如何调整分布列?
在数据仓库类型的数据库中,大表的分布列选择对于数据库和语句查询性能都有至关重要的影响。
如果表的分布列选择不当,在数据导入后有可能出现数据分布倾斜,进而导致某些磁盘的使用明显高于其他磁盘,极端情况下会导致集群只读。
对于Hash分表策略,存在数据倾斜情况下,查询时出现部分DN的I/O短板,从而影响整体查询性能。 在对已经创建的表,该如何进行分布列的调整,也是我们经常思考的课题。
采用Hash分表策略之后需对表的数据进行数据倾斜性检查,以确保数据在各个DN上是均匀分布的。一般来说,不同DN的数据量相差5%以上即可视为倾斜,如果相差10%以上就必须要调整分布列。
针对分布不均匀的表,尽可能通过调整分布列,以减少数据倾斜,避免带来潜在的数据库性能问题。
选择合适的分布列
Hash分布表的分布列选取至关重要,需要满足以下基本原则:
- 列值应比较离散,以便数据能够均匀分布到各个DN。例如,考虑选择表的主键为分布列,如在人员信息表中选择身份证号码为分布列;
- 在满足第一条原则的情况下尽量不要选取存在常量filter的列;
- 在满足前两条原则的情况,考虑选择查询中的连接条件为分布列,以便Join任务能够下推到DN中执行,且减少DN之间的通信数据量;
- 支持多分布列特性,可以更好地满足数据分布的均匀性要求。
如何调整
通过 select version(); 语句查询当前数据库版本号,版本号不同,调整的方式不同:

- 8.0.x及以前版本,通过重建表来调整 :
1.通过Data Studio或者Linux下使用gsql访问数据库。
2.创建新表。
说明以下步骤语句中,table1为原表名,table1_new为新表名,column1和column2为分布列名称。
CREATE TABLE IF NOT EXISTS table1_new
( LIKE table1 INCLUDING ALL EXCLUDING DISTRIBUTION)
DISTRIBUTE BY
HASH (column1, column2);
3.迁移数据到新表。
START TRANSACTION;
LOCK TABLE table1 IN ACCESS EXCLUSIVE MODE;
INSERT INTO table1_new SELECT * FROM table1;
COMMIT;
4.查看表数据是否迁移成功,删除原表。
SELECT COUNT(*) FROM table1_new;
DROP TABLE table1;
5.替换原表。
ALTER TABLE table1_new RENAME TO table1;
- 8.1.0及以后版本后 ,通过ALTER TABLE语法进行调整,以下为示例。
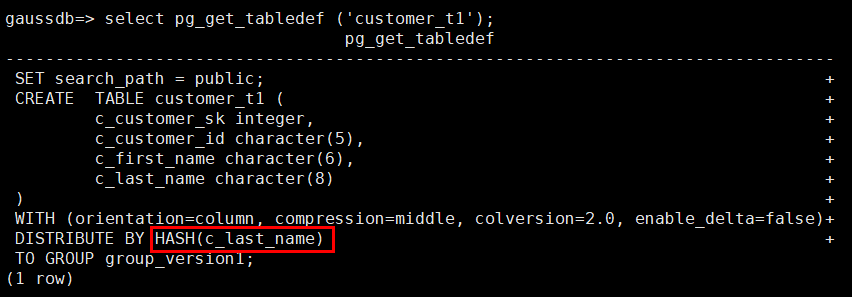
1.查询当前表定义,回显发现该表分布列为c_last_name。
select pg_get_tabledef('customer_t1');
2.尝试执行更新分布列中的数据提示错误信息。
update customer_t1 set c_last_name = 'Jimy' where c_customer_sk = 6885;

3.将该表的分布列修改为不会更新的列,例如c_customer_sk。
alter table customer_t1 DISTRIBUTE BY hash (c_customer_sk);
4.重新执行更新旧的分布列的数据。更新成功。
update customer_t1 set c_last_name = 'Jimy' where c_customer_sk = 6885;
如何查看和设置数据库的字符集编码格式
查看数据库字符集编码
使用server_encoding参数查看当前数据库的字符集编码。例如,查看到数据库music的字符集编码为UTF8。
music=> show server_encoding;
server_encoding
-----------------
UTF8
(1 row)
设置数据库的字符集编码
说明DWS不支持修改已创建数据库的字符编码格式。
如果需要指定数据库的字符集编码格式,可按照下面的CREATE DATABASE语法格式,使用template0新建一个数据库。为了适应全球化的需求,使数据库编码能够存储与表示绝大多数的字符,建议创建Database的时候使用UTF8编码。
