的唯一ID和日志详情。
e,完成更新,最后整个树的叶子节点即为所有日志实时增量后的模板。
Spell算法
Spell由犹他大学大名鼎鼎的李飞飞大佬提出,且思想相对于Drain更容易理解。前面说过Drain主要是为了同一个日志模板相似度分析的情况。那如果分词长度不一样那该怎么样获得聚类模板呢,Spell算法:《Spell: Streaming Parsing of System Event Logs》。一般情况下同一个日志流程中日志模板都是一致的,只有很少的情况下才会出现不一样的日志模板,因此一般Spell做第二层聚合。
各类算法性能对比

Drain论文中Spell和Drain都是一样的实时增量聚类算法,性能相对于Drain只差一点点,可以看出在不同日志类型下Spell和Drain耗时不分伯仲。
算法思想
Spell核心思想为最长公共子串LCS。

何为最长公共子串LCS(longest common subsequence)?论文中的例子:

对于数组A:{1,3,5,7,9},数组B:{1,5,7,19},数组A和B的最长公共子串为{1,5,7}。同理对于文本内容数组也是如此。
算法实现思路

论文例子思路
1)定义两个数据结构LCSObject 和 LCSMap。LCSObject 包括两个数据LCSseq(日志键)和lineIds(日志唯一ID列表),LCSMap用于保存LCSObject 。
2)用论文中的例子来说明,首先接受到日志"Temperature (41C) exceeds warning threshold",包装成LCSObject 后写入LCSMap中。
3)又来了一个日志"Temperature (43C) exceeds warning threshold",与LCSMap中之前的日志"Temperature (41C) exceeds warning threshold"对比,求出公共子串"Temperature exceeds warning threshold"。
4)判断当最大公共子序列的长度在输入条目长度的1/2倍到1倍之间时,当然这个值可以配置如Drain算法中的st值,合并并且将非公共子串中的词(Token)转换成"*"。


5)继续以上步骤,则可以实时增量获得模板。
6)不过当LCSMap越来越大的时候,且日志长度很长的时候,性能会比较差,论文中建议使用前缀树来优化性能,具体的可以查看源论文。
总结
Drain3和spell都是实时增量聚类算法。在同一个日志模板下分词后的长度一致,可以使用drain算法做第一次聚类,在碰到不一样的分词长度的情况下可以使用spell算法做二次聚类。不过由于都存储一个分词过程,因此在中文情况下需要单独考虑。由于时间有限暂时不做demo代码演示,理解大体思路即可。
