向量检索的集群规划
更新时间 2023-12-10 22:59:27
最近更新时间: 2023-12-10 22:59:27
本章节主要介绍向量检索的集群规划。
向量检索的索引构建与查询均使用堆外内存,所以集群容量与索引类型、总堆外内存大小等因素相关。通过预估全量索引所需的堆外内存大小,可以选择合适的集群规格。
不同类型的索引所需堆外内存大小的预估方式不同,计算公式如下:
- GRAPH索引

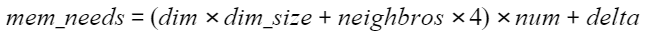
说明若有实时更新索引的需求,还需要考虑向量索引构建和自动merge所需的堆外内存开销,保守估计需要1.5~2倍mem_needs。
- PQ类索引

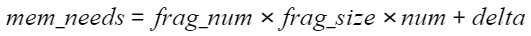
- FALT 、IVF索引


参数说明
| 参数 | 说明 |
|---|---|
| dim | 向量维度。 |
| neighbors | 图节点邻居数,默认值为64。 |
| dim_size | 每一维度值所需的字节数,默认为float类型,需要4字节。 |
| num | 向量总条数。 |
| delta | 元数据大小,该项通常可以忽略。 |
| frag_num | 量化编码时的向量分段数,创建索引时若未配置该值,则由向量维度“dim”决定。 if dim <= 256: frag_num = dim / 4 elif dim <= 512: frag_num = dim / 8 else : frag_num = 64 |
| frag_size | 量化编码时中心点编码的size,默认为1,当“frag_num”大于256时,该值等于2。 |
基于上述计算方法,可预估出完整向量索引所需堆外内存的大小。选择集群规格时,还需考虑每个节点的堆内存开销。
节点的堆内存分配策略:每个节点的堆内存大小为节点物理内存的一半,且最大不超过31GB。
例如,基于SIFT10M数据集创建GRAPH索引,其“dim”为“128”,“dim_size”为“4”,“neighbors”采用默认值“64”,“num”为“1000万”,将各值代入上述公式得到GRAPH索引所需堆外内存大小约为:

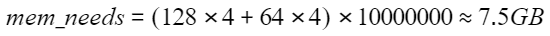
同时考虑到堆内存的开销,单台“8U 16G”规格的机器可以满足该场景的需求。如果实际场景还有实时写入或更新的需求,则需要考虑申请更大的内存规格。