CREATE DATABASE语法格式
CREATE DATABASE database_name
[ [ WITH ] { [ OWNER [=] user_name ] |
[ TEMPLATE [=] template ] |
[ ENCODING [=] encoding ] |
[ LC_COLLATE [=] lc_collate ] |
[ LC_CTYPE [=] lc_ctype ] |
[ DBCOMPATIBILITY [=] compatibility_type ] |
[ CONNECTION LIMIT [=] connlimit ]}[...] ];
- TEMPLATE [ = ] template
模板名。即从哪个模板创建新数据库。DWS采用从模板数据库复制的方式来创建新的数据库。初始时,DWS包含两个模板数据库template0、template1,以及一个默认的用户数据库postgres。
取值范围:已有数据库的名称。不指定时,系统默认拷贝template1。另外,不支持指定为postgres数据库。
注意目前不支持模板库中含有SEQUENCE对象。如果模板库中有SEQUENCE,则会创建数据库失败。
- ENCODING [ = ] encoding
指定数据库使用的字符编码,可以是字符串(如'SQL_ASCII')、整数编号。
不指定时,默认使用模版数据库的编码。模板数据库template0和template1的编码默认与操作系统环境相关。template1不允许修改字符编码,因此若要变更编码,请使用template0创建数据库。
常用取值:GBK、UTF8、Latin1。
注意指定新的数据库字符集编码必须与所选择的本地环境中(LC_COLLATE和LC_CTYPE)的设置兼容。
当指定的字符编码集为GBK时,部分中文生僻字无法直接作为对象名。这是因为GBK第二个字节的编码范围在0x40-0x7E之间时,字节编码与ASCII字符@A-Z[]^ `a-z{|}重叠。其中@[]^ '{|}是数据库中的操作符,直接作为对象名时,会语法报错。例如“侤”字,GBK16进制编码为0x8240,第二个字节为0x40,与ASCII“@”符号编码相同,因此无法直接作为对象名使用。如果确实要使用,可以在创建和访问对象时,通过增加双引号来规避这个问题。
示例
创建一个UTF8编码的数据库music(本地环境的编码格式必须也为UTF8)。
CREATE DATABASE music ENCODING 'UTF8' template = template0;
如何处理建表时date类型字段自动转换为timestamp类型的问题?
创建数据库时,可通过DBCOMPATIBILITY参数指定兼容的数据库的类型,DBCOMPATIBILITY取值范围:ORA、TD、MySQL。分别表示兼容Oracle、Teradata和MySQL数据库。如果创建数据库时不指定该参数,则默认为ORA,在ORA兼容模式下,date类型会自动转换为timestamp(0)。
只有在MySQL兼容模式下才支持date类型,为解决以上问题,需要将兼容模式修改为MySQL,兼容模式仅支持在创建数据库时设置。DWS从8.1.1集群版本开始支持MySQL兼容模式类型, 可参考如下示例进行操作:
gaussdb=> CREATE DATABASE mydatabase DBCOMPATIBILITY='mysql';
CREATE DATABASE
gaussdb=> \c mydatabase
Non-SSL connection (SSL connection is recommended when requiring high-security)
You are now connected to database "mydatabase" as user "dbadmin".
mydatabase=> create table t1(c1 int, c2 date);
NOTICE: The 'DISTRIBUTE BY' clause is not specified. Using round-robin as the distribution mode by default.
HINT: Please use 'DISTRIBUTE BY' clause to specify suitable data distribution column.
CREATE TABLE
是否需要定时对常用的表做VACUUM FULL和ANALYZE操作?
需要。
对于频繁增、删、改的表,需要定期执行VACUUM FULL和ANALYZE,该操作可回收已更新或已删除的数据所占据的磁盘空间,防止因数据膨胀和统计信息不准造成性能下降。
- 一般情况下,对表执行完大量增、改操作后,建议进行ANALYZE。
- 对表执行过删除操作后,建议进行VACUUM,一般不建议日常使用VACUUM FULL选项,但是可以在特殊情况下使用。例如,用户删除了一个表的大部分行之后,希望从物理上缩小该表以减少磁盘空间占用。VACUUM和VACUUM FULL具体的差异可以参考下方“VACUUM和VACUUM FULL”。
语法格式
指定某张表进行分析。
ANALYZE table_name;
对数据库中的所有表(非外部表)进行分析。
ANALYZE;
指定某张表进行VACUUM。
VACUUM table_name;
指定某张表进行VACUUM FULL。
VACUUM FULL table_name;
更多语法参见《开发指南》的有关“VACUUM”和“ANALYZE | ANALYSE”章节。
说明l 如果执行VACUUM FULL命令后所占用物理空间无变化(未减少),请确认是否有其他活跃事务(删除数据事务开始之前开始的事务,并在VACUUM FULL执行前未结束)存在,如果有等其他活跃事务退出进行重试。
l 8.1.3及以上版本中Vacuum/Vacuum Full可在管控面操作调用,详情可参见《数据仓库服务用户指南》中“智能运维”章节。
VACUUM和VACUUM FULL
在DWS中,VACUUM的本质就是一个“吸尘器”,用于吸收“尘埃”。而尘埃其实就是旧数据,如果这些数据没有及时清理,那么将会导致数据库空间膨胀,性能下降,更严重的情况会导致宕机。
VACUUM的作用:
- 空间膨胀问题:清除废旧元组以及相应的索引。包括提交的事务delete的元组(以及索引)、update的旧版本(以及索引),回滚的事务insert的元组(以及索引)、update的新版本(以及索引)、copy导入的元组(以及索引)。
- FREEZE:防止因事务ID回卷问题(Transaction ID wraparound)而导致的宕机,将小于OldestXmin的事务号转化为freeze xid,更新表的relfrozenxid,更新库的relfrozenxid,truncate clog。
- 更新统计信息:VACUUM ANALYZE时,会更新统计信息,使得优化器能够选择更好的方案执行SQL语句。
VACUUM命令存在两种形式,VACUUM和VACUUM FULL,目前VACUUM对行存表有作用,对列存表无显著的作用,列存表只能依靠VACUUM FULL释放空间。具体区别见下表:
VACUUM和VACUUM FULL
| 差异项 | VACUUM | VACUUM FULL |
|---|---|---|
| 空间清理 | 如果删除的记录位于表的末端,其所占用的空间将会被物理释放并归还操作系统。而如果不是末端数据,会将表中或索引中dead tuple(死亡元组)所占用的空间置为可用状态,从而复用这些空间。 | 不论被清理的数据处于何处,这些数据所占用的空间都将被物理释放并归还于操作系统。当再有数据插入后,分配新的磁盘页面使用。 |
| 锁类型 | 共享锁,可以与其他操作并行。 | 排他锁,执行期间基于该表的操作全部挂起。 |
| 物理空间 | 不会释放。 | 会释放。 |
| 事务ID | 不回收。 | 回收。 |
| 执行开销 | 开销较小,可以定期执行。 | 开销很大,建议确认数据库所占磁盘页面空间接近临界值再执行操作,且最好选择数据量操作较少的时段完成。 |
| 执行效果 | 执行后基于该表的操作效率有一定提升。 | 执行完后,基于该表的操作效率大大提升。 |
DWS数据库设置主键后还需要设置分布键吗?
仅设置主键即可,默认会选择主键的第一列作为分布键。如果两个同时设置,主键必须包含分布键。
DWS是否兼容PostgreSQL的存储过程?
兼容。
DWS兼容PostgreSQL的存储过程,请参见《开发指南》的“存储过程”章节。
如何理解分区表、数据分区和分区键?
分区表:分区表是把逻辑上的一张表根据某种方案分成几张物理块进行存储。这张逻辑上的表称之为分区表,物理块称之为分区。分区表是一张逻辑表,不存储数据,数据实际是存储在分区上的。
数据分区:在DWS分布式系统中,数据分区是在一个节点内部按照用户指定的策略对数据做进一步的水平分表,将表按照指定范围划分为多个数据互不重叠的部分(Partition)。
分区键:分区键是一个或多个表列的有序集合。表分区键列中的值用来确定每个表行所属的数据分区。
分区表中指定了maxvalue分区时如何再添加新的分区
问题背景
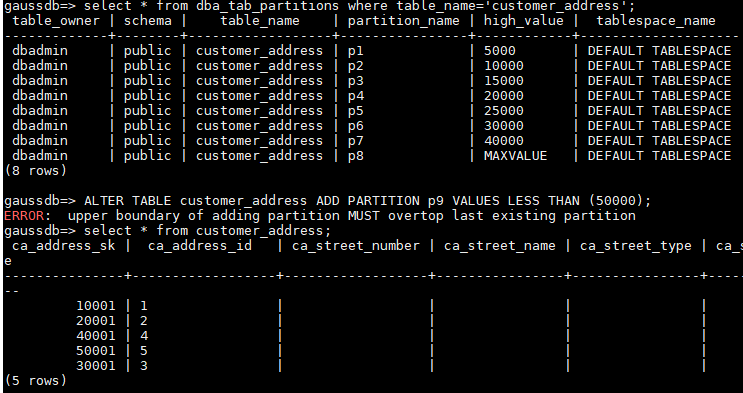
用户在最初建表时指定了Maxvalue分区后,数据被写入该分区,如下图中的40001,当用户需要新建一个40000~50000的分区时报错:upper boundary of adding partition MUST overtop last existing partition.
根据报错提示,不能新增分区的原因是:分区的上边界必须大于最后一个现有分区的上边界。即若需要新增40000~50000的分区,需调整分区表分区中的上边界,若直接删除Maxvalue分区再新建分区可能会导致原有p8分区数据被删除。
解决方法
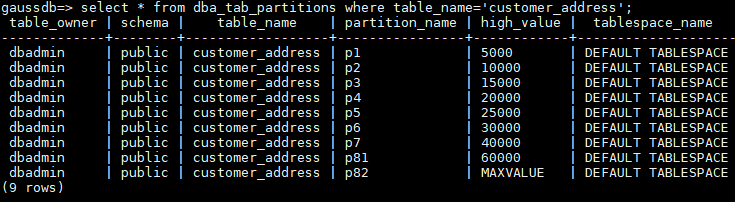
业务数据在p8分区的分布应该是40000~某一个值之间,这个值到MAXVALUE应该是没有数据的。那么假设这个值是60000。
1.使用split子句分割p8分区为p81分区范围为[40000,60000)和p82分区范围为[60000,MAXVALUE)。
ALTER TABLE customer_address SPLIT PARTITION P8 AT (60000) INTO
(
PARTITION P81,
PARTITION P82
);
2.使用drop命令删除分区p82(此时p82分区没有数据)。
ALTER TABLE customer_address drop partition p82;
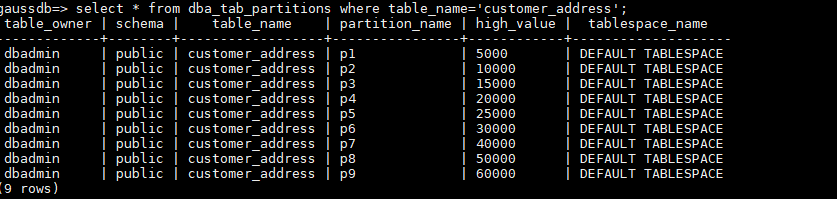
3.使用split命令将p81分割成为p8和p9, [40000,50000)的分区p8就创建成功了。
ALTER TABLE customer_address SPLIT PARTITION P81 AT (50000) INTO
(
PARTITION P8,
PARTITION P9
);
4.之后操作中如果需要再新增分区,使用ALTER TABLE的ADD子句即可实现。例如新增分区P10:
ALTER TABLE customer_address ADD PARTITION p10 VALUES LESS THAN (70000);
如何导出某张表结构?
建议使用Data Studio图形化客户端进行表数据导出,支持以下几种常见场景:
- 指定某张表数据的导出。
- 某个schema下的所有表数据的导出。
- 某个数据库下的所有表数据的导出。
具体操作请参见《工具指南》的“导出表数据”章节。
如何导出数据库中所有表和视图?
您可以使用pg_tables视图和pg_views视图查询数据库中所有表信息和视图。执行示例如下:
SELECT * FROM pg_tables;
SELECT * FROM pg_views;
返回的字段请参见《数据仓库服务开发指南》的“PG_TABLES”和“PG_VIEWS”章节。
是否有高效的删除表数据的方法?
有。
删除大批量的日志数据时,使用delete语法需要花费更大的时间,此时可以通过truncate语法进行大批量删除操作,它的删除速度比delete快得多。
详情请参见《数据仓库服务开发指南》的“TRUNCATE”章节。
功能描述
清理表数据,TRUNCATE快速地从表中删除所有行。
它和在目标表上进行无条件的DELETE有同样的效果,但由于TRUNCATE不做表扫描,因而快得多。在大表上操作效果更明显。
功能特点
- TRUNCATE TABLE在功能上与不带WHERE子句DELETE语句相同:二者均删除表中的全部行。
- TRUNCATE TABLE比DELETE速度快且使用系统和事务日志资源少:
−DELETE语句每次删除一行,并在事务日志中为所删除每行记录一项。
−TRUNCATE TABLE通过释放存储表数据所用数据页来删除数据,并且只在事务日志中记录页的释放。
- TRUNCATE,DELETE,DROP三者的差异如下:
−TRUNCATE TABLE,删除内容,释放空间,但不删除定义。
−DELETE TABLE,删除内容,不删除定义,不释放空间。
−DROP TABLE,删除内容和定义,释放空间。
示例
--创建表。CREATE TABLE tpcds.reason_t1 AS TABLE tpcds.reason;
--清空表tpcds.reason_t1。TRUNCATE TABLE tpcds.reason_t1;
--删除表。DROP TABLE tpcds.reason_t1;
--创建分区表。
CREATE TABLE tpcds.reason_p
(
r_reason_sk integer,
r_reason_id character(16),
r_reason_desc character(100)
)PARTITION BY RANGE (r_reason_sk)
(
partition p_05_before values less than (05),
partition p_15 values less than (15),
partition p_25 values less than (25),
partition p_35 values less than (35),
partition p_45_after values less than (MAXVALUE)
);
--插入数据。
INSERT INTO tpcds.reason_p SELECT * FROM tpcds.reason;
--清空分区p_05_before。
ALTER TABLE tpcds.reason_p TRUNCATE PARTITION p_05_before;
--清空分区p_15。
ALTER TABLE tpcds.reason_p TRUNCATE PARTITION for (13);
--清空分区表。
TRUNCATE TABLE tpcds.reason_p;
--删除表。
DROP TABLE tpcds.reason_p;
如何查看外部表信息?
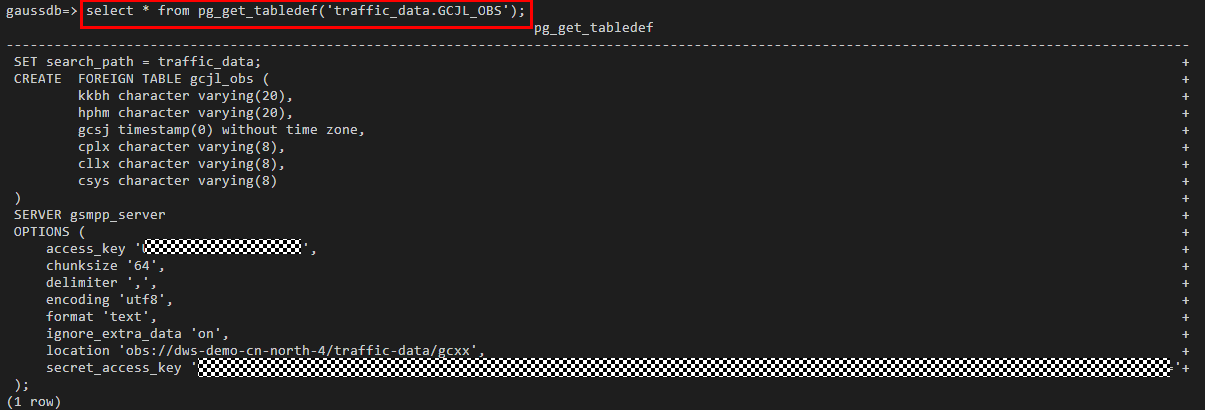
如果需要查询OBS、GDS等外表信息(如OBS路径),可以执行以下语句查询。
select * from pg_get_tabledef('外表名称')
例如,表名为traffic_data.GCJL_OBS,查询如下:
select * from pg_get_tabledef('traffic_data.GCJL_OBS');
如果建表时没有指定分布列,数据会怎么存储?
说明8.1.2及以上集群版本,可通过GUC参数default_distribution_mode来查询和设置表的默认分布方式。
如果建表时没有指定分布列,数据会以下几种场景来存储:
- 场景一
若建表时包含主键/唯一约束,则选取HASH分布,分布列为主键/唯一约束对应的列。
CREATE TABLE warehouse1
(
W_WAREHOUSE_SK INTEGER PRIMARY KEY,
W_WAREHOUSE_ID CHAR(16) NOT NULL,
W_WAREHOUSE_NAME VARCHAR(20)
);
NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "warehouse1_pkey" for table "warehouse1"
CREATE TABLE
SELECT getdistributekey('warehouse1');
getdistributekey
------------------
w_warehouse_sk
(1 row)
- 场景二
若建表时不包含主键/唯一约束,但存在数据类型支持作分布列的列,则选取HASH分布,分布列为第一个数据类型支持作分布列的列。
CREATE TABLE warehouse2
(
W_WAREHOUSE_SK INTEGER ,
W_WAREHOUSE_ID CHAR(16) NOT NULL,
W_WAREHOUSE_NAME VARCHAR(20)
);
NOTICE: The 'DISTRIBUTE BY' clause is not specified. Using 'w_warehouse_sk' as the distribution column by default.
HINT: Please use 'DISTRIBUTE BY' clause to specify suitable data distribution column.
CREATE TABLE
SELECT getdistributekey('warehouse2');
getdistributekey
------------------
w_warehouse_sk
(1 row)
- 场景三
若建表时不包含主键/唯一约束,也不存在数据类型支持作分布列的列,选取ROUNDROBIN分布。
CREATE TABLE warehouse3
(
W_WAREHOUSE_ID CHAR(16) NOT NULL,
W_WAREHOUSE_NAME VARCHAR(20)
);
NOTICE: The 'DISTRIBUTE BY' clause is not specified. Using 'w_warehouse_id' as the distribution column by default.
HINT: Please use 'DISTRIBUTE BY' clause to specify suitable data distribution column.
CREATE TABLE
SELECT getdistributekey('warehouse3');
getdistributekey
------------------
w_warehouse_id
(1 row)
如何将联结查询的null结果替换成0?
在执行outer join(left join、right join、full join)联结查询时,outer join在匹配失败的情况下结果集会补空产生大量NULL值, 可以在联结查询时将这部分null值替换为0。
可使用coalesce函数,它的作用是返回参数列表中第一个非NULL的参数值。例如:
SELECT coalesce(NULL,'hello');
coalesce
----------
hello
(1 row)
有表course1和表course2,使用left join对两表进行联结查询:
SELECT * FROM course1;
stu_id | stu_name | cour_name
----------+------------+--------------------
20110103 | ALLEN | Math
20110102 | JACK | Programming Design
20110101 | MAX | Science
(3 rows)
SELECT * FROM course2;
cour_id | cour_name | teacher_name
---------+--------------------+--------------
1002 | Programming Design | Mark
1001 | Science | Anne
(2 rows)
SELECT course1.stu_name,course2.cour_id,course2.cour_name,course2.teacher_name FROM course1 LEFT JOIN course2 ON course1.cour_name = course2.cour_name ORDER BY 1;
stu_name | cour_id | cour_name | teacher_name
------------+---------+--------------------+--------------
ALLEN | | |
JACK | 1002 | Programming Design | Mark
MAX | 1001 | Science | Anne
(3 rows)
使用coalesce函数将查询结果中的空值替换为0或其他非0值:
SELECT course1.stu_name,
coalesce(course2.cour_id,0) AS cour_id,
coalesce(course2.cour_name,'NA') AS cour_name,
coalesce(course2.teacher_name,'NA') AS teacher_name
FROM course1
LEFT JOIN course2 ON course1.cour_name = course2.cour_name
ORDER BY 1;
stu_name | cour_id | cour_name | teacher_name
------------+---------+--------------------+--------------
ALLEN | 0 | NA | NA
JACK | 1002 | Programming Design | Mark
MAX | 1001 | Science | Anne
(3 rows)
如何查看表是行存还是列存?
表的存储方式由建表语句中的ORIENTATION参数控制,row表示行存,column表示列存。
查看已创建的表是行存还是列存,可通过表定义函数PG_GET_TABLEDEF查询。
如下orientation=column表示为列存表。
目前暂不支持通过ALTER
TABLE语句修改ORIENTATION参数,即行存表和列存表无法直接进行转换。
SELECT * FROM PG_GET_TABLEDEF('customer_t1');
pg_get_tabledef
-----------------------------------------------------------------------------------
SET search_path = tpchobs; +
CREATE TABLE customer_t1 ( +
c_customer_sk integer, +
c_customer_id character(5), +
c_first_name character(6), +
c_last_name character(8) +
) +
WITH (orientation=column, compression=middle, colversion=2.0, enable_delta=false)+
DISTRIBUTE BY HASH(c_last_name) +
TO GROUP group_version1;
(1 row)
如何使用自定义函数改写CRC32函数
DWS目前未内置CRC32函数,但如果需要实现MySQL中的CRC32()函数功能,用户可使用DWS的自定义函数语句对其进行改写。
- 函数:CRC32(expr)
- 描述:用于计算循环冗余值。入参expr为字符串。如果参数为NULL,则返回NULL;否则,在计算冗余后返回32位无符号值。
DWS的自定义函数语句改写CRC32函数示例:
CREATE OR REPLACE FUNCTION crc32(text_string text) RETURNS bigint AS $$
DECLARE
val bigint;
i int;
j int;
byte_length int;
binary_string bytea;
BEGIN
IF text_string is null THEN
RETURN null;
ELSIF text_string = '' THEN
RETURN 0;
END IF;
i = 0;
val = 4294967295;
byte_length = bit_length(text_string) / 8;
binary_string = decode(replace(text_string, E'\\', E'\\\\'), 'escape');
LOOP
val = (val # get_byte(binary_string, i))::bigint;
i = i + 1;
j = 0;
LOOP
val = ((val >> 1) # (3988292384 * (val & 1)))::bigint;
j = j + 1;
IF j >= 8 THEN
EXIT;
END IF;
END LOOP;
IF i >= byte_length THEN
EXIT;
END IF;
END LOOP;
RETURN (val # 4294967295);
END
$$ IMMUTABLE LANGUAGE plpgsql;
验证改写后的结果:
select crc32(null),crc32(''),crc32('1');
crc32 | crc32 | crc32
-------+-------+------------
| 0 | 2212294583
(1 row)

